字节跳动开源VDA,实现快速稳定的10分钟级长视频深度估计,精度和速度均显著提升!
原文标题:Video Depth Anything来了!字节开源首款10分钟级长视频深度估计模型,性能SOTA
原文作者:机器之心
冷月清谈:
字节跳动开源了Video Depth Anything (VDA),这是一个用于长视频深度估计的模型,解决了单目深度估计在视频中时间一致性差的问题。VDA基于Depth Anything V2,并融合了高效的时空头、精简的时域一致性损失函数,以及基于关键帧的长视频推理策略。
VDA的特点在于:
1. 高精度和稳定性:在多个数据集上取得了SOTA的精度和稳定性,精度提升超过10个百分点。
2. 高效率:推理速度远快于同类模型,是此前最高精度模型的10倍以上,在V100上,较小版本甚至可达30FPS。
3. 支持长视频:可处理长达10分钟的视频。
4. 无需复杂先验知识:无需引入视频生成先验知识。
VDA通过结合图像和视频训练数据,并在头部引入时间注意力机制来提高性能。它采用了一种新的时序梯度匹配损失函数来约束时序一致性,并使用关键帧对齐和重叠区域插值方法来处理任意长度的视频。实验结果表明,VDA在精度、速度和稳定性方面都优于现有的视频深度估计模型。
VDA的特点在于:
1. 高精度和稳定性:在多个数据集上取得了SOTA的精度和稳定性,精度提升超过10个百分点。
2. 高效率:推理速度远快于同类模型,是此前最高精度模型的10倍以上,在V100上,较小版本甚至可达30FPS。
3. 支持长视频:可处理长达10分钟的视频。
4. 无需复杂先验知识:无需引入视频生成先验知识。
VDA通过结合图像和视频训练数据,并在头部引入时间注意力机制来提高性能。它采用了一种新的时序梯度匹配损失函数来约束时序一致性,并使用关键帧对齐和重叠区域插值方法来处理任意长度的视频。实验结果表明,VDA在精度、速度和稳定性方面都优于现有的视频深度估计模型。
怜星夜思:
1、VDA模型虽然速度很快,但是对于一些高精度要求的场景,比如自动驾驶,它的精度是否足够?
2、VDA模型提到的无需引入复杂的视频生成先验知识,具体是指什么?这对模型的训练和应用有什么好处?
3、VDA模型是如何处理长视频的?它的关键帧策略有什么优势?
2、VDA模型提到的无需引入复杂的视频生成先验知识,具体是指什么?这对模型的训练和应用有什么好处?
3、VDA模型是如何处理长视频的?它的关键帧策略有什么优势?
原文内容
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
Video Depth Anything 工作来自字节跳动智能创作 AR 团队与豆包大模型团队。字节跳动智能创作 AR 团队致力于建设领先的计算机视觉、音视频编辑、特效处理、3D 视觉与增强现实(AR)等技术。豆包大模型团队成立于 2023 年,致力于开发先进的 AI 大模型技术,成为业界一流的研究团队。
单目深度估计模型,可根据二维 RGB 图像估计每个像素点的深度信息,在增强现实、3D 重建、自动驾驶领域应用广泛。作为此领域的代表性成果,在 Github 已总计收获 11.6k Stars,应用范围之广、受欢迎程度之高也可见一斑。
但时间一致性问题限制了单目深度估计模型在视频领域的实际应用。如何构建一个又准又稳又快的长视频深度模型,成为单目深度估计进一步扩大应用范围的关键。
近期,字节智能创作 AR 团队联合豆包大模型团队开发的 Video Depth Anything(VDA) 成功解决这一难题。
VDA 基于 Depth Anything V2,它融合了高效的时空头、精简的时域一致性损失函数,以及新颖的基于关键帧长视频推理策略,甚至可面向 10 分钟级的视频,完成深度估计任务。
在不牺牲泛化能力、细节生成能力和计算效率前提下,VDA 实现了时序稳定的深度估计,且无需引入复杂视频生成先验知识,为单目深度估计在视频领域应用提供全新解决方案。
实验结果表明,VDA 在视频数据集的精度和稳定性指标均取得 SOTA,尤其精度提升超过 10 个百分点,且推理速度均远快于此前同类模型,其速度是此前最高精度模型的 10 倍以上。在 V100 下,较小版本 VDA 模型推理速度甚至可达 30FPS(每秒 30 帧)。

目前,该论文成果和代码仓库均已对外公开,项目上线数天已收获 300+ Stars,X 原贴阅读量也超过 2 万,另有多个转发阅读量超 1 万,包括 Gradio 官号。


-
论文链接:https://arxiv.org/abs/2501.12375
-
项目主页:https://videodepthanything.github.io/
-
代码仓库:https://github.com/DepthAnything/Video-Depth-Anything
视频深度估计的挑战
近年来单目深度估计(MDE)取得显著进展。以 Depth Anything V2 为例,该模型在多种场景下均能展现强泛化能力,可生成细节丰富的深度预测结果,同时,具备较高的计算效率。
然而,该系列模型存在一定局限。
具体来说,模型主要针对静态图像设计,用于视频场景时,很容易因画面剧烈变化和运动模糊等因素,造成深度预测准确性和稳定性下降。
在一些对时间一致性要求较高的应用领域,如机器人、增强现实以及高级视频编辑等,严重制约了模型的应用。
近期有一些方法如 DepthCrafter、Depth Any Video,将预训练视频扩散模型( Video Diffusion Models)应用于视频深度估计。
尽管它们在生成细节方面表现良好,但计算效率较低,无法充分利用现有深度基础模型,精度也有待提升,处理视频长度还存在限制,难以满足实际应用中对长视频的处理需求。
VDA 模型设计:兼顾预测精度与效率
-
从单图深度模型到视频深度模型
VDA 使用训好的 Depth Anything V2 模型作为编码器,并在训练过程中,固定编码器参数,降低训练成本并保留已学习到的特征。
VDA 设计了一个轻量级时空头(Spatio-Temporal Head,STH),包含四个时间注意力层,这些层在每个空间位置上独立进行时间维度信息融合。
值得注意的是,VDA 仅在头部引入时间注意力机制,同时引入图像和视频训练,避免在有限视频数据上训练,破坏原有模型特征。

-
时空一致性约束
为了约束时序一致性,并去除以往视频深度模型训练过程中对光流信息的依赖,VDA 提出时序梯度匹配损失(Temporal Gradient Matching Loss)。
具体来说,不再从光流中获得对应点,直接使用相邻帧中相同坐标深度来计算损失,假设相邻帧中相同图像位置的深度变化应与真实值变化一致,类似于计算时间维度上的梯度:

-
超长视频推理策略
为了处理任意视频长度,VDA 提出关键帧对齐和重叠区域插值方法,以对齐全局尺度和偏移,并确保局部窗口之间的平滑推理。
用于推理的后续视频片段由未来帧、重叠帧和关键帧组成,其中,关键帧从之前的帧中子采样得到。
这种方法将早期窗口内容引入当前窗口,保持计算负担最小,可显著减少累积的尺度漂移,尤其利于长视频处理。

实验结果:
VDA 精度、速度、稳定性均刷新 SOTA
VDA 在 6 个包含室内外场景的 Benchmark 上,从几何精度、时序稳定性、耗时三个方面和学界 SOTA 方案进行对比。
其中,长视频 Benchmark 精度和时序稳定性误差均为最优。其中,VDA-L 在多项评估指标上面获得最佳,VDA-S 的效果次之,双双大幅优于 DepthCrafter 和 DAv2-L。

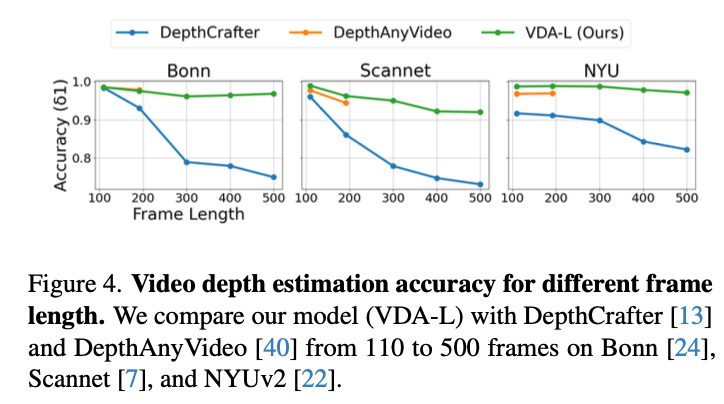
研究者还发现,随着视频长度增长,VDA 比对 DepthCrafter 和 DepthAnyVideo 指标没有明显下降,这也是它在超长视频上实现稳定深度估计的有力证明。
最后,团队实验还证明了 VDA 模型耗时远小于其他视频深度模型,即使相比单帧模型 Depth Anything V2,耗时也只增加约 10%。尤其 DVA-S 模型,单帧推理时间仅 9.1ms,面向实时性要求较高的场景,具有较大应用潜力。

更多实验配置和测试细节请移步完整论文(https://arxiv.org/abs/2501.12375)
相关工作 Prompt Depth Anything 也已开源
除了视频深度模型外,豆包大模型团队于近期同浙江大学合作开源了 Prompt Depth Anything 技术,实现了 4K 分辨率下的高精绝对深度估计(Metric Depth),一作豆包大模型团队实习生同学。
绝对深度估计,指依靠模型,预测场景中每个像素点到摄像机的真实物理距离(以米、毫米等物理单位表示)。相比当前百花齐放的基础深度估计模型(如 Depth Anything V1&V2、Margold 等),绝对深度估计仍面临巨大挑战。
面向该问题,豆包大模型团队与浙江大学联合团队受语言 / 视觉基础模型中提示词机制启发,创新性地提出了深度估计基础模型的提示机制 ——
通过以 iPhone LiDAR 传感器采集的 24x24 绝对深度作为提示,促使模型最多可输出 3840x2160 同精度级别的绝对深度。该方法具有普适性,可应用于任意形式的提示内容,比如车载 LiDAR、双目匹配深度、相机内参等。
团队认为,该成果具备广泛的下游应用空间,比如 3D 重建:
自动驾驶:
机器人抓取任务等:
该项目现已开源,更多方法介绍以及实验结果见论文主页(https://promptda.github.io/)。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com