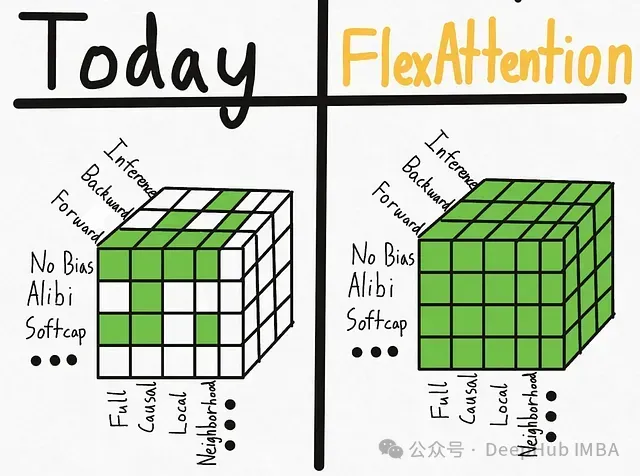
利用PyTorch FlexAttention实现因果注意力和变长序列填充处理,提高Transformer模型效率。
原文标题:PyTorch FlexAttention技术实践:基于BlockMask实现因果注意力与变长序列处理
原文作者:数据派THU
冷月清谈:
接下来,文章解释了如何实现因果掩码和填充掩码。因果掩码确保注意力计算只关注当前和之前的 token,而填充掩码则用于处理变长序列中的填充部分,忽略填充 token 的影响。文章提供了创建这两种掩码的代码示例,并详细解释了其工作原理。
最后,文章演示了如何组合因果掩码和填充掩码,并将其应用于 MultiheadFlexAttention。通过使用 and_masks 函数和 create_block_mask 函数,可以生成一个统一的 BlockMask。文章还提供了实验设置、数据准备和可视化结果,以验证实现的正确性。可视化结果清晰地展示了填充 token 和未来 token 的注意力权重都被屏蔽。
怜星夜思:
2、文章中提到的 _compile 参数对性能提升有多大?在哪些情况下使用 _compile 参数效果更明显?
3、FlexAttention 相比于传统的注意力机制,除了灵活的掩码功能外,还有哪些优势?
原文内容

来源:DeepHub IMBA本文约2000字,建议阅读5分钟
本文介绍了如何利用torch 2.5及以上版本中新引入的FlexAttention和BlockMask功能来实现因果注意力机制与填充输入的处理。
鉴于目前网络上缺乏关于FlexAttention处理填充输入序列的完整代码示例和技术讨论,本文将详细阐述一种实现方法,该方法同时涵盖了因果注意力机制的实现。
本文不会详细讨论FlexAttention的理论基础,如需了解更多技术细节,建议参考PyTorch官方博客。
环境配置
git clone https://github.com/pytorch-labs/attention-gym.git
cd attention-gym
pip install .
cd ../
我们通过attention-gym仓库进行安装,这样可以确保组件间的兼容性,同时获取其可视化工具的使用权限。
MultiheadFlexAttention实现
为了在transformer架构中有效地使用flex_attention,需要在多头注意力模块中进行实现。
class MultiheadFlexAttention(nn.Module): def __init__(self, d_in, d_out, n_heads, bias=False): """ 描述:实现基于flex_attention的多头自注意力机制的PyTorch模块 参数: d_in: int, 输入张量维度 d_out: int, 输出张量维度 n_heads: int, 注意力头数 bias: bool, 是否在query、key和value计算中使用偏置项 """ super().__init__() assert d_out % n_heads == 0, "d_out must be divisible by n_heads"self.n_heads = n_heads
self.d_head = d_out // n_heads
self.d_out = d_out
self.in_proj = nn.Linear(d_in, 3 * d_out, bias=bias)
self.out_proj = nn.Linear(d_out, d_out)
此处定义了模型的核心参数,包括输入输出维度及线性变换层。
def forward(self, x, block_mask): """ 描述:多头自注意力模块的前向计算过程 参数: x: torch.Tensor, 输入张量,维度为(batch_size, max_seq_len, d_in) block_mask: torch.Tensor, flex_attention使用的块状掩码 """ batch_size, max_seq_len, d_in = x.shape通过线性变换生成query、key、value的组合表示
qkv = self.in_proj(x)
将qkv分解并重组为多头形式
qkv = qkv.view(batch_size, max_seq_len, 3, self.n_heads, self.d_head)
调整张量维度以适配flex_attention的输入要求
qkv = qkv.permute(2, 0, 3, 1, 4)
解析得到query、key、value张量
queries, keys, values = qkv
利用flex_attention计算注意力权重
attn = flex_attention(queries, keys, values, block_mask=block_mask)
合并多头注意力的输出
attn = attn.transpose(1, 2).contiguous().view(batch_size, max_seq_len, self.d_out)
执行输出映射
attn = self.out_proj(attn)
return attn, queries, keys
该前向传播函数的实现与PyTorch标准的MultiheadAttention类相似,主要区别在于引入了block_mask参数并采用flex_attention函数进行注意力计算。
mask_mod函数实现
FlexAttention的核心优势在于能够高效地实现和使用自定义注意力掩码,而无需编写特定的CUDA核心代码。
要使用此功能,需要将掩码定义为布尔类型张量。首先实现一个因果掩码,这是FlexAttention开发者在其官方博客中提供的基础示例。
因果掩码
def causal(b, h, q_idx, kv_idx):
return q_idx >= kv_idx
这里的参数说明:
-
b:批次大小
-
h:注意力头数
-
q_idx:query位置索引
-
kv_idx:key/value位置索引
例如,对于序列长度为5的输入,q_idx表示为torch.Tensor([0,1,2,3,4])。
q_idx >= kv_idx返回一个因果布尔掩码,确保注意力计算只考虑当前位置及其之前的token。
接下来将实现填充掩码来处理变长序列的填充部分。
填充掩码实现
填充掩码与因果掩码的主要区别在于其批次依赖性,即掩码值取决于每个序列中填充token的具体位置。实现时需要通过填充标记表来识别序列中应被忽略的填充token。
def create_padding_mask(pads):
def padding(b, h, q_idx, kv_idx):
return ~pads[b, q_idx] & ~pads[b, kv_idx]
return padding
pads是一个形状为(batch_size, max_seq_len)的布尔张量,填充位置标记为True,有效token位置标记为False。此padding mask_mod函数生成填充掩码,仅当query和key/value位置均为非填充token时才允许注意力计算。
实验设置与数据准备
在组合掩码并应用到MultiheadFlexAttention之前,需要先设置相关参数并准备实验数据。
# 多头注意力参数配置 d_in = 64 d_out = 64 n_heads = 8初始化多头注意力模块
mhfa = MultiheadFlexAttention(d_in, d_out, n_heads).to(device)
数据维度设置
batch_size = 1 # 支持任意批次大小
max_seq_len = 10生成随机输入数据
input_data = torch.randn(batch_size, max_seq_len, d_in).to(device)
接下来,对input_data进行修改,添加随机的末尾零填充。添加随机零填充
pad = torch.zeros(1, d_in).to(device)
pad_idxs = [(b, range(torch.randint(max_seq_len//2, max_seq_len + 1, (1,)).item(), max_seq_len)) for b in range(batch_size)]
for b, idxs in pad_idxs:
input_data[b, idxs] = pad
现在需要为padding mask_mod函数构建填充标记表。
# 构建填充标记掩码
collapsed_input = input_data[:, :, 0] # (batch_size, max_seq_len)
pads = torch.eq(collapsed_input, 0).to(device)
注意,mask_mod函数不需要考虑input_data的嵌入维度,因此在创建填充标记表(pads)时可以将该维度压缩。
组合因果掩码和填充掩码
此时我们已具备创建综合注意力掩码所需的全部组件。
# 构建组合掩码
causal_mask = causal
padding_mask = create_padding_mask(pads)
masks = [causal, padding_mask]
combined_mask = and_masks(*masks)
causal_padding_mask = create_block_mask(combined_mask, B=batch_size, H=None, Q_LEN=max_seq_len, KV_LEN=max_seq_len, _compile=True)
在这里,我们通过torch.flex_attention提供的and_masks函数将causal和padding mask_mod函数进行组合,从而生成统一的BlockMask。
说明:开发团队建议启用 _compile_ 参数可显著提升BlockMasks的生成效率,这对于批次相关的掩码处理尤其重要。
现在可以利用MultiheadFlexAttention类对input_data执行注意力计算,同时应用编译后的自定义注意力掩码。
# 执行前向计算
attn_output, query, key = mhfa(input_data, causal_padding_mask)
使用attention-gym提供的可视化工具来分析注意力分布。
# 可视化第一个序列的注意力分布
visualize_attention_scores(
query,
key,
mask_mod=combined_mask,
device=device,
name="causal_padding_mask",
path=Path("./causal_padding_mask.png"),
)
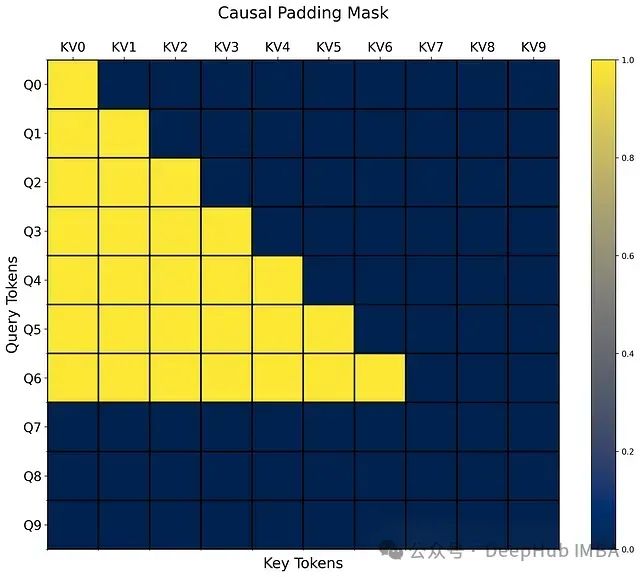
上图展示了包含三个填充token的序列的掩码后因果注意力分布。
从可视化结果可以观察到,填充token和未来token的注意力权重都被有效地屏蔽,验证了实现的正确性。
