微软提出ARO优化器,通过动态旋转梯度,显著提升大模型训练效率。实验表明,相比AdamW,效率提升约1/3,并揭示了矩阵优化与模型对称性之间的联系。
原文标题:正交化之外是什么?微软等提出ARO优化器:训练提速1/3,揭示矩阵优化新「蓝海」
原文作者:机器之心
冷月清谈:
怜星夜思:
2、论文中提出的“对称性假设”很有意思,大家觉得除了ARO,这个假设还能启发我们设计出哪些新的优化策略?
3、ARO优化器在训练过程中对计算资源的额外开销控制在3%以内,这个比例是如何做到的?对于想要复现或者应用ARO的研究者来说,有哪些工程上的经验可以借鉴?
原文内容

如果你在过去一年关注过大模型训练的技术,大概率听过 Muon 这个名字 —— 这个在月之暗面 K2 模型的相关讨论中走红的优化器,被视为是可能挑战 Adam 的新秀。它的思路很直接:对动量矩阵进行正交化,让各个奇异方向上的更新速率一致,提升训练效率。
Muon 带动了基于正交化算法的改进热潮,但一个根本问题始终较少被讨论:正交化方法,究竟是通往高效训练的必经之路,还是某个更深层原则的一个特例?我们是否能跳出 “正交化” 这个框,找到矩阵优化算法的新 “蓝海”?
微软研究院联合港中文(深圳)、威斯康星大学麦迪逊分校最新放出的长篇论文,从方法论创新、工程验证到理论诠释,给出了肯定的答案。
-
团队首先将现有常用矩阵优化器统一到基于旋转的视角 —— 在旋转后的坐标系中最速下降。
-
论文把 “梯度旋转” 作为第一原则,让旋转策略动态地提升最速下降的速率,推导出一类新的优化器:ARO(自适应旋转优化,Adaptively Rotated Optimization)。Muon 可被视为 ARO 的一个特例。
-
通过严格控制的大规模训练, ARO 将大语言模型的训练效率相对 AdamW 提升了约 1/3(额外时间开销压在 3% 以内),比 Muon 还要高效 10%~15%,且在最多 80 亿参数、多倍过训练的压力测试下,未出现收益递减迹象。
-
最后,论文还进一步探究更深层问题:为什么旋转是本质的?首先,他们通过理论分析,提出了对称性假设 —— 即旋转 / 乃至矩阵优化,本质上可能是利用了大模型架构丰富的对称性;而 ARO 的旋转策略则进一步利用了这种 “红利”,在收敛效率与鲁棒性之间取得了更好的权衡。作者将对称性观点反馈在 ARO 完善上,进一步开发跨层耦合等新特性,取得良好效果。

-
论文标题:ARO: A New Lens On Matrix Optimization For Large Models
-
论文地址:https://arxiv.org/abs/2602.09006
-
作者:Wenbo Gong, Javier Zazo, Qijun Luo, Puqian Wang, James Hensman, Chao Ma
-
机构:微软研究院,香港中文大学(深圳),威斯康星大学麦迪逊分校
旋转:更一般的优化框架
论文指出,如果把 Muon、SOAP、SPlus、Galore 等常见矩阵优化方法进行简化和抽象,它们本质上都是在一个被旋转后的坐标系中,使用 Adam 或者变体进行模型优化。它们先找到一个旋转矩阵 R,把梯度 G 旋转到新的坐标系下;用某个基座优化器 f 计算单步更新量;最后,将该更新量旋转回原来的坐标。这个过程可以写成:
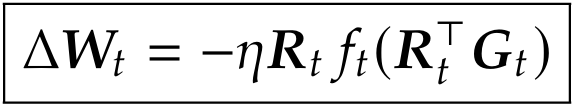
对于旋转 R,上述方法无一例外取为梯度内积矩阵的特征向量 (后文简称为特征旋转)。同时,它们将基座优化器设定为 Adam 或其变体。而 Muon 的正交化,则是使用特定 Adam 变体的一个特例。这表明梯度旋转有潜力成为比正交化更加一般的优化框架。
(后文简称为特征旋转)。同时,它们将基座优化器设定为 Adam 或其变体。而 Muon 的正交化,则是使用特定 Adam 变体的一个特例。这表明梯度旋转有潜力成为比正交化更加一般的优化框架。
ARO 优化器:将梯度旋转作为第一原则
论文提出将旋转最速下降提升到设计优化器的新原则, 从而可以考虑更一般的旋转 R,和更广泛的基座优化器 f。能不能让这两个部分有机地联动起来,去优化一个具体的训练效率指标,例如模型训练损失的下降速度?
论文提出:给定一般的基座优化器 f,我们可以近似地求解旋转 R,使旋转更新下的训练损失下降速率得以提升。于是,我们推导出 ARO 的更新规则:
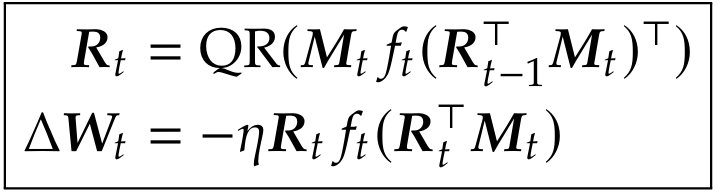
(其中 M 是动量)
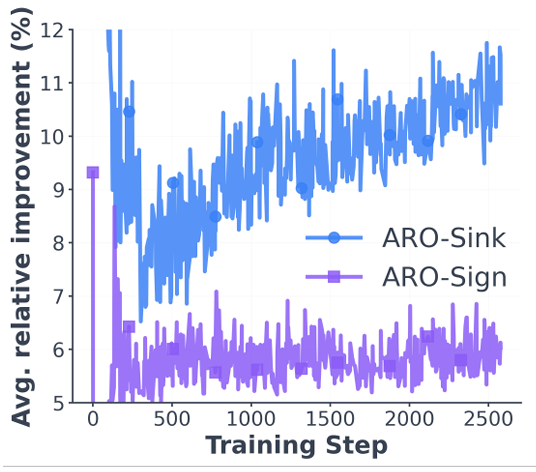
它的直觉很简单:ARO 是在拿上一轮旋转后的基座优化器更新量,寻找新的旋转去大概 “对齐” 原始的梯度动量。换句话说,ARO 在主动地去寻找一个能让当前优化器 f 发挥得更好的旋转角度。实验发现(图 1),用 ARO 的更新方向,比基于传统特征旋转的更新,能带来更优的瞬时损失下降率 —— 该优势在整个训练过程中持续存在。
严格控制的实验准则:为了结论的可靠性,论文给自己加了道槛
优化器评估常面临一个痛点:在研究级场景下所得出的结论,很难迁移到实际场景。原因可能在于基准设置中的一些实验准则未与真实环境对齐,导致指导性有限。
对此,论文规定了一套实验准则:从混合精度选取、学习率衰减、非隐层优化器统一、到学习率迁移策略等环节都进行去偏控制;并尽可能采用大的 batch size(最高 1400 万)、长的序列长度(最高 4K),足够大的模型规模(最高 80 亿)和训练预算(最高 8 倍过训练),尽可能贴近真实训练场景;在可行的情况下对 AdamW 基线进行端到端调参,避免用外推法估算超参。在这种规范下,论文得出的加速率较为温和,但在跨尺度测试下却更加一致、更可迁移。
大规模实验:显著、稳定、一致的效率提升
在以上原则下,评估分为两部分。
-
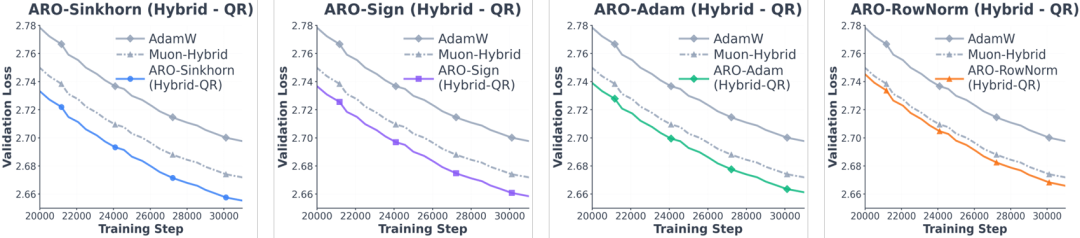
小规模验证(1 亿 - 15 亿参数 GPT)中,ARO 的旋转策略在多种基座优化器下均展现出普适性提升。横向对比无旋转和传统特征旋转版本,以及横向对比 AdamW 和正交化方法,全部表现更优(图 2)。这也侧面说明,梯度旋转是一个非常关键的设计维度。
-
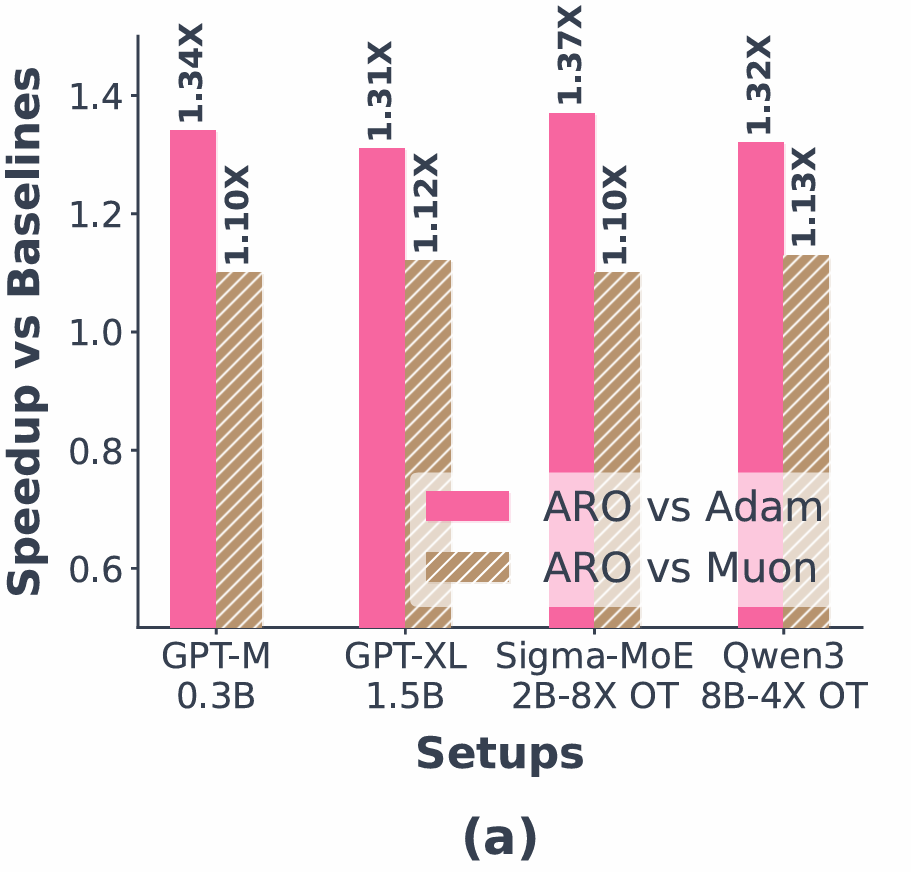
规模化实验将 ARO 推向更大场景:架构覆盖稠密和 MoE,规模从 3 亿延伸至 80 亿激活参数,训练预算拉到 1-8 倍 Chinchilla 过训练。结果显示(图 3),ARO 对 AdamW 保持约 1.3-1.35 倍加速,对 Muon 等正交化方法保持约 1.1-1.15 倍加速,且加速比在更大规模、更长周期下未见衰减。同时,作者通过工程优化使得 ARO 在大规模分布训练下的额外开销相比 AdamW 控制在 3% 以内。
一个有趣的 “副产物”:全模型优化
在主流的矩阵优化器实践策略中,它们通常只用在隐藏层上 ——embedding 和 LM head 等参数还得靠 AdamW 来管。这被称为 “混合 / 分治模式”。其中一个原因是当其被直接用到上述参数上,可能会导致训练显著变差,甚至不收敛。而 ARO 路线下一个新的 “副产物” 是:它可以在全模型参数上跑通。
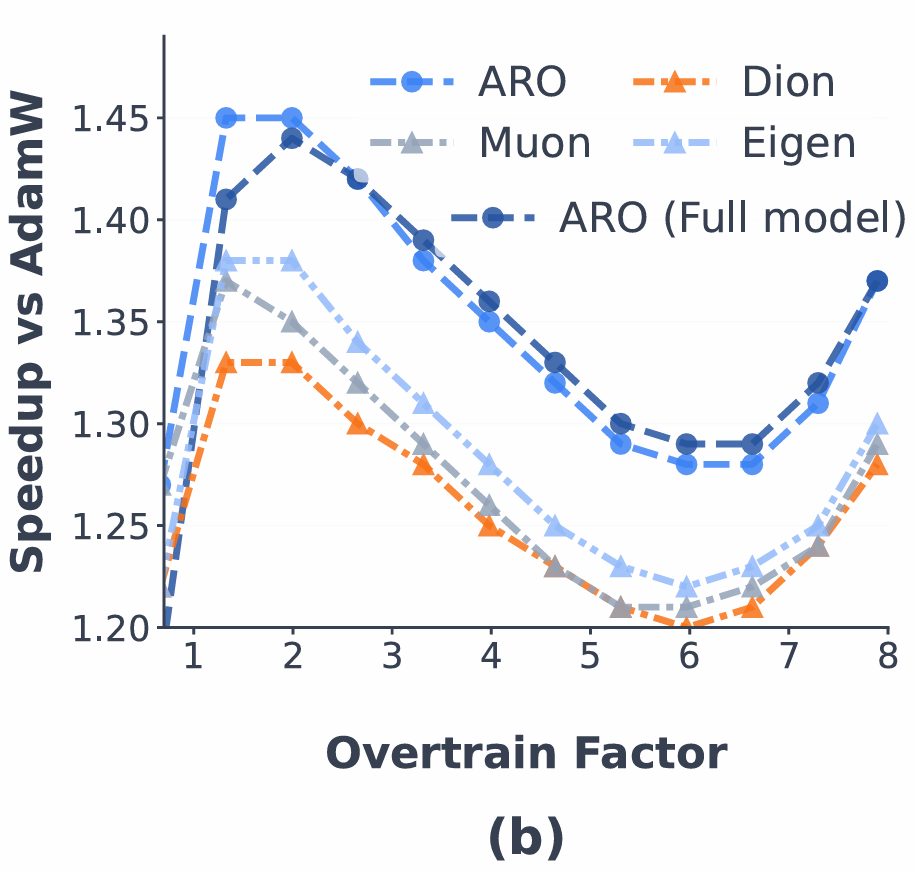
论文在 Sigma-MoE-2B 里对比了几种设置:混合(ARO 只优化隐藏层)、全模型(ARO 优化所有矩阵参数)。结果表明(图 4),全模型模式的 ARO 在训练后期(3 倍 - 4 倍过训练之后)反而比混合模式效果更好。
这意味着 ARO 原则上能够从旋转的角度,统一地处理全模型的矩阵参数 —— 这也一定程度上挑战了当前矩阵优化器较为流行的 “分而治之” 的设计理念。
为什么旋转是本质的?一个更底层的视角:对称性
接下来,论文进一步探究更深层的问题:为什么旋转原则 “恰好” 隐藏在诸多矩阵优化器的设计中?论文的拓展讨论指向了一个概念:神经网络的参数对称性。
微软团队在此前的工作(SliceGPT)中提出过一个定理:Transformer 存在丰富的残差流对称性 —— 在特定约束下将参数同时旋转,模型的输出不变。这意味着参数空间中存在连续区域,其中所有点对应同一函数。
与传统优化器相比,ARO 在这片区域里多了一个可操作的自由度:论文证明,ARO 理论上等价于非欧几何下的对称瞬移(Symmetry Teleportation)—— 一类利用对称性信息加速收敛的经典算法。即,在不改变损失的前提下,ARO 将参数 “瞬移” 到群轨道中另一个更利于优化的位置,再迈出下一步。
论文进一步分析了 ARO 是如何利用这种自由度的。传统对称瞬移追求瞬时收敛速率的最大化,但这在实际当中并不总能取得实际收益。对此,论文主要理论证明了两个结论:1. 随机梯度下大幅提高瞬时速率可能会导致损失下降不稳定;2. 而 Muon/SOAP 等使用的特征旋转则是另一个极端,最大化稳定性但同时会削弱下降速率,取向于保守。ARO 的实现则采取了一种温和的部分提升策略,在提升下降率的同时维持稳定性,在收敛效率与鲁棒性之间取得了更好的权衡。
这个视角下,ARO 不再是单纯的矩阵运算技巧,而是利用架构固有对称性的自然产物。论文将这一观察一般化为 “对称性假设”:已知的矩阵优化器之所以有效,可能是无意中利用了损失景观中的对称性。
通过对称性视角,进一步解锁优化 “新姿势”
对称性视角不仅是对于优化的新诠释,也进一步为 ARO 解锁了 “新姿势”。例如:
-
残差流对称性自然地包含了 embedding 和 lm head—— 二者在对称性的语义下与隐含层并无本质不同。因此,在对称性视角下,ARO 可用于全模型优化上,这与大规模实验中的观测吻合。
-
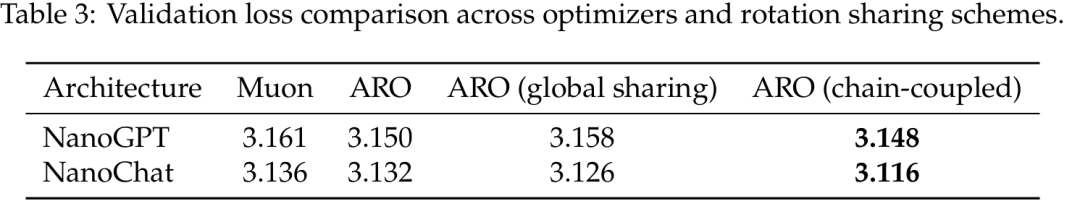
对称性关系揭示了跨层、跨模块之间的耦合约束。例如,受同一段残差流支配的矩阵(如某一层的 QKV 和上一层的输出投影)理当绑定同一个旋转。这提供了一种经济利用跨层相关性的途径 —— 不是通过暴力计算全局二阶矩,而是通过架构自身的耦合关系绑定旋转。在小规模模型上初步验证:跨层绑定旋转不仅能降低计算开销,还显著提升了优化性能。
写在最后
回过头看,ARO 的贡献可以分为三部分:把 “旋转” 从既有优化器的隐含设计里提炼为第一原则;通过严格的规模化实验证明其有效性;用架构本身的全局性质为矩阵优化提供新的诠释,并衍生出新的耦合设计。如果说 Muon 优化器是从 “向量到矩阵的本质跨越”,那么 ARO 则指向一个新的可能:从 “矩阵优化” 走向 “全模型耦合优化”—— 优化器的设计,也许应该和架构绑得更紧一些。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com