字节跳动推出智能论文检索Agent PaSa,两分钟完成论文调研,性能远超Google Scholar、ChatGPT等主流工具。
原文标题:2分钟完成论文调研!ByteDance Research推出论文检索智能体PaSa,远超主流检索工具
原文作者:机器之心
冷月清谈:
字节跳动研究团队最新推出了一款名为PaSa的智能论文检索工具,该工具基于强化学习,能够模拟人类研究者的调研过程,包括使用搜索引擎、阅读论文和追踪参考文献等。用户只需提出研究问题,PaSa即可在两分钟内完成详尽的学术调研,并提供相关的学术论文。
PaSa的核心组件是两个LLM Agents:Crawler和Selector。Crawler负责自主收集与用户查询相关的论文,而Selector负责评估论文是否符合用户需求。
与Google、Google Scholar、ChatGPT等主流检索工具相比,PaSa在召回率和准确率方面均有显著提升。在AutoScholarQuery和RealScholarQuery两个数据集上的测试结果表明,PaSa-7b的性能优于所有基线模型,尤其是在RealScholarQuery数据集上,PaSa-7b的召回率提升了30.36%,准确率提升了4.25%。
为了训练PaSa,研究团队构建了一个高质量的学术细粒度查询数据集AutoScholarQuery,并提出了一种session-level PPO算法来解决Crawler行动轨迹过长的问题。PaSa目前已开放试用,并开源了全部数据、代码和模型。
PaSa的核心组件是两个LLM Agents:Crawler和Selector。Crawler负责自主收集与用户查询相关的论文,而Selector负责评估论文是否符合用户需求。
与Google、Google Scholar、ChatGPT等主流检索工具相比,PaSa在召回率和准确率方面均有显著提升。在AutoScholarQuery和RealScholarQuery两个数据集上的测试结果表明,PaSa-7b的性能优于所有基线模型,尤其是在RealScholarQuery数据集上,PaSa-7b的召回率提升了30.36%,准确率提升了4.25%。
为了训练PaSa,研究团队构建了一个高质量的学术细粒度查询数据集AutoScholarQuery,并提出了一种session-level PPO算法来解决Crawler行动轨迹过长的问题。PaSa目前已开放试用,并开源了全部数据、代码和模型。
怜星夜思:
1、PaSa 的出现会对现有的论文检索平台和学术搜索引擎造成什么样的冲击?
2、PaSa 宣称两分钟完成论文调研,这个速度在实际使用中是否真的能达到?会受到哪些因素的影响?
3、PaSa 开源了代码和模型,这对于学术界和产业界有什么意义?
2、PaSa 宣称两分钟完成论文调研,这个速度在实际使用中是否真的能达到?会受到哪些因素的影响?
3、PaSa 开源了代码和模型,这对于学术界和产业界有什么意义?
原文内容
机器之心发布
机器之心编辑部
2025 被称为 Agent 元年,新年伊始,ByteDance Research 就推出了一款基于强化学习的智能体应用:论文检索智能体。它可以模仿人类研究者调用搜索引擎、看论文、查参考文献。繁琐冗长的论文调研,现在,只需要两分钟。
从事科研工作的你,想要一个帮你尽调论文的科研小助手吗?

你是否曾为了寻找某个研究主题的相关论文,花费了大量的时间与精力;或者对某个研究想法充满兴趣,却不确定是否已有类似的研究,最终耗费了大量时间在调研上?最近,ByteDance Research 的研究团队推出了一款强大的学术论文检索工具 ——PaSa。用户只需提出关注的学术问题,PaSa 即可自动调用搜索引擎,浏览相关论文并追踪引文网络,精准、全面地为用户呈现所有相关的学术论文,只需要两分钟,就可以完成一次详尽的学术调研。
先来看看 PaSa 的效果:
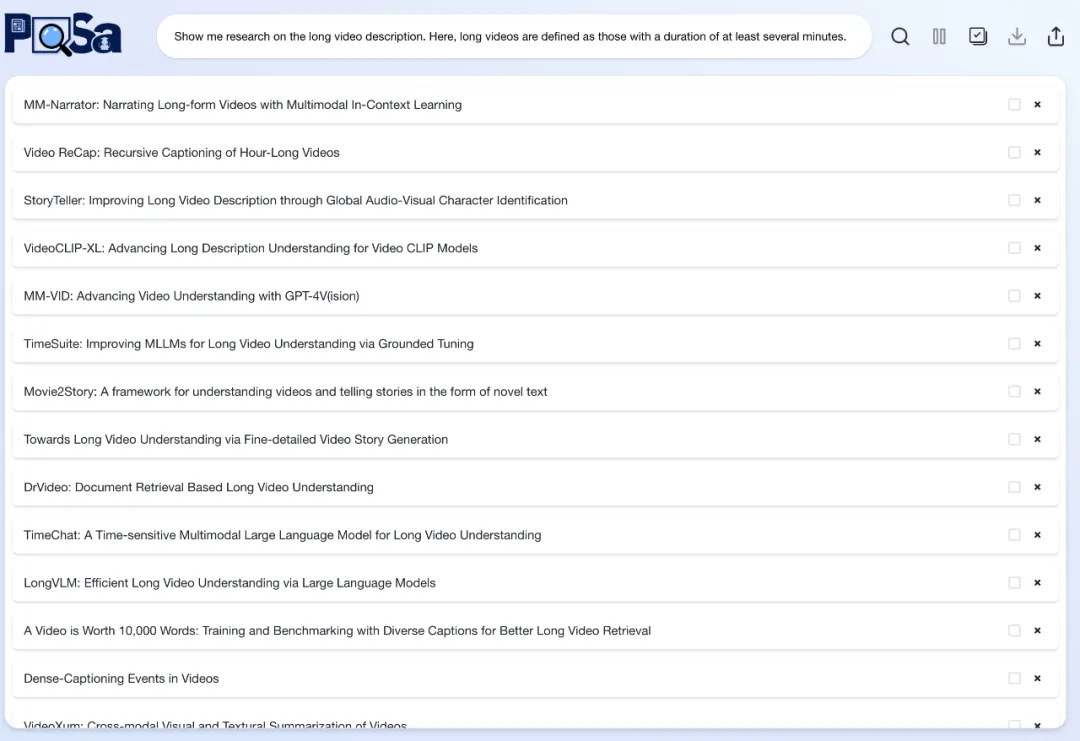
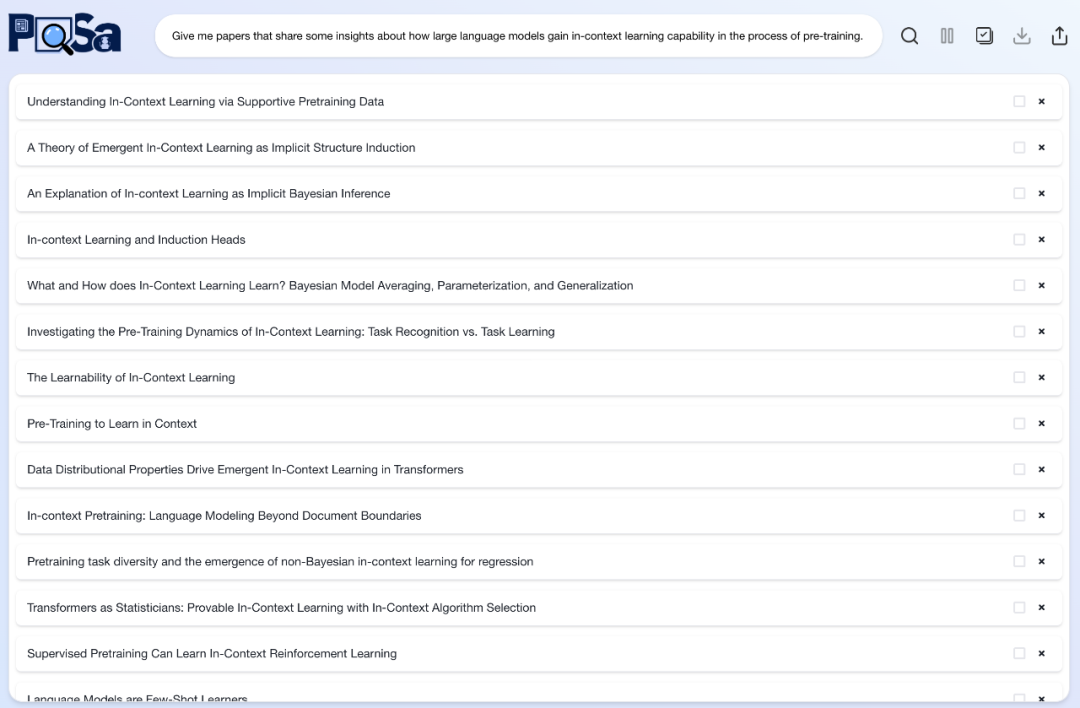
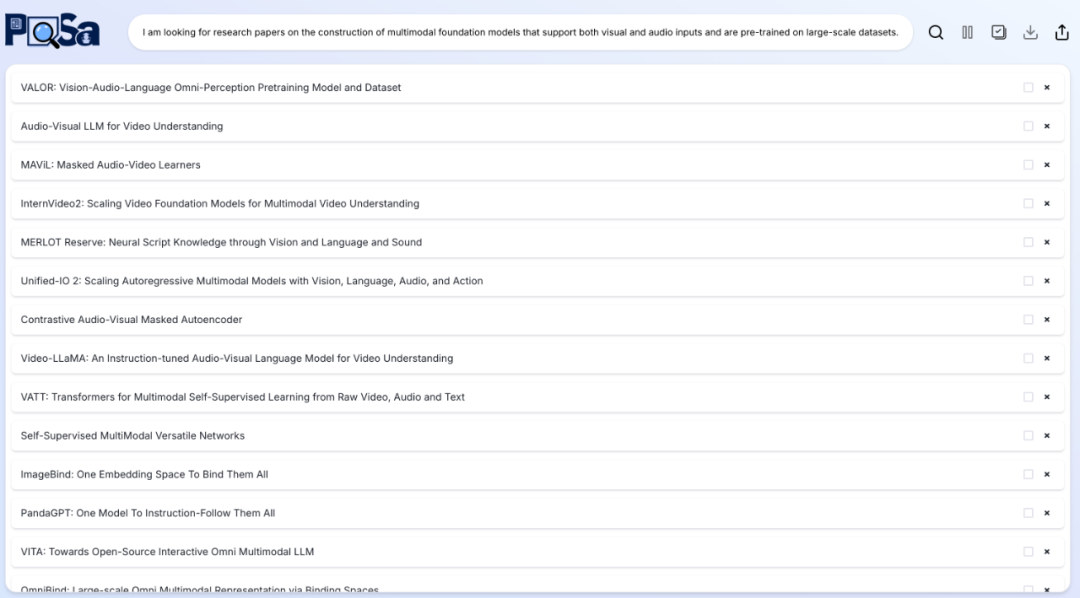
研究人员将 PaSa 与一系列主流检索工具进行了对比,包括 Google, Google Scholar, Google+GPT-4o, ChatGPT(配备检索能力的 GPT-4o), GPT-o1 以及 PaSa-GPT-4o。在学术 Query 测试集上,PaSa 大幅超越了当前主流检索工具:与 Google 相比,PaSa-7b 在 Recall@20 和 Recall@50 上分别提升了 37.78% 和 39.90%。与基于 Prompt Engineering 实现的 PaSa-GPT-4o 相比,经过强化学习训练的 PaSa-7b 在召回率上提升了 30.36%,准确率上提升了 4.25%.。
PaSa 目前已开放试用。同时,研究团队公开了详尽的技术论文,并一次性开源了全部的数据、代码和模型:

-
论文地址:https://arxiv.org/abs/2501.10120
-
项目仓库:https://github.com/bytedance/pasa
-
PaSa 主页:https://pasa-agent.ai
PaSa Agent 框架
PaSa 的核心组件包含两个 LLM Agents:Crawler 和 Selector。Crawler 通过自主调用搜索工具、阅读论文、扩展参考文献,不断收集与用户 Query 可能相关的学术论文。Selector 则负责精读 Crawler 找到的每一篇论文,决定其是否满足用户的需求。
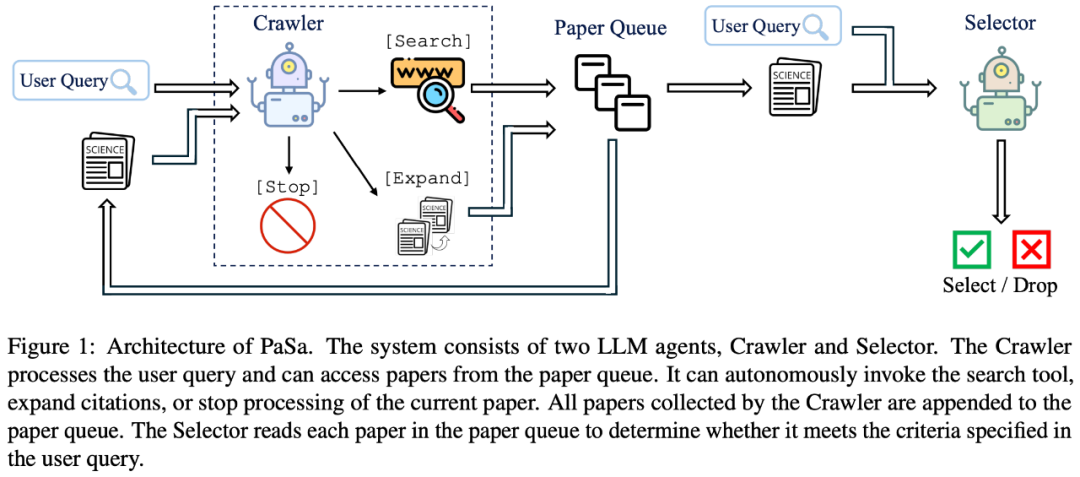
PaSa 框架:Crawler 的设计旨在最大化相关论文的召回率,而 Selector 则强调精确性,即识别论文是否符合用户需求。
下图展示了一个 PaSa 处理 User Query 的具体流程:
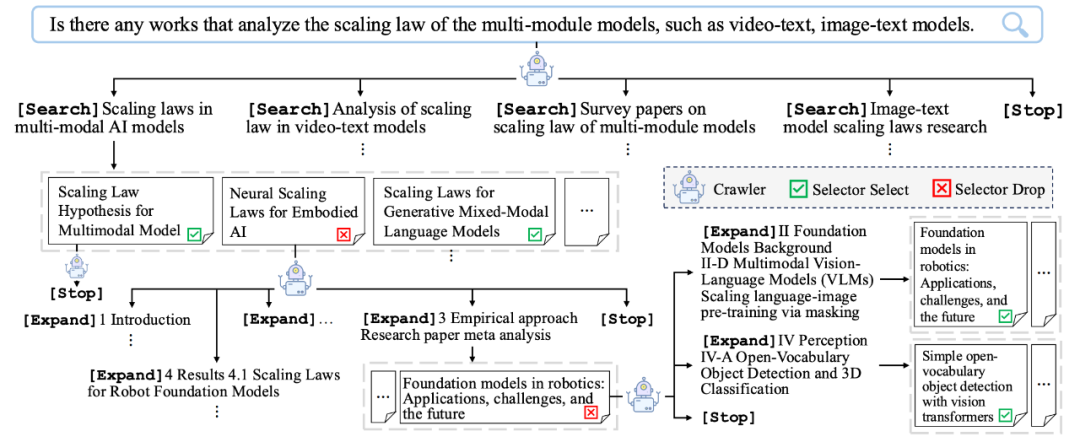
PaSa 的工作流示例:Crawler 可以生成多样、互补的搜索词执行多次搜索。此外,Crawler 还能够评估其行为的长期价值,例如在多步扩展引文网络后,Cralwer 能够发现许多与用户 Query 相关的论文,即使路径中的中间论文并不直接与用户需求匹配。
训练优化
为了训练 PaSa,研究团队首先构造了一个高质量的学术细粒度 Query 数据集:AutoScholarQuery。该数据集通过收集人工智能领域顶会(ICLR 2023,ICML 2023,NeurIPS 2023,ACL 2024,CVPR 2024)发表的论文,基于每篇论文中 “Related Work” 部分的描述及其引用的相关文献,生成学术问题和对应的相关论文列表。最终,数据集包含了 36k 数据,每条数据包含一个 AI 领域的学术问题及相关论文,示例如下图所示。

AutoScholarQuery 中的数据示例
尽管 AutoScholarQuery 缺乏人类科学家发现论文的轨迹数据,但该数据集仍然能够支持对 PaSa 智能体进行强化学习训练。在 Crawler 的训练过程中,面临两个主要挑战:奖励稀疏性和过长的行动轨迹。为了解决奖励稀疏性问题,研究团队引入了 Selector 作为辅助奖励模型,显著提升了优化效果。此外,Crawler 在一次执行中可能收集到上百篇文章,导致完整的行动轨迹过长,无法完全输入到 LLM 的上下文中。为此,团队提出了一种全新的 session-level PPO 算法,解决这一问题。
Selector 主要通过模仿学习进行训练。Selector 会先生成一个 Decision Token,决定论文是否符合用户 Query 的需要。同时 Token Probability 也可以作为相关性分数用于最终结果的排序。在 Decision Token 后,Selector 还会输出决策依据。
Crawler 和 Selector 的更多训练细节详见论文。
实验结果
为了验证 PaSa 在真实学术搜索场景中的表现,研究团队开发了一个评测集 ——RealScholarQuery。该数据集包含了 AI 研究者提出的真实学术问题,并为每个问题人工构建了对应的相关论文列表。研究团队在 AutoScholarQuery-test 和 RealScholarQuery 两个评测集上,全面对比了 PaSa 与 baselines 的表现。
Baselines
-
Google:直接用 Google 搜索用户问题
-
Google Scholar:直接用 Google Scholar 搜索用户问题
-
Google with GPT-4o:首先 prompt GPT-4o 改写用户问题生成一个更适于 Google 搜索的问题,然后使用 Google 进行搜索
-
ChatGPT:上传用户问题给有搜索功能的 GPT-4o,并收集它的生成结果
-
GPT-o1:直接 prompt GPT-o1 来处理用户问题
-
PaSa-GPT-4o:通过 prompt GPT-4o 模拟 Crawler 和 Selector,构成 PaSa 架构 agent
PaSa
-
PaSa-7b:使用 Qwen2.5-7b-Instruct 作为基础模型,通过特殊奖励构造的强化学习训练的 Crawler 和 Selector 构成的 agent
-
PaSa-7b-ensemble:集成多次 Crawler 的搜索结果,提高最终的召回量
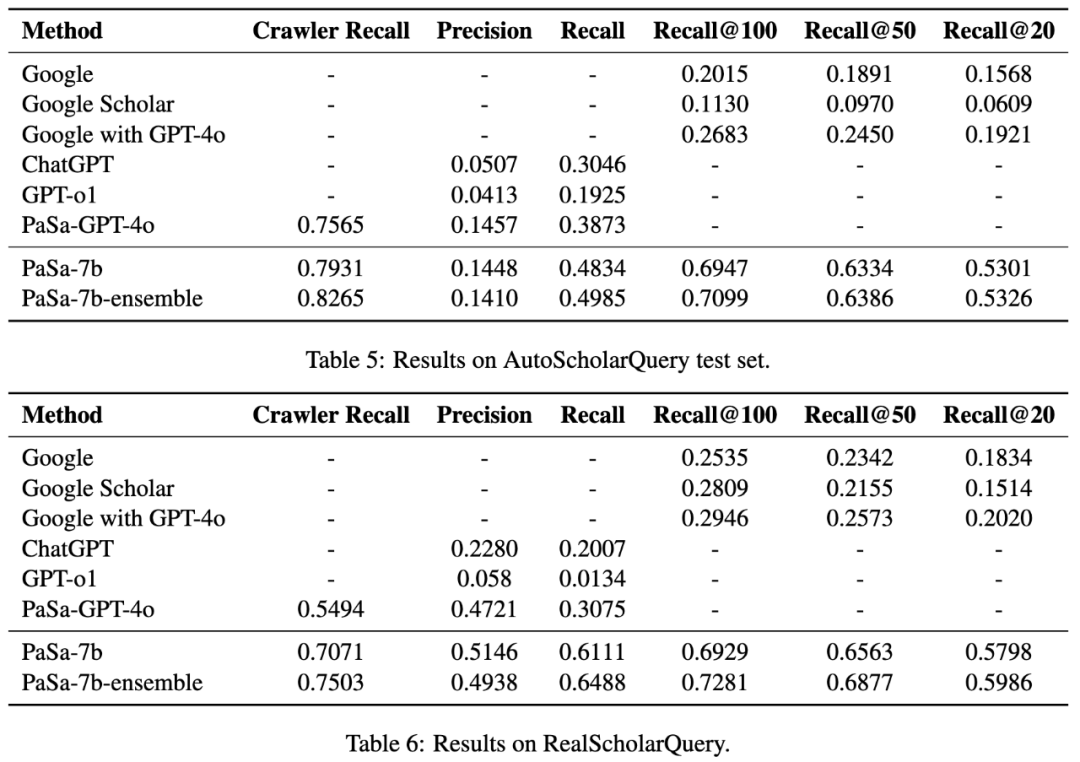
在 AutoScholarQuery 测试集上,PaSa-7b 的效果优于其他所有的基线模型。与最强的基线 PaSa-GPT-4o 相比,在准确率相当的情况下,PaSa-7b 的召回率提高了 9.64%,Crawler 召回率提高了 3.66%。和 Google 搜索的最好结果相比,Recall@20,Recall@50 和 Recall@100 分别提升了 33.80%,38.83% 和 42.64%。此外,集成后的 PaSa-7b-ensemble 比 PaSa-7b 的召回率和 Crawler 召回率能进一步提高 1.51% 和 3.44%。
在更接近真实的 RealScholarQuery 上,PaSa-7b 的提升更加明显。与 PaSa-GPT-4o 相比,PaSa-7b 的召回率提高了 30.36%,精确率提高了 4.25%。Google 搜索的最好结果相比,Recall@20,Recall@50 和 Recall@100 分别提升了 37.78%,39.90% 和 39.83%。PaSa-7b-ensemble 的召回率和 Crawler 召回率分别进一步提高了 3.52% 和 4.32%。
结语
学术搜索是一个具有独特挑战的信息检索场景:涉及大量专业性较强的长尾知识,要求全面的召回能力,并能够支持细粒度的查询。PaSa 是基于大语言模型的全新论文检索智能体,通过模仿人类的搜索工具调用、论文阅读以及参考文献查阅过程,能够自主高效地完成论文调研这一复杂的工作。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com