浙大&商汤推出StarGen框架,解决场景视频生成时空一致性难题,实现高质量长视频生成和多项下游任务。
原文标题:生成越长越跑偏?浙大商汤新作StarGen让场景视频生成告别「短片魔咒」
原文作者:机器之心
冷月清谈:
浙江大学与商汤科技联合推出了StarGen,一个用于可扩展和可控场景生成的时空自回归框架。该框架解决了复杂场景长视频生成中时空一致性难题。StarGen的核心创新在于结合了稀疏视图3D几何信息和视频扩散模型,并引入了空间和时间双重条件机制,有效缓解了误差累积问题。
StarGen实现了多视一致的长视频生成,并支持稀疏视图插值、图生视频和布局驱动场景生成等多项任务。实验结果表明,StarGen在生成质量、一致性保持和场景扩展能力方面均优于现有方法。
该框架主要由三部分组成:时空自回归框架、时空条件视频生成和下游任务实现。时空自回归框架通过滑动窗口逐步生成长距离场景,利用时间和空间条件确保一致性。时空条件视频生成模块结合大型重建模型和视频扩散模型,利用空间条件的3D几何信息和时间条件图像特征,生成高质量视频。
StarGen通过深度损失、潜在损失和扩散损失等多重损失函数来保证生成内容的质量和一致性。
StarGen实现了多视一致的长视频生成,并支持稀疏视图插值、图生视频和布局驱动场景生成等多项任务。实验结果表明,StarGen在生成质量、一致性保持和场景扩展能力方面均优于现有方法。
该框架主要由三部分组成:时空自回归框架、时空条件视频生成和下游任务实现。时空自回归框架通过滑动窗口逐步生成长距离场景,利用时间和空间条件确保一致性。时空条件视频生成模块结合大型重建模型和视频扩散模型,利用空间条件的3D几何信息和时间条件图像特征,生成高质量视频。
StarGen通过深度损失、潜在损失和扩散损失等多重损失函数来保证生成内容的质量和一致性。
怜星夜思:
1、StarGen 提到的空间和时间条件具体指什么?它们是如何影响视频生成的?
2、相比其他视频生成方法,StarGen 的核心优势是什么?这种优势是如何实现的?
3、StarGen 的应用前景如何?除了文章中提到的应用场景,它还能在哪些领域发挥作用?
2、相比其他视频生成方法,StarGen 的核心优势是什么?这种优势是如何实现的?
3、StarGen 的应用前景如何?除了文章中提到的应用场景,它还能在哪些领域发挥作用?
原文内容
![]()
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]
本文介绍了一篇由浙江大学章国锋教授和商汤科技研究团队联合撰写的论文《StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation》。
针对复杂场景的长距离场景生成的时空一致性问题,该研究团队创新提出了一种解决方案 StarGen,其核心创新在于通过引入空间与时间双重条件机制,将稀疏视图的 3D 几何信息与视频扩散模型有机结合,缓解误差累积。
StarGen 实现了多视一致的长视频生成,并且能够支持稀疏视图插值、图生视频以及布局驱动场景生成等多样化任务。实验结果表明,StarGen 在生成质量、一致性保持和场景扩展能力等方面均显著优于现有方法。

-
论文标题:StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation
-
论文地址:https://arxiv.org/pdf/2501.05763
-
项目主页:https://zju3dv.github.io/StarGen/
背景
近年来,随着大规模模型的快速发展,3D 重建与生成技术取得了显著进展,并逐渐呈现出互补融合的趋势。在重建领域,基于大规模重建模型的方法显著降低了对密集多视角数据采集的依赖,同时生成模型被有效应用于稀疏输入视角下不可见区域的补全任务。
在生成领域,3D 重建技术为 2D 生成模型向 3D 生成任务的迁移提供了重要支撑,具体表现为两种技术路径:其一是通过将 2D 概率分布蒸馏为 3D 表示,其二是基于 2D 生成图像重建 3D 表示。
然而,这些大规模重建与生成模型面临一个关键性挑战:在有限计算资源约束下,单次推理过程仅能处理有限数量的 Token。
尽管现有一些研究提出了时间自回归方法,通过将当前视频片段的初始帧与前一生成片段的末尾帧进行条件关联以实现长视频生成,但这类方法仅能在较短时间跨度内维持时序一致性。随着生成过程的推进,误差累积问题将导致空间一致性难以有效保持。
相关工作
目前与本文工作相关的新视角生成方法主要分为三类:重建模型和生成模型,以及结合重建与生成的混合方法。
重建模型
重建模型主要通过从多视角输入中重建场景的几何结构和外观信息来实现新视角生成。传统几何重建方法,如 NeRF 和 3D-GS,通过隐式或显式表示对场景进行建模,在生成高质量新视角方面表现优异,但其对密集视角输入的依赖限制了其适用性。
基于前馈网络的重建方法,如 PixelNeRF 和 PixelSplat,通过从稀疏视图直接推断 3D 表示,降低了对密集输入的需求,显著提升了重建效率。
然而,这类方法本质上仍局限于重建任务,缺乏生成能力,仍然需要输入图像覆盖充分才能获得完整的场景表达。
生成模型
生成模型通过学习输入数据的分布来生成图像或视频,主要包括生成对抗网络(GAN)和扩散模型的两类方法。
GAN 在早期取得了一定成功,但在跨帧或跨片段的全局一致性方面表现不足。扩散模型通过逆向扩散过程生成高质量图像,并结合控制条件(如 ControlNet)实现对生成内容的精确约束。
尽管扩散模型在视频生成任务中表现出色,通过全注意力机制(Full-Attention)能够实现单段视频内的多视图一致性,但由于计算资源的限制,现有方法难以实现长距离、高质量且多视一致的视频生成。
结合重建与生成的混合方法
近年来,重建与生成方法的结合逐渐受到关注,通过互补方式提升生成质量和一致性。代表性方法如 ViewCrafter,利用 Dust3r 从稀疏视图中生成点云,并将所有点云投影到当前片段作为空间约束,从而实现多段生成视频的几何一致性。
然而,这种以点云作为空间约束的方法会随着生成视频的增长而累积点云重建误差,最终导致生成内容出现显著偏差。此外,该方法需要训练视频生成模型本身,限制了其扩展性和通用性。
方法
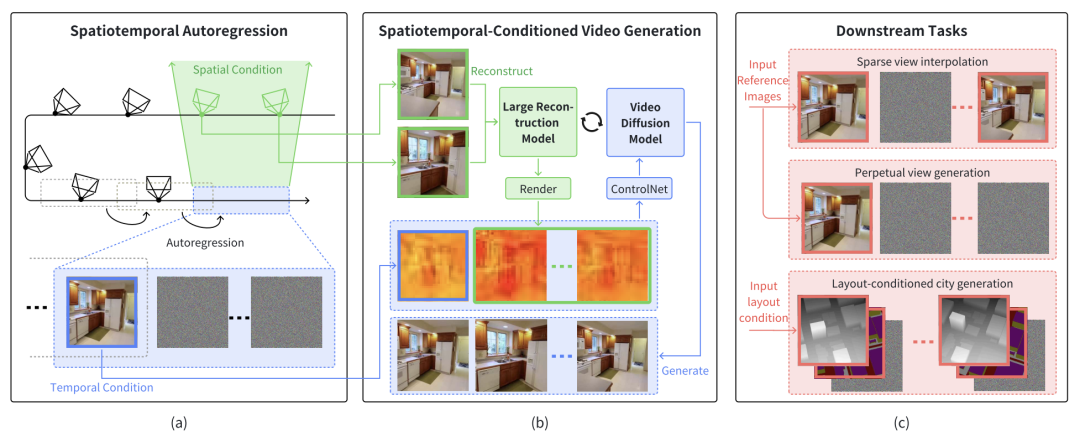
图 1. 系统框架
系统概述
如图 1 所示,StarGen 框架主要包括三部分:时空自回归框架、时空条件视频生成和下游任务实现。
时空自回归框架
StarGen 通过滑动窗口的方式逐步实现长距离场景生成,每个窗口的生成既依赖于上一窗口的时间条件图像,也依赖于与当前窗口具有共视关系的空间相邻图像。
具体而言,StarGen 从前一窗口生成的关键帧中选择图像作为时间条件,来保证当前生成结果和上一段视频在时间上的连续性。
同时,从历史窗口中提取与当前窗口具有最大共视区域的图像集合作为空间条件,保证长距离生成过程中各个视频间的多视一致。
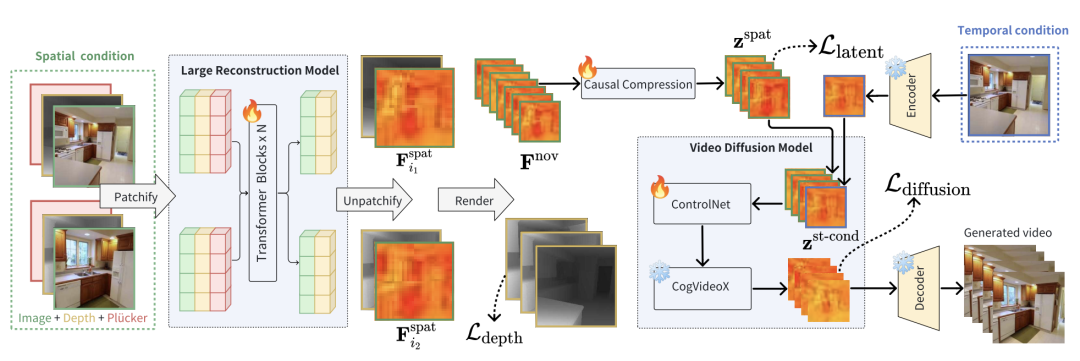
图 2. 时空条件视频生成
时空条件视频生成
StarGen 通过引入大型重建模型(LRM)和视频扩散模型(VDM)实现高质量可控视频生成。具体流程如图 2 所示:
1. 空间条件处理:从空间条件图像中提取 3D 几何信息,并通过基于多视几何的渲染方法生成目标视角的特征图。这些特征图随后被压缩到 VDM 的潜在空间中。
2. 时间条件处理:将时间条件图像通过变分自编码器(VAE)编码为隐特征,并与空间条件特征融合,生成结合时空信息的综合特征。
3. 视频扩散生成:将融合后的时空特征输入视频扩散模型,通过 ControlNet 进行条件控制生成,生成当前窗口的高质量图像序列。
下游任务实现
StarGen 框架支持多种场景生成任务:
-
稀疏视图插值:通过结合时空条件,生成输入图像之间的中间帧,同时支持精确的姿态控制;
-
图生视频:以单张输入图像为起点,逐帧生成实现长距离视角变化;
-
基于布局的城市生成:结合深度图和语义图,通过 ControlNet 对布局信息进行精准约束,生成具有大规模场景一致性的城市场景。
损失函数设计
为了确保生成内容的一致性和质量,StarGen 框架设计了三种损失函数:
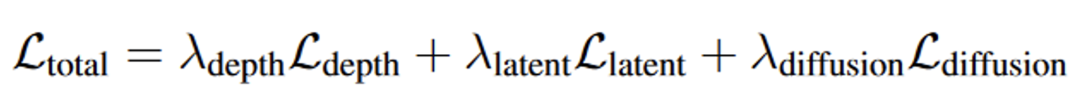
图 3. 损失函数
1. 深度损失:通过多视角约束优化重建深度图的精度,从而提升空间条件的几何一致性。
2. 潜在损失:监督空间条件生成的潜在特征与真实视图特征之间的差异,确保特征空间的一致性。
3. 扩散损失:优化扩散模型生成的潜在特征与噪声潜在变量之间的差异,增强生成序列的质量。
结果
稀疏视图插值
在 RealEstate-10K 和 ACID 数据集上,StarGen 在 PSNR 指标上优于其他基于重建和生成的方法,同时在其他指标上达到了当前最先进的水平:
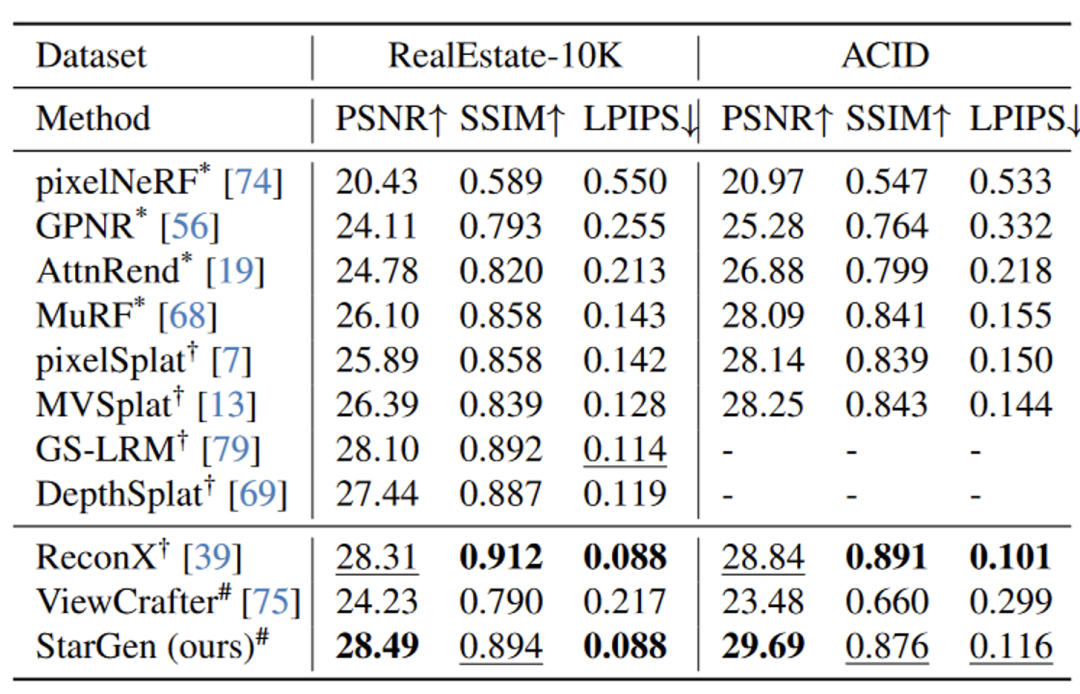
表 1. 稀疏视角插值的定量对比
特别是在输入视图几乎无重叠的情况下,仍能生成合理的中间内容:

图 4. 稀疏视角插值的定性对比
图生视频
1. 短视频生成:在测试集上生成 25 帧视频,StarGen 在所有指标(PSNR、SSIM、LPIPS)上表现最好。
2. 长视频生成:与其他方法相比,StarGen 生成的长视频在视觉保真度和姿态精度上退化更少。
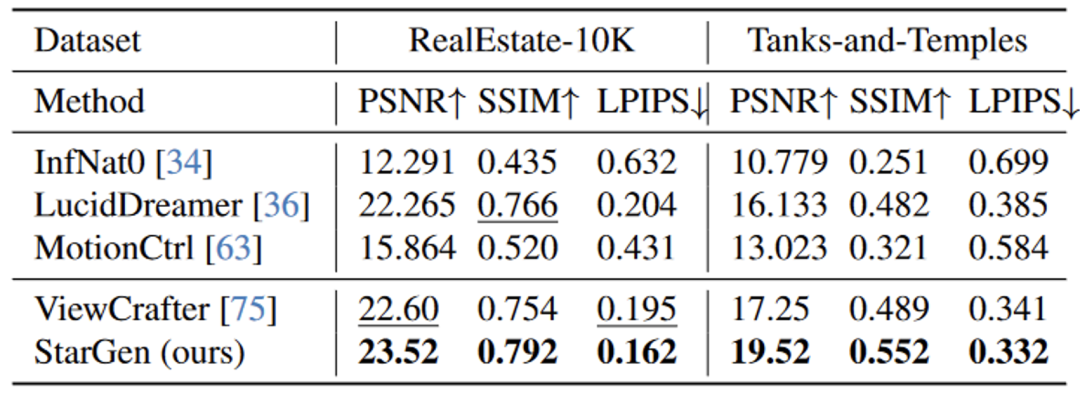
表 2. 图生短视频的定量对比
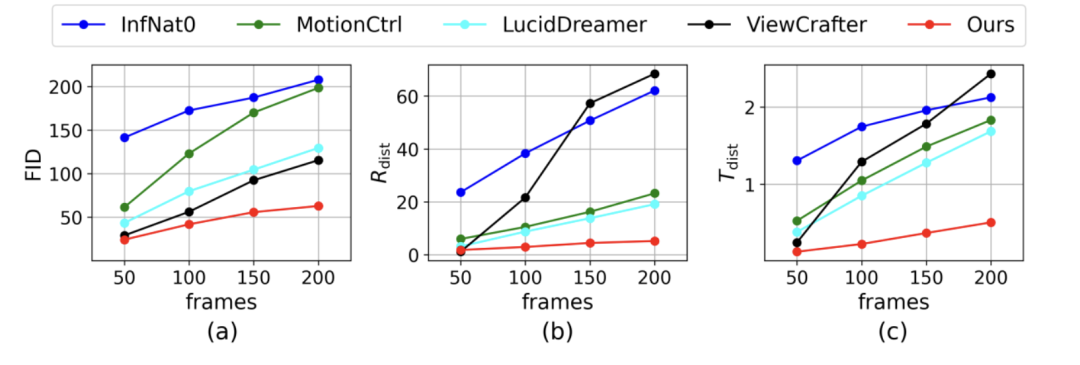
图 5. 图生长视频的定量对比

图 6. 图生长视频的定性对比
基于布局的城市生成
实验基于 OpenStreetMap 布局数据生成城市场景,与 CityDreamer 方法相比,StarGen 生成的内容在布局一致性和细节保真度上更优:
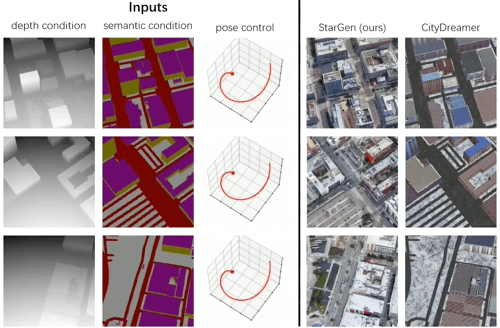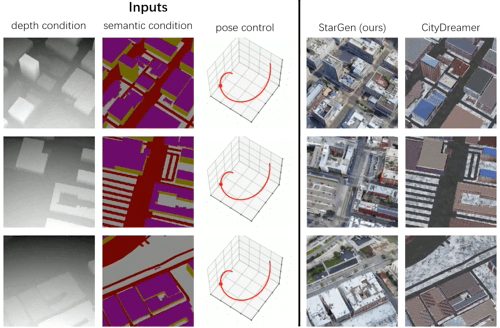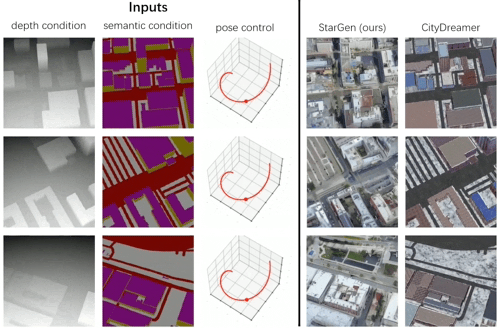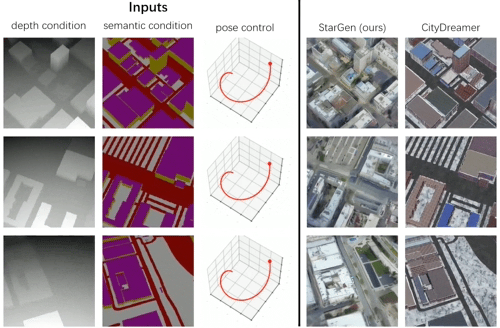
图 7. 基于布局的城市生成定性对比
消融实验
通过逐步移除空间或时间条件等模块进行消融实验,结果表明这两种条件的结合对生成质量和一致性有显著贡献:
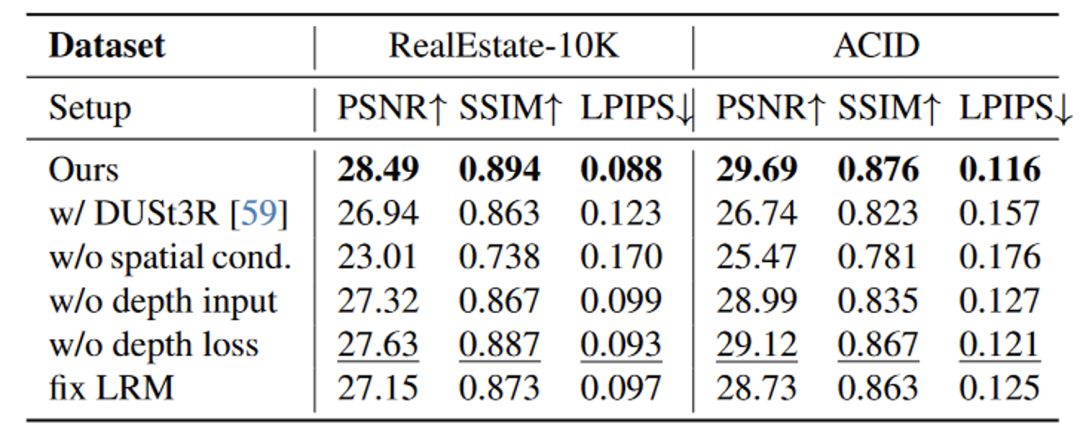
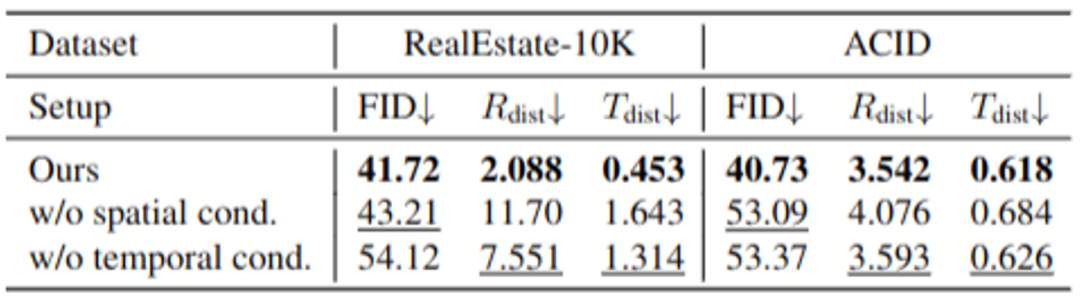
表 3. 消融实验
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]