谷歌Gemini 2.0 Flash Thinking升级版上下文扩展至1M,重登Chatbot Arena榜首,多模态能力再提升,并探索3D数据应用。
原文标题:1M长上下文,满血版Gemini 2.0又一次登上Chatbot Arena榜首
原文作者:机器之心
冷月清谈:
谷歌发布了 Gemini 2.0 Flash Thinking 的升级版本,其上下文窗口长度扩展至 1M,再次登顶 Chatbot Arena 排行榜。该模型强调推理能力,并能在多轮对话中自我纠错。升级版模型在数学、科学和多模态推理能力方面都有显著提升,尤其在数学能力测试中提升了 54%。谷歌表示,该模型的长上下文能力并非简单的信息堆积,而是能够连贯地运用积累的信息完成任务。除了文本能力的提升,Gemini 2.0 还展示了强大的多模态理解能力,能够根据语音提示操作网页元素,并融合语音、视觉和动作信息。谷歌透露,他们正在探索 3D 数据的应用,并已取得初步成果。目前,Gemini 系列模型的交互界面整合在 Google AI Studio 中,提供 API 密钥获取、提示词创建、实时对话、APP 开发等功能,但界面和文档仍有待完善。谷歌强调,他们的目标是打造全面均衡的通用模型,而非在特定领域表现突出。
怜星夜思:
1、100万token的上下文长度是什么概念?对实际应用有什么影响?
2、Gemini 2.0 Flash Thinking 的“思维过程展示”功能,除了提升用户理解外,还有什么意义?
3、谷歌强调“全面均衡”的模型发展理念,这与其他厂商的策略有何不同?这种策略的优劣势是什么?
2、Gemini 2.0 Flash Thinking 的“思维过程展示”功能,除了提升用户理解外,还有什么意义?
3、谷歌强调“全面均衡”的模型发展理念,这与其他厂商的策略有何不同?这种策略的优劣势是什么?
原文内容
机器之心报道
编辑:佳琪、蛋酱
就在国内各家大模型厂商趁年底疯狂卷的时候,太平洋的另一端也没闲着。
就在今天,谷歌发布了 Gemini 2.0 Flash Thinking 推理模型的加强版,并再次登顶 Chatbot Arena 排行榜。

谷歌 AI 掌门人 Jeff Dean 亲发贺信:「我们在此实验性更新中引入了 1M 长的上下文,以便对长篇文本(如多篇研究论文或大量数据集)进行更深入的分析。经过不断迭代,提高可靠性,减少模型思想和最终答案之间的矛盾。」
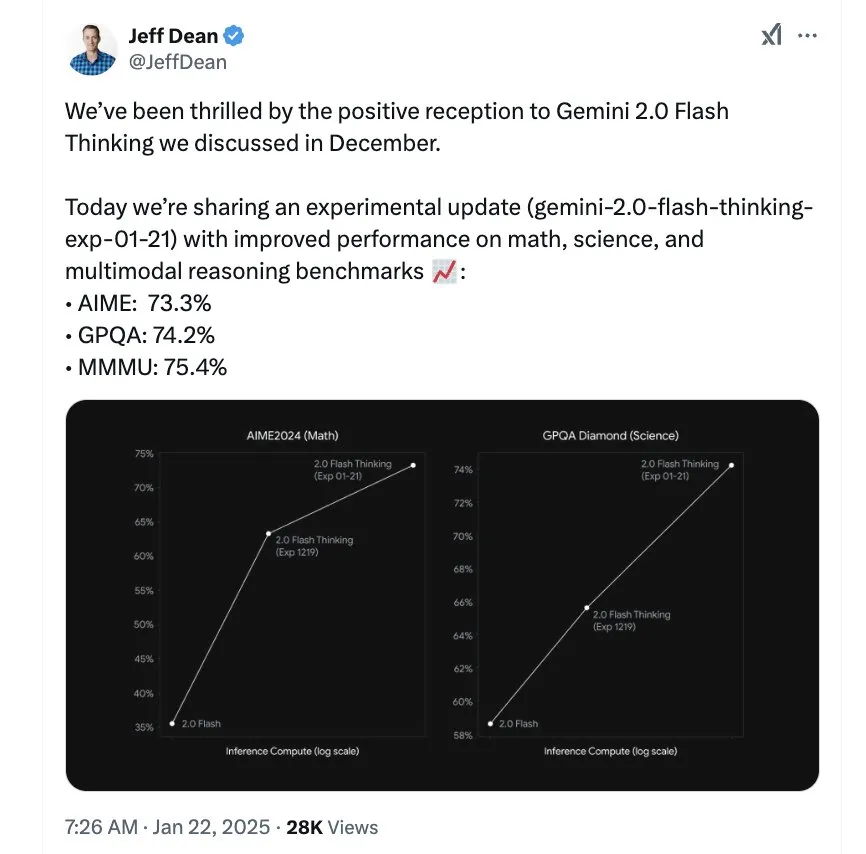
试用链接:https://aistudio.google.com/prompts/new_chat
让我们回忆一下:2024 年 12 月 20 日,横空出世的 ,曾让 OpenAI 的十二连发黯然失色。
Gemini 2.0 Flash Thinking 基于 Gemini 2.0 Flash,只是其经过专门训练,可使用思维(thoughts)来增强其推理能力。发布之初,这款大模型就登顶了 Chatbot Arena 排行榜。
在技术上,Gemini 2.0 Flash Thinking 主要有两点突破:可处理高达 1M token 的长上下文理解;能在多轮对话和推理中自我纠错。
Gemini 2.0 Flash Thinking 的一大亮点是会明确展示其思考过程。比如在 Jeff Dean 当时展示的一个 demo 中,模型解答了一个物理问题并解释了自己的推理过程,整个过程耗时 1 分多钟。
而另外一位研究者表示,Gemini-2.0-Flash-Thinking-Exp-01-21 这款最新模型的实际体验比 Jeff Dean 描述的还要快。
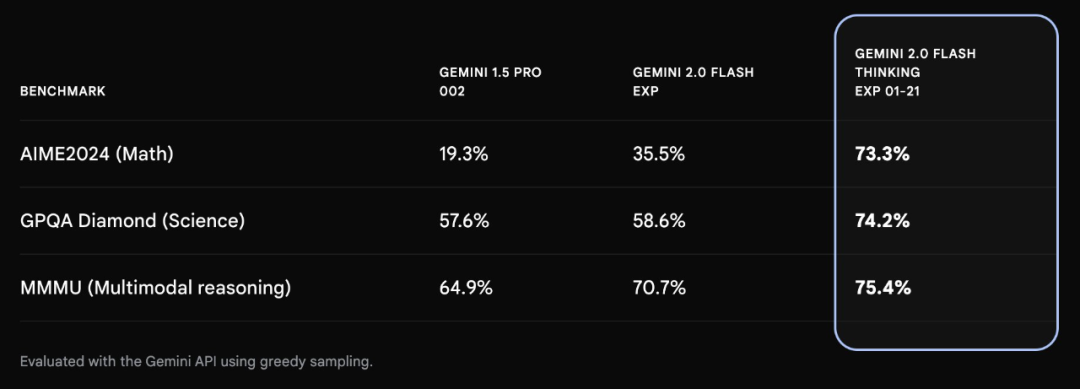
再看 Gemini 2.0 Flash Thinking 的成绩,那也是相当亮眼,和前两代 Gemini 1.5 Pro 002、Gemini 2.0 Flash EXP 相比,Gemini 2.0 Flash Thinking 在 AIME2024(数学能力测试)、GPQA Diamond(科学能力测试)和 MMMU(多模态推理能力)进步迅速,特别是数学成绩,提升了 54%。
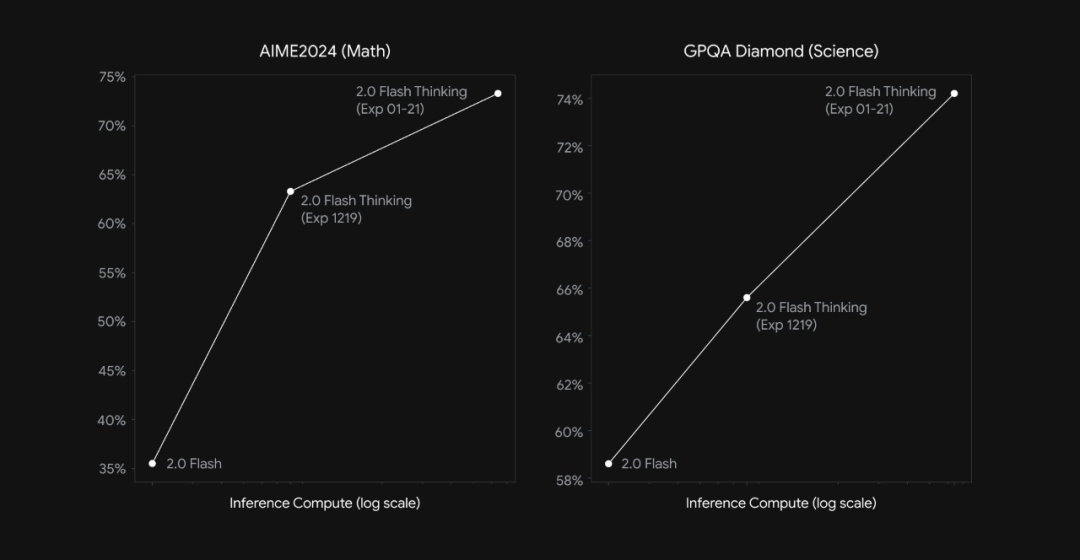
从折线图来看,即使是比较对象是一个月前的自己,也取得了显著的提升。
与此同时,在 AGI House 举办的活动中,Jeff Dean 和研究科学家 Mostafa Dehghani 透露了更多 Gemini 2.0 Flash Thinking 和 Gemini 2.0 的细节。
进入 Gemini 2.0 Flash Thinking 的互动界面,可以发现谷歌把 Gemini 系列所有模型都放在了这个称为「Google AI Studio」的界面。
从左侧的菜单来看,我们可以在这里一站式地获得 API 密钥、创建提示词、访问实时对话、开发 APP。平台还提供了模型调优、资源库管理、Drive 访问集成等进阶功能,并配备了提示词库、API 文档、开发者论坛等支持资源。
但这个界面上的功能就像「集市」一样分散,藏得比较深的功能入口似乎并不用户友好,也缺乏介绍模型能力的文档。Jeff Dean 对此表示,当模型不再是实验版而是正式发布时,谷歌将提供完整的技术报告,他们现在的主要目标是让用户试用,再根据更多反馈改善。
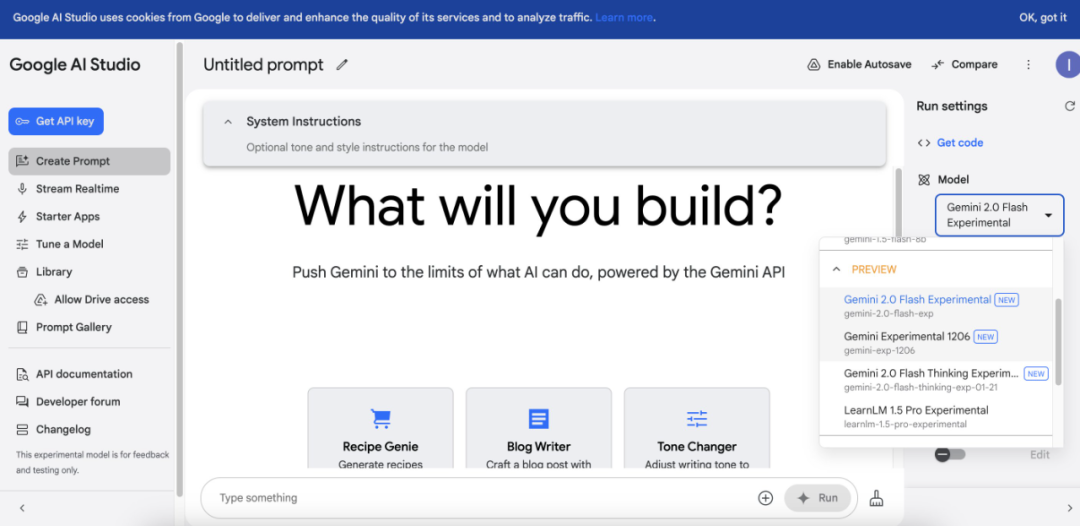
Gemini 2.0 Flash Thinking 的互动界面
此外,谷歌的开发理念更偏向「全面均衡」。「我们不希望模型在某些领域特别突出,而其他领域表现欠佳 —— 比如在读 X 射线时表现出色,但解读核磁共振时却很糟糕。」Jeff Dean 补充道:「我们的目标是打造一个真正有实力的通用模型,能够完成用户期待的各类任务。这需要持续改进:我们会收集用户反馈,了解模型在哪些方面做得好,哪些方面做得不够好。然后,获取更多人们关心的数据来提升,确保模型在各个方向都有进步,而不是局限在某个小范围内 —— 虽然在数学等特定领域,有时也会进行专门优化。」
Gemini 2.0 Flash Thinking 主推的亮点是超长的上下文窗口。不过,众所周知,很多具备长上下文窗口能力的 AI 模型都有个通病:聊着聊着就「变傻」了,说的话前言不搭后语,或者就直接「摆烂」,跳过上下文中的大段信息。
Jeff Dean 表示,Gemini 2.0 Flash Thinking 真正能做到在对话过程中保持连贯的思维,并灵活运用之前积累的信息来完成当前的任务。因相比混合在一起的数千亿训练数据,上下文窗口的信息对于模型来说非常清晰,因此,上下文窗口的信息对于 Gemini 2.0 Flash Thinking 来说,就像你让把一张普通轿车的图片改成敞篷车一样,模型能准确理解每个像素,然后一步步完成修改。
而从下面这个 demo 来看,Gemini 2.0 理解多模态的能力已经跃升了一个台阶。它可以根据语音提示,实时改变这三个小圆的排布,排成一行放在界面顶部,或者排列成一个雪人。更夸张的是,Gemini 2.0 对语音、视觉和动作的融会贯通已经达到了你说想要紫色的圆,它知道要把红色和蓝色的圆重叠在一起调色的境地。
想要如此精准地理解网页界面的布局和内容,需要强大的边框识别能力。Jeff Dean 揭秘,这来自 Project Mariner。Project Mariner 是一个研究性的实验项目,旨在探索人类将如何与 AI 智能体互动,第一步就是让 AI 理解并操作网页浏览器。
Project Mariner 的能力类似于 Claude 的「computer use」,可以实时访问用户的屏幕,理解浏览器中图像的含义。
传送门:https://deepmind.google/technologies/project-mariner/
当被问及 Gemini 系列模型是否要向更多模态进发时,Jeff Dean 的回答是:目前谷歌正在瞄准 3D 数据,而且已经有了很好的结果。
看来谷歌还攒了不少存货,下一个突破会在哪个领域?让我们拭目以待。
参考链接:
https://x.com/rohanpaul_ai/status/1881858428399722948
https://x.com/demishassabis/status/1881844417746632910
https://deepmind.google/technologies/gemini/flash-thinking/
https://x.com/agihouse_org/status/1881506816393380041
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com