循环神经网络和长短期记忆网络已经广泛应用于时序任务,比如文本预测、机器翻译、文章生成等。然而,它们面临的一大问题就是如何记录长期依赖。
为了解决这个问题,一个名为 Transformer 的新架构应运而生。从那以后,Transformer 被应用到多个自然语言处理方向,到目前为止还未有新的架构能够将其替代。可以说,它的出现是自然语言处理领域的突破,并为新的革命性架构(BERT、GPT-3、T5等)打下了理论基础。
Transformer 完全依赖于注意力机制,并摒弃了循环。它使用的是一种特殊的注意力机制,称为自注意力(self-attention)。我们将在后面介绍具体细节。
我们来通过一个文本翻译实例来了解 Transformer 是如何工作的。Transformer 由编码器和解码器两部分组成。首先,向编码器输入一句话(原句),让其学习这句话的特征,再将特征作为输入传输给解码器。最后,此特征会通过解码器生成输出句(目标句)。
假设我们需要将一个句子从英文翻译为法文。如图 1-1 所示,首先,我们需要将这个英文句子(原句)输进编码器。编码器将提取英文句子的特征并提供给解码器。最后,解码器通过特征完成法文句子(目标句)的翻译。
图 1-1 Transformer的编码器和解码器
此方法看起来很简单,但是如何实现呢?Transformer 中的编码器和解码器是如何将英文(原句)转换为法文(目标句)的呢?编码器和解码器的内部又是怎样工作的呢?
接下来,我们将按照数据处理的顺序,依次讲解编码器和解码器。
Transformer 中的编码器不止一个,而是由一组 个编码器串联而成。一个编码器的输出作为下一个编码器的输入。在图 1-2 中有个编码器,每一个编码器都从下方接收数据,再输出给上方。以此类推,原句中的特征会由最后一个编码器输出。编码器模块的主要功能就是提取原句中的特征。
个编码器串联而成。一个编码器的输出作为下一个编码器的输入。在图 1-2 中有个编码器,每一个编码器都从下方接收数据,再输出给上方。以此类推,原句中的特征会由最后一个编码器输出。编码器模块的主要功能就是提取原句中的特征。
图 1-2个编码器
需要注意的是,在 Transformer 原论文 Attention Is All You Need 中,作者使用了 ,也就是说,一共有 6 个编码器叠加在一起。当然,我们可以尝试使用不同的值。这里为了方便理解,我们使用
,也就是说,一共有 6 个编码器叠加在一起。当然,我们可以尝试使用不同的值。这里为了方便理解,我们使用 ,如图 1-3 所示。
,如图 1-3 所示。
图 1-3 两个叠加在一起的编码器
编码器到底是如何工作的呢?它又是如何提取出原句(输入句)的特征的呢?要进一步理解,我们可以将编码器再次分解。图 1-4 展示了编码器的组成部分。
图 1-4 编码器的组成部分
从图 1-4 中可知,每一个编码器的构造都是相同的,并且包含两个部分:
现在我们来看看这两部分是如何工作的。
要了解多头注意力机制的工作原理,我们首先需要理解什么是自注意力机制。
1.2.1 自注意力机制
让我们通过一个例子来快速理解自注意力机制。请看下面的例句:
A dog ate the food because it was hungry(一只狗吃了食物,因为它很饿)
例句中的代词 it(它)可以指代 dog(狗)或者 food(食物)。当读这段文字的时候,我们自然而然地认为 it 指代的是 dog,而不是 food。但是当计算机模型在面对这两种选择时该如何决定呢?这时,自注意力机制有助于解决这个问题。
还是以上句为例,我们的模型首先需要计算出单词 A 的特征值,其次计算 dog 的特征值,然后计算 ate 的特征值,以此类推。当计算每个词的特征值时,模型都需要遍历每个词与句子中其他词的关系。模型可以通过词与词之间的关系来更好地理解当前词的意思。
比如,当计算 it 的特征值时,模型会将 it 与句子中的其他词一一关联,以便更好地理解它的意思。
如图 1-5 所示,it 的特征值由它本身与句子中其他词的关系计算所得。通过关系连线,模型可以明确知道原句中 it 所指代的是 dog 而不是 food,这是因为 it 与 dog 的关系更紧密,关系连线相较于其他词也更粗。
图 1-5 自注意力示例
我们已经初步了解了什么是自注意力机制,下面我们将关注它具体是如何实现的。
为简单起见,我们假设输入句(原句)为 I am good(我很好)。首先,我们将每个词转化为其对应的词嵌入向量。需要注意的是,嵌入只是词的特征向量,这个特征向量也是需要通过训练获得的。
单词 I 的词嵌入向量可以用 来表示,相应地,am 为
来表示,相应地,am 为 ,good 为
,good 为 ,即:
,即:
-
单词 I 的词嵌入向量量=[1.76, 2.22, , 6.66];
-
单词 am 的词嵌入向量=[7.77, 0.631, , 5.35];
-
单词 good 的词嵌入向量=[11.44, 10.10, , 3.33]。
这样一来,原句 I am good 就可以用一个矩阵 (输入矩阵或嵌入矩阵)来表示,如图 1-6 所示。
(输入矩阵或嵌入矩阵)来表示,如图 1-6 所示。
图 1-6 输入矩阵
图 1-6 中的值为随意设定,只是为了让我们更好地理解其背后的数学原理。
通过输入矩阵,我们可以看出,矩阵的第一行表示单词 I 的词嵌入向量。以此类推,第二行对应单词 am 的词嵌入向量,第三行对应单词 good 的词嵌入向量。所以矩阵的维度为[句子的长度×词嵌入向量维度]。原句的长度为 3,假设词嵌入向量维度为 512,那么输入矩阵的维度就是 [3×512]。
现在通过矩阵,我们再创建三个新的矩阵:查询(query)矩阵 、键(key)矩阵
、键(key)矩阵 ,以及值(value)矩阵
,以及值(value)矩阵 。等一下,怎么又多了三个矩阵?为何需要创建它们?接下来,我们将继续了解在自注意力机制中如何使用这三个矩阵。
。等一下,怎么又多了三个矩阵?为何需要创建它们?接下来,我们将继续了解在自注意力机制中如何使用这三个矩阵。
为了创建查询矩阵、键矩阵和值矩阵,我们需要先创建另外三个权重矩阵,分别为 、
、 、
、 。用矩阵分别乘以矩阵、、,就可以依次创建出查询矩阵、键矩阵和值矩阵。
。用矩阵分别乘以矩阵、、,就可以依次创建出查询矩阵、键矩阵和值矩阵。
值得注意的是,权重矩阵、和的初始值完全是随机的,但最优值则需要通过训练获得。我们取得的权值越优,通过计算所得的查询矩阵、键矩阵和值矩阵也会越精确。
如图 1-7 所示,将输入矩阵分别乘以、和后,我们就可以得出对应的查询矩阵、键矩阵和值矩阵。
图 1-7 创建查询矩阵、键矩阵和值矩阵
根据图 1-7,我们可以总结出以下三点。
因为每个向量的维度均为 64,所以对应的矩阵维度为 [句子长度×64]。因为我们的句子长度为 3,所以代入后可得维度为 [3×64]。
至此,我们还是不明白为什么要计算这些值。该如何使用查询矩阵、键矩阵和值矩阵呢?它们怎样才能用于自注意力模型呢?这些问题将在下面进行解答。
理解自注意力机制
目前,我们学习了如何计算查询矩阵、键矩阵和值矩阵,并知道它们是基于输入矩阵计算而来的。现在,让我们学习查询矩阵、键矩阵和值矩阵如何应用于自注意力机制。
要计算一个词的特征值,自注意力机制会使该词与给定句子中的所有词联系起来。还是以 I am good 这句话为例。为了计算单词 I 的特征值,我们将单词 I 与句子中的所有单词一一关联,如图 1-8 所示。
图 1-8 自注意力的示例
了解一个词与句子中所有词的相关程度有助于更精确地计算特征值。现在,让我们学习自注意力机制如何利用查询矩阵、键矩阵和值矩阵将一个词与句子中的所有词联系起来。自注意力机制包括 4 个步骤,我们来逐一学习。
第 1 步,自注意力机制首先要计算查询矩阵与键矩阵 的点积,两个矩阵如图 1-9 所示。
的点积,两个矩阵如图 1-9 所示。
图 1-9 查询矩阵和键矩
图 1-10 显示了查询矩阵与键矩阵的点积结果。
图 1-10 计算查询矩阵与键矩阵的点积
但为何需要计算查询矩阵与键矩阵的点积呢? 到底是什么意思?下面,我们将通过细看的结果来理解以上问题。
到底是什么意思?下面,我们将通过细看的结果来理解以上问题。
首先,来看矩阵的第一行,如图1-11所示。可以看到,这一行计算的是查询向量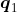 (I)与所有的键向量
(I)与所有的键向量 (I)、
(I)、 (am)和
(am)和 (good)的点积。通过计算两个向量的点积可以知道它们之间的相似度。
(good)的点积。通过计算两个向量的点积可以知道它们之间的相似度。
因此,通过计算查询向量()和键向量(、、)的点积,可以了解单词I与句子中的所有单词的相似度。我们了解到,I这个词与自己的关系比与 am 和 good 这两个词的关系更紧密,因为点积值 大于
大于 和
和 。
。
图 1-11 计算查询向量()与键向量(、、)的点积
注意,本文使用的数值是任意选择的,只是为了让我们更好地理解背后的数学原理。
现在来看矩阵的第二行,如图 1-12 所示。现在需要计算查询向量 (am)与所有的键向量(I)、(am)、(good)的点积。这样一来,我们就可以知道 am 与句中所有词的相似度。
(am)与所有的键向量(I)、(am)、(good)的点积。这样一来,我们就可以知道 am 与句中所有词的相似度。
通过查看矩阵的第二行可以知道,单词 am 与自己的关系最为密切,因为点积值最大。
图 1-12 计算查询向量()与键向量(、、)的点积
同理,来看矩阵的第三行。如图 1-13 所示,计算查询向量 (good)与所有键向量 (I)、(am)和 (good)的点积。
(good)与所有键向量 (I)、(am)和 (good)的点积。
从结果可知,good 与自己的关系更密切,因为点积值 大于
大于 和
和 。
。
图 1-13 计算查询向量()与键向量(、、)的点积
综上所述,计算查询矩阵与键矩阵的点积,从而得到相似度分数。这有助于我们了解句子中每个词与所有其他词的相似度。
第 2 步,自注意力机制的第 2 步是将矩阵除以键向量维度的平方根。这样做的目的主要是获得稳定的梯度。
我们用 来表示键向量维度。然后,将除以
来表示键向量维度。然后,将除以 。在本例中,键向量维度是 64。取 64 的平方根,我们得到 8。将第 1 步中算出的除以 8,如图 1-14 所示。
。在本例中,键向量维度是 64。取 64 的平方根,我们得到 8。将第 1 步中算出的除以 8,如图 1-14 所示。
图 1-14除以键向量维度的平方根
第 3 步,目前所得的相似度分数尚未被归一化,我们需要使用 softmax 函数对其进行归一化处理。如图 1-15 所示,应用 softmax 函数将使数值分布在 0 到 1 的范围内,且每一行的所有数之和等于 1。
图 1-15 应用 softmax 函数
我们将图 1-15 中的矩阵称为分数矩阵。通过这些分数,我们可以了解句子中的每个词与所有词的相关程度。以图 1-15 中的分数矩阵的第一行为例,它告诉我们,I 这个词与它本身的相关程度是 90%,与 am 这个词的相关程度是 7%,与 good 这个词的相关程度是 3%。
第 4 步,至此,我们计算了查询矩阵与键矩阵的点积,得到了分数,然后用 softmax 函数将分数归一化。自注意力机制的最后一步是计算注意力矩阵 。
。
注意力矩阵包含句子中每个单词的注意力值。它可以通过将分数矩阵softmax ( )乘以值矩阵得出,如图 1-16 所示。
)乘以值矩阵得出,如图 1-16 所示。
图 1-16 计算注意力矩阵
假设计算结果如图 1-17 所示。
图 1-17 注意力矩阵示例
由图 1-16 可以看出,注意力矩阵就是值向量与分数加权之后求和所得到的结果。让我们逐行理解这个计算过程。首先,第一行 对应 I 这个词的自注意力值,它通过图 1-18 所示的方法计算所得。
对应 I 这个词的自注意力值,它通过图 1-18 所示的方法计算所得。
图 1-18 单词I的自注意力值
从图 1-18 中可以看出,单词 I 的自注意力值是分数加权的值向量之和。所以,的值将包含 90% 的值向量  (I)、7% 的值向量
(I)、7% 的值向量  (am),以及 3% 的值向量
(am),以及 3% 的值向量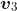 (good)。
(good)。
这有什么用呢?为了回答这个问题,让我们回过头去看之前的例句:A dog ate the food because it was hungry(一只狗吃了食物,因为它很饿)。在这里,it 这个词表示 dog。我们将按照前面的步骤来计算 it 这个词的自注意力值。假设计算过程如图 1-19 所示。
图 1-19 单词 it 的自注意力值
从图 1-19 中可以看出,it 这个词的自注意力值包含 100% 的值向量(dog)。这有助于模型理解 it 这个词实际上指的是 dog 而不是 food。这也再次说明,通过自注意力机制,我们可以了解一个词与句子中所有词的相关程度。
回到 I am good 这个例子,单词 am 的自注意力值 也是分数加权的值向量之和,如图 1-20 所示。
也是分数加权的值向量之和,如图 1-20 所示。
图 1-20 单词 am 的自注意力值
从图 1-20 中可以看出,的值包含 2.5% 的值向量(I)、95% 的值向量(am),以及 2.5% 的值向量(good)。同样,单词 good 的自注意力值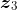 也是分数加权的值向量之和,如图 1-21 所示。
也是分数加权的值向量之和,如图 1-21 所示。
图 1-21 单词good的自注意力值
可见,的值包含 21% 的值向量(I)、3% 的值向量(am),以及 76% 的值向量(good)。
综上所述,注意力矩阵由句子中所有单词的自注意力值组成,它的计算公式如下。

现将自注意力机制的计算步骤总结如下:
自注意力机制的计算流程图如图 1-22 所示。
图 1-22 自注意力机制
自注意力机制也被称为缩放点积注意力机制,这是因为其计算过程是先求查询矩阵与键矩阵的点积,再用对结果进行缩放。
我们已经了解了自注意力机制的工作原理。下面我们将了解多头注意力层。
1.2.2 多头注意力层
顾名思义,多头注意力是指我们可以使用多个注意力头,而不是只用一个。也就是说,我们可以应用在 1.2.1 节中学习的计算注意力矩阵的方法,来求得多个注意力矩阵。
让我们通过一个例子来理解多头注意力层的作用。以 All is well 这句话为例,假设我们需要计算 well 的自注意力值。在计算相似度分数后,我们得到图 1-23 所示的结果。
图 1-23 单词well的自注意力值
从图 1-23 中可以看出,well 的自注意力值是分数加权的值向量之和,并且它实际上是由 All 主导的。也就是说,将 All 的值向量乘以 0.6,而 well 的值向量只乘以了 0.4。这意味着 将包含 60% 的 All 的值向量,而 well 的值向量只有 40%。
将包含 60% 的 All 的值向量,而 well 的值向量只有 40%。
这只有在词义含糊不清的情况下才有用。以下句为例:
A dog ate the food because it was hungry(一只狗吃了食物,因为它很饿)
假设我们需要计算 it 的自注意力值。在计算相似度分数后,我们得到图 1-24 所示的结果。
图 1-24 单词 it 的自注意力值
从图 1-24 中可以看出,it 的自注意力值正是 dog 的值向量。在这里,单词 it 的自注意力值被 dog 所控制。这是正确的,因为 it 的含义模糊,它指的既可能是 dog,也可能是 food。
如果某个词实际上由其他词的值向量控制,而这个词的含义又是模糊的,那么这种控制关系是有用的;否则,这种控制关系反而会造成误解。为了确保结果准确,我们不能依赖单一的注意力矩阵,而应该计算多个注意力矩阵,并将其结果串联起来。使用多头注意力的逻辑是这样的:使用多个注意力矩阵,而非单一的注意力矩阵,可以提高注意力矩阵的准确性。我们将进一步探讨这一点。
假设要计算两个注意力矩阵 和
和 。首先,计算注意力矩阵。我们已经知道,为了计算注意力矩阵,需要创建三个新的矩阵,分别为查询矩阵、键矩阵和值矩阵。为了创建查询矩阵
。首先,计算注意力矩阵。我们已经知道,为了计算注意力矩阵,需要创建三个新的矩阵,分别为查询矩阵、键矩阵和值矩阵。为了创建查询矩阵 、键矩阵
、键矩阵 和值矩阵
和值矩阵 ,我们引入三个新的权重矩阵,称为
,我们引入三个新的权重矩阵,称为 、
、 、
、 。用矩阵分别乘以矩阵、、,就可以依次创建出查询矩阵、键矩阵和值矩阵。
。用矩阵分别乘以矩阵、、,就可以依次创建出查询矩阵、键矩阵和值矩阵。
基于以上内容,注意力矩阵可按以下公式计算得出。
接下来计算第二个注意力矩阵。为了计算注意力矩阵,我们创建了另一组矩阵:查询矩阵 、键矩阵
、键矩阵 和值矩阵
和值矩阵 ,并引入了三个新的权重矩阵,即
,并引入了三个新的权重矩阵,即 、
、 、
、 。用矩阵分别乘以矩阵、、,就可以依次得出对应的查询矩阵、键矩阵和值矩阵。
。用矩阵分别乘以矩阵、、,就可以依次得出对应的查询矩阵、键矩阵和值矩阵。
注意力矩阵可按以下公式计算得出。
同理,可以计算出 个注意力矩阵。假设我们有 8 个注意力矩阵,即到
个注意力矩阵。假设我们有 8 个注意力矩阵,即到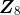 ,那么可以直接将所有的注意力头(注意力矩阵)串联起来,并将结果乘以一个新的权重矩阵
,那么可以直接将所有的注意力头(注意力矩阵)串联起来,并将结果乘以一个新的权重矩阵 ,从而得出最终的注意力矩阵,公式如下所示。
,从而得出最终的注意力矩阵,公式如下所示。
现在,我们已经了解了多头注意力层的工作原理。1.2.3 节将介绍另一个有趣的概念,即位置编码(positional encoding)。
1.2.3 通过位置编码来学习位置
还是以 I am good(我很好)为例。在 RNN 模型中,句子是逐字送入学习网络的。换言之,首先把 I 作为输入,接下来是 am,以此类推。通过逐字地接受输入,学习网络就能完全理解整个句子。
然而,Transformer 网络并不遵循递归循环的模式。因此,我们不是逐字地输入句子,而是将句子中的所有词并行地输入到神经网络中。并行输入有助于缩短训练时间,同时有利于学习长期依赖。
不过,并行地将词送入 Transformer,却不保留词序,它将如何理解句子的意思呢?要理解一个句子,词序(词在句子中的位置)不是很重要吗?
当然,Transformer 也需要一些关于词序的信息,以便更好地理解句子。但这将如何做到呢?现在,让我们来解答这个问题。
对于给定的句子 I am good,我们首先计算每个单词在句子中的嵌入值。嵌入维度可以表示为 。比如将嵌入维度设为 4,那么输入矩阵的维度将是[句子长度×嵌入维度],也就是 [3 × 4]。
。比如将嵌入维度设为 4,那么输入矩阵的维度将是[句子长度×嵌入维度],也就是 [3 × 4]。
同样,用输入矩阵(嵌入矩阵)表示输入句 I am good。假设输入矩阵如图 1-25 所示。
图 1-25 输入矩阵
如果把输入矩阵直接传给 Transformer,那么模型是无法理解词序的。因此,需要添加一些表明词序(词的位置)的信息,以便神经网络能够理解句子的含义。所以,我们不能将输入矩阵直接传给 Transformer。这里引入了一种叫作位置编码的技术,以达到上述目的。顾名思义,位置编码是指词在句子中的位置(词序)的编码。
位置编码矩阵 的维度与输入矩阵的维度相同。在将输入矩阵直接传给 Transformer 之前,我们将使其包含位置编码。我们只需将位置编码矩阵添加到输入矩阵中,再将其作为输入送入神经网络,如图 1-26 所示。这样一来,输入矩阵不仅有词的嵌入值,还有词在句子中的位置信息。
的维度与输入矩阵的维度相同。在将输入矩阵直接传给 Transformer 之前,我们将使其包含位置编码。我们只需将位置编码矩阵添加到输入矩阵中,再将其作为输入送入神经网络,如图 1-26 所示。这样一来,输入矩阵不仅有词的嵌入值,还有词在句子中的位置信息。
图 1-26 在输入矩阵中添加位置编码
位置编码矩阵究竟是如何计算的呢?如下所示,Transformer 论文Attention Is All You Need 的作者使用了正弦函数来计算位置编码:
在上面的等式中,pos 表示该词在句子中的位置, 表示在输入矩阵中的位置。下面通过一个例子来理解以上等式,如图 1-27 所示。
表示在输入矩阵中的位置。下面通过一个例子来理解以上等式,如图 1-27 所示。
图 1-27 计算位置编码矩阵
可以看到,在位置编码中,当是偶数时,使用正弦函数;当是奇数时,则使用余弦函数。通过简化矩阵中的公式,可以得出图 1-28 所示的结果。
图 1-28 计算位置编码矩阵(简化版)
我们知道 I 位于句子的第 0 位 2,am 在第 1 位,good 在第 2 位。代入 pos 值,我们得到图 1-29 所示的结果。
图 1-29 继续计算位置编码矩阵
最终的位置编码矩阵如图 1-30 所示。
图 1-30 位置编码矩阵
只需将输入矩阵与计算得到的位置编码矩阵进行逐元素相加,并将得出的结果作为输入矩阵送入编码器中。
让我们回顾一下编码器架构。图 1-31 是一个编码器模块,从中我们可以看到,在将输入矩阵送入编码器之前,首先要将位置编码加入输入矩阵中,再将其作为输入送入编码器。
图 1-31 编码器模块
我们已经学习了多头注意力层,也了解了位置编码的工作原理。在 1.2.4 节中,我们将学习前馈网络层。
1.2.4 前馈网络层
前馈网络层在编码器模块中的位置如图 1-32 所示。
图 1-32 前馈网络层在编码器模块中的位置
前馈网络由两个有 ReLU 激活函数的全连接层组成。前馈网络的参数在句子的不同位置上是相同的,但在不同的编码器模块上是不同的。在 1.2.5 节中,我们将了解编码器的叠加和归一组件。
1.2.5 叠加和归一组件
在编码器中还有一个重要的组成部分,即叠加和归一组件。它同时连接一个子层的输入和输出,如图 1-33 所示(虚线部分)。
图 1-33 带有叠加和归一组件的编码器模块
叠加和归一组件实际上包含一个残差连接与层的归一化。层的归一化可以防止每层的值剧烈变化,从而提高了模型的训练速度。
至此,我们已经了解了编码器的所有部分。在 1.2.6 节中,我们将它们放在一起看看编码器是如何工作的。
1.2.6 编码器总览
图 1-34 显示了叠加的两个编码器,但只有编码器 1 被展开,以便你查看细节。
图 1-34 叠加的两个编码器
通过图 1-34,我们可以总结出以下几点:
-
将输入转换为嵌入矩阵(输入矩阵),并将位置编码加入其中,再将结果作为输入传入底层的编码器(编码器1)。
-
编码器 1 接受输入并将其送入多头注意力层,该子层运算后输出注意力矩阵。
-
将注意力矩阵输入到下一个子层,即前馈网络层。前馈网络层将注意力矩阵作为输入,并计算出特征值作为输出。
-
接下来,把从编码器1中得到的输出作为输入,传入下一个编码器(编码器 2)。
-
编码器 2 进行同样的处理,再将给定输入句子的特征值作为输出。
这样可以将个编码器一个接一个地叠加起来。从最后一个编码器(顶层的编码器)得到的输出将是给定输入句子的特征值。让我们把从最后一个编码器(在本例中是编码器2)得到的特征值表示为 。
。
我们把作为输入传给解码器。解码器将基于这个输入生成目标句。
现在,我们了解了 Transformer 的编码器部分。后面将详细分析解码器的工作原理。
假设我们想把英语句子 I am good(原句)翻译成法语句子 Je vais bien (目标句)。首先,将原句 I am good 送入编码器,使编码器学习原句,并计算特征值。
在前文中,我们学习了编码器是如何计算原句的特征值的。然后,我们把从编码器求得的特征值送入解码器。解码器将特征值作为输入,并生成目标句 Je vais bien,如图 1-35 所示。
图 1-35 Transformer 的编码器和解码器
在编码器部分,我们了解到可以叠加个编码器。同理,解码器也可以有个叠加在一起。为简化说明,我们设定。
如图 1-36 所示,一个解码器的输出会被作为输入传入下一个解码器。我们还可以看到,编码器将原句的特征值(编码器的输出)作为输入传给所有解码器,而非只给第一个解码器。因此,一个解码器(第一个除外)将有两个输入:一个是来自前一个解码器的输出,另一个是编码器输出的特征值。
图 1-36 编码器和解码器
接下来,我们学习解码器究竟是如何生成目标句的。当 时(
时( 表示时间步),解码器的输入是 <sos>,这表示句子的开始。解码器收到 <sos> 作为输入,生成目标句中的第一个词,即 Je,如图 1-37 所示。
表示时间步),解码器的输入是 <sos>,这表示句子的开始。解码器收到 <sos> 作为输入,生成目标句中的第一个词,即 Je,如图 1-37 所示。
图 1-37解码器在时的预测结果
当 时,解码器使用当前的输入和在上一步 生成的单词,预测句子中的下一个单词。在本例中,解码器将 <sos> 和 Je(来自上一步)作为输入,并试图生成目标句中的下一个单词,如图 1-38 所示。
时,解码器使用当前的输入和在上一步 生成的单词,预测句子中的下一个单词。在本例中,解码器将 <sos> 和 Je(来自上一步)作为输入,并试图生成目标句中的下一个单词,如图 1-38 所示。
图 1-38 解码器在时的预测结果
同理,你可以推断出解码器在 时的预测结果。此时,解码器将<sos>、Je 和 vais(来自上一步)作为输入,并试图生成句子中的下一个单词,如图 1-39 所示。
时的预测结果。此时,解码器将<sos>、Je 和 vais(来自上一步)作为输入,并试图生成句子中的下一个单词,如图 1-39 所示。
图 1-39 解码器在时的预测结果
在每一步中,解码器都将上一步新生成的单词与输入的词结合起来,并预测下一个单词。因此,在最后一步( ),解码器将 <sos>、Je、vais和 bien 作为输入,并试图生成句子中的下一个单词,如图 1-40 所示。
),解码器将 <sos>、Je、vais和 bien 作为输入,并试图生成句子中的下一个单词,如图 1-40 所示。
图 1-40 解码器在时的预测结果
从图 1-40 中可以看到,一旦生成表示句子结束的 <eos> 标记,就意味着解码器已经完成了对目标句的生成工作。
在编码器部分,我们将输入转换为嵌入矩阵,并将位置编码添加到其中,然后将其作为输入送入编码器。同理,我们也不是将输入直接送入解码器,而是将其转换为嵌入矩阵,为其添加位置编码,然后再送入解码器。
如图 1-41 所示,假设在时间步,我们将输入转换为嵌入(我们称之为嵌入值输出,因为这里计算的是解码器在以前的步骤中生成的词的嵌入),将位置编码加入其中,然后将其送入解码器。
图 1-41 带有位置编码的编码器和解码器
接下来,让我们深入了解解码器的工作原理。一个解码器模块及其所有的组件如图 1-42 所示。
图 1-42 解码器模块
从图 1-42 中可以看到,解码器内部有 3 个子层。
与编码器模块相似,解码器模块也有多头注意力层和前馈网络层,但多了带掩码的多头注意力层。现在,我们对解码器有了基本的认识。接下来,让我们先详细了解解码器的每个组成部分,然后从整体上了解它的工作原理。
1.3.1 带掩码的多头注意力层
以英法翻译任务为例,假设训练数据集样本如图 1-43 所示。
图 1-43 训练数据集样本
图 1-43 所示的数据集由两部分组成:原句和目标句。在前面,我们学习了解码器在测试期间是如何在每个步骤中逐字预测目标句的。
在训练期间,由于有正确的目标句,解码器可以直接将整个目标句稍作修改作为输入。解码器将输入的 <sos> 作为第一个标记,并在每一步将下一个预测词与输入结合起来,以预测目标句,直到遇到 <eos> 标记为止。因此,我们只需将 <sos> 标记添加到目标句的开头,再将整体作为输入发送给解码器。
比如要把英语句子 I am good 转换成法语句子 Je vais bien。我们只需在目标句的开头加上 <sos> 标记,并将 <sos> Je vais bien 作为输入发送给解码器。解码器将预测输出为 Je vais bien <eos>,如图 1-44 所示。
图 1-44 Transformer 的编码器和解码器
为什么我们需要输入整个目标句,让解码器预测位移后的目标句呢?下面来解答。
首先,我们不是将输入直接送入解码器,而是将其转换为嵌入矩阵(输出嵌入矩阵)并添加位置编码,然后再送入解码器。假设添加输出嵌入矩阵和位置编码后得到图 1-45 所示的矩阵。
图 1-45 嵌入矩阵
然后,将矩阵送入解码器。解码器中的第一层是带掩码的多头注意力层。这与编码器中的多头注意力层的工作原理相似,但有一点不同。
为了运行自注意力机制,我们需要创建三个新矩阵,即查询矩阵、键矩阵和值矩阵。由于使用多头注意力层,因此我们创建了个查询矩阵、键矩阵和值矩阵。对于注意力头的查询矩阵 、键矩阵
、键矩阵 和值矩阵
和值矩阵 ,可以通过将分别乘以权重矩阵
,可以通过将分别乘以权重矩阵 、
、 、
、 而得。
而得。
下面,让我们看看带掩码的多头注意力层是如何工作的。假设传给解码器的输入句是 <sos> Je vais bien。我们知道,自注意力机制将一个单词与句子中的所有单词联系起来,从而提取每个词的更多信息。但这里有一个小问题。在测试期间,解码器只将上一步生成的词作为输入。
比如,在测试期间,当时,解码器的输入中只有 [<sos>, Je],并没有任何其他词。因此,我们也需要以同样的方式来训练模型。模型的注意力机制应该只与该词之前的单词有关,而不是其后的单词。要做到这一点,我们可以掩盖后边所有还没有被模型预测的词。
比如,我们想预测与 <sos> 相邻的单词。在这种情况下,模型应该只看到 <sos>,所以我们应该掩盖 <sos> 后边的所有词。再比如,我们想预测 Je 后边的词。在这种情况下,模型应该只看到 Je 之前的词,所以我们应该掩盖 Je 后边的所有词。其他行同理,如图 1-46 所示。
图 1-46 掩码
像这样的掩码有助于自注意力机制只注意模型在测试期间可以使用的词。但我们究竟如何才能实现掩码呢?我们学习过对于一个注意力头的注意力矩阵 的计算方法,公式如下。
的计算方法,公式如下。
计算注意力矩阵的,第 1 步是计算查询矩阵与键矩阵的点积。图 1-47 显示了点积结果。需要注意的是,这里使用的数值是随机的,只是为了方便理解。
图 1-47 查询矩阵与键矩阵的点积
第 2 步是将 矩阵除以键向量维度的平方根。假设图 1-48 是
矩阵除以键向量维度的平方根。假设图 1-48 是 的结果。
的结果。
图 1-48 计算注意力矩阵的第2步
第 3 步,我们对图 1-48 所得的矩阵应用 softmax 函数,并将分值归一化。但在应用 softmax 函数之前,我们需要对数值进行掩码转换。以矩阵的第 1 行为例,为了预测 <sos> 后边的词,模型不应该知道 <sos> 右边的所有词(因为在测试时不会有这些词)。因此,我们可以用 掩盖 <sos> 右边的所有词,如图 1-49 所示。
掩盖 <sos> 右边的所有词,如图 1-49 所示。
图1-49 用掩盖右边的所有词
接下来,让我们看矩阵的第 2 行。为了预测 Je 后边的词,模型不应该知道 Je 右边的所有词(因为在测试时不会有这些词)。因此,我们可以用掩盖 Je 右边的所有词,如图 1-50 所示。
图 1-50 用掩盖 Je 右边的所有词
同理,我们可以用掩盖 vais 右边的所有词,如图 1-51 所示。
图 1-51 用掩盖 vais 右边的所有词
现在,我们可以将 softmax 函数应用于前面的矩阵,并将结果与值矩阵相乘,得到最终的注意力矩阵。同样,我们可以计算个注意力矩阵,将它们串联起来,并将结果乘以新的权重矩阵,即可得到最终的注意力矩阵 ,如下所示。
,如下所示。
最后,我们把注意力矩阵送到解码器的下一个子层,也就是另一个多头注意力层。下面将详细讲解它的实现原理。
1.3.2 多头注意力层
图 1-52 展示了 Transformer 模型中的编码器和解码器。我们可以看到,每个解码器中的多头注意力层都有两个输入:一个来自带掩码的多头注意力层,另一个是编码器输出的特征值。
图 1-52 编码器与解码器的交互
让我们用来表示编码器输出的特征值,用来表示由带掩码的多头注意力层输出的注意力矩阵。由于涉及编码器与解码器的交互,因此这一层也被称为编码器−解码器注意力层。
让我们详细了解该层究竟是如何工作的。多头注意力机制的第1步是创建查询矩阵、键矩阵和值矩阵。我们已知可以通过将输入矩阵乘以权重矩阵来创建查询矩阵、键矩阵和值矩阵。但在这一层,我们有两个输入矩阵:一个是(编码器输出的特征值),另一个是(前一个子层的注意力矩阵)。应该使用哪一个呢?
答案是:我们使用从上一个子层获得的注意力矩阵创建查询矩阵,使用编码器输出的特征值创建键矩阵和值矩阵。由于采用多头注意力机制,因此对于头,需做如下处理。
键矩阵和值矩阵通过将编码器输出的特征值分别与权重矩阵、相乘来创建,如图 1-53 所示。
图 1-53 创建查询矩阵、键矩阵和值矩阵
为什么要用计算查询矩阵,而用计算键矩阵和值矩阵呢?因为查询矩阵是从求得的,所以本质上包含了目标句的特征。键矩阵和值矩阵则含有原句的特征,因为它们是用计算的。为了进一步理解,让我们来逐步计算。
第 1 步是计算查询矩阵与键矩阵的点积。查询矩阵和键矩阵如图 1-54 所示。需要注意的是,这里使用的数值是随机的,只是为了方便理解。
图 1-54 查询矩阵和键矩阵
图 1-55 显示了查询矩阵与键矩阵的点积结果。
图 1-55 查询矩阵与键矩阵的点积
通过观察图 1-55 中的矩阵,我们可以得出以下几点。
从矩阵的第1行可以看出,其正在计算查询向量(<sos>)与所有键向量(I)、(am)和(good)的点积。因此,第1行表示目标词<sos>与原句中所有的词(I、am和good)的相似度。
同理,从矩阵的第2行可以看出,其正在计算查询向量(Je)与所有键向量(I)、(am)和(good)的点积。因此,第 2 行表示目标词 Je 与原句中所有的词(I、am 和 good)的相似度。
同样的道理也适用于其他所有行。通过计算,可以得出查询矩阵(目标句特征)与键矩阵(原句特征)的相似度。
计算多头注意力矩阵的下一步是将除以,然后应用 softmax 函数,得到分数矩阵 。
。
接下来,我们将分数矩阵乘以值矩阵,得到 ,即注意力矩阵,如图 1-56 所示。
,即注意力矩阵,如图 1-56 所示。
图 1-56 计算注意力矩阵
假设计算结果如图 1-57 所示。
图 1-57 注意力矩阵的结果
目标句的注意力矩阵是通过分数加权的值向量之和计算的。为了进一步理解,让我们看看 Je 这个词的自注意力值是如何计算的,如图 1-58 所示。
图 1-58 Je 的自注意力值
Je 的自注意力值是通过分数加权的值向量之和求得的。因此,的值将包含 98% 的值向量(I)和 2% 的值向量(am)。这个结果可以帮助模型理解目标词 Je 指代的是原词 I。
同样,我们可以计算出个注意力矩阵,将它们串联起来。然后,将结果乘以一个新的权重矩阵,得出最终的注意力矩阵,如下所示。
将最终的注意力矩阵送入解码器的下一个子层,即前馈网络层。下面,我们了解一下解码器的前馈网络层是如何实现的。
1.3.3 前馈网络层
解码器的下一个子层是前馈网络层,如图 1-59 所示。
图 1-59 解码器模块
解码器的前馈网络层的工作原理与我们在编码器中学到的完全相同,因此这里不再赘述。下面来看叠加和归一组件。
1.3.4 叠加和归一组件
和在编码器部分学到的一样,叠加和归一组件连接子层的输入和输出,如图 1-60 所示。
图 1-60 带有叠加和归一组件的解码器模块
下面,我们了解一下线性层和 softmax 层。
1.3.5 线性层和 softmax 层
一旦解码器学习了目标句的特征,我们就将顶层解码器的输出送入线性层和 softmax 层,如图 1-61 所示。
图 1-61 线性层和 softmax 层
线性层将生成一个 logit3 向量,其大小等于原句中的词汇量。假设原句只由以下 3 个词组成:vocabulary = {bien, Je, vais}
那么,线性层返回的 logit 向量的大小将为 3。接下来,使用 softmax 函数将 logit 向量转换成概率,然后解码器将输出具有高概率值的词的索引值。让我们通过一个示例来理解这一过程。
假设解码器的输入词是 <sos> 和 Je。基于输入词,解码器需要预测目标句中的下一个词。然后,我们把顶层解码器的输出送入线性层。线性层生成 logit 向量,其大小等于原句中的词汇量。假设线性层返回如下 logit 向量:logit = [45, 40, 49]。
最后,将 softmax 函数应用于 logit 向量,从而得到概率。
prob = [0.018, 0.000, 0.981]
从概率矩阵中,我们可以看出索引 2 的概率最高。所以,模型预测出的下一个词位于词汇表中索引 2 的位置。由于 vais 这个词位于索引 2,因此解码器预测目标句中的下一个词是 vais。通过这种方式,解码器依次预测目标句中的下一个词。
现在我们已经了解了解码器的所有组件。下面,让我们把它们放在一起,看看它们是如何作为一个整体工作的。
1.3.6 解码器总览
图 1-62 显示了两个解码器。为了避免重复,只有解码器 1 被展开说明。
图 1-62 两个解码器串联
通过图 1-62,我们可以得出以下几点。
-
首先,我们将解码器的输入转换为嵌入矩阵,然后将位置编码加入其中,并将其作为输入送入底层的解码器(解码器 1)。
-
解码器收到输入,并将其发送给带掩码的多头注意力层,生成注意力矩阵。
-
然后,将注意力矩阵和编码器输出的特征值作为多头注意力层(编码器−解码器注意力层)的输入,并再次输出新的注意力矩阵。
-
把从多头注意力层得到的注意力矩阵作为输入,送入前馈网络层。前馈网络层将注意力矩阵作为输入,并将解码后的特征作为输出。
-
最后,我们把从解码器1得到的输出作为输入,将其送入解码器 2。
-
解码器 2 进行同样的处理,并输出目标句的特征。
我们可以将个解码器层层堆叠起来。从最后的解码器得到的输出(解码后的特征)将是目标句的特征。接下来,我们将目标句的特征送入线性层和 softmax 层,通过概率得到预测的词。
现在,我们已经详细了解了编码器和解码器的工作原理。让我们把编码器和解码器放在一起,看看 Transformer 模型是如何整体运作的。
图 1-63 完整地展示了带有编码器和解码器的 Transformer 架构。
图 1-63 Transformer架构
在图 1-63 中, 表示可以堆叠个编码器和解码器。我们可以看到,一旦输入句子(原句),编码器就会学习其特征并将特征发送给解码器,而解码器又会生成输出句(目标句)。
表示可以堆叠个编码器和解码器。我们可以看到,一旦输入句子(原句),编码器就会学习其特征并将特征发送给解码器,而解码器又会生成输出句(目标句)。
我们可以通过最小化损失函数来训练 Transformer 网络。但是,应该如何选择损失函数呢?
我们已经知道,解码器预测的是词汇的概率分布,并选择概率最高的词作为输出。所以,我们需要让预测的概率分布和实际的概率分布之间的差异最小化。要做到这一点,可以将损失函数定义为交叉熵损失函数。我们通过最小化损失函数来训练网络,并使用 Adam 算法来优化训练过程。
另外需要注意,为了防止过拟合,我们可以将 dropout 方法应用于每个子层的输出以及嵌入和位置编码的总和。
在本文中,我们深入解析了 Transformer 模型的工作原理。从基本概念出发,我们首先了解了 Transformer 模型及其基于编码器-解码器架构的设计理念。随后,重点探讨了编码器部分的结构,包括多头注意力层和前馈网络层等核心子层。
通过学习自注意力机制,我们认识到它如何将句子中的每个词与其他词建立联系,从而更全面地理解上下文含义。具体而言,自注意力的计算依赖于查询矩阵、键矩阵和值矩阵的协作。我们还详细研究了位置编码的计算方法,以及它在捕捉句子中词序信息中的重要作用。此外,还解析了前馈网络和叠加归一化组件的功能与实现。
在掌握编码器原理后,我们进一步学习了解码器的运行机制,深入分析了其三个关键子层:带掩码的多头注意力层、多头注意力层(编码器-解码器注意力层)和前馈网络层。最后,我们总结了编码器与解码器如何协同构建完整的 Transformer 模型,并探讨了训练 Transformer 网络的具体方法。
这篇文章系统性地梳理了 Transformer 的核心原理,为深入理解这一模型奠定了坚实基础。
这本书虽然是讲解 Bert,但它把 Transformer 讲的很透彻。作者还介绍了十余种 BERT 变体的原理,本书聚焦谷歌公司开发的 BERT 自然语言处理模型,由浅入深地介绍了 BERT 的工作原理、BERT 的各种变体及其应用,书中用简单的文字清晰阐释 BERT 背后的复杂原理,让你轻松上手 NLP 领域的里程碑式模型。
2 小时上手大模型开发!大模型应用开发极简指南:了解 GPT-4 和 ChatGPT 的工作原理,快速构建大模型应用并实践提示工程、模型微调、插件、LangChain 等,送配套代码。大模型一线创业者、应用技术专家联袂推荐:宝玉、张路宇、孙志岗、邓范鑫、梁宇鹏(@一乐)、罗云、宜博。
OpenAI CEO,ChatGPT 之父山姆·阿尔特曼推荐,国内首部由世界顶级 AI 学者、科学和技术领域重要的革新者、“第一个真正实用的人工智能”搜索引擎 WolframAlpha 发明人斯蒂芬·沃尔弗拉姆对 ChatGPT 最本质的原理的解释的权威之作!
本书围绕一个真实的案例展开,完整记录了一个融合专业技能和大模型能力的软件开发过程,真正从 0 到 1,介绍如何基于坚实的专业基础,借助大模型,实现从业务探索、需求分析、架构设计、编码实现到上线运行的完整过程,展示了大模型支持端到端软件开发的可行性。
深度学习“鱼书”,畅销 10 万册,相比 AI 圣经“花书”,本书更合适入门。本书深入浅出地剖析了深度学习的原理和相关技术,书中使用 Python 3,尽量不依赖外部库或工具,从基本的数学知识出发,带领读者从零创建一个经典的深度学习网络,使读者在此过程中逐步理解深度学习。
深度学习入门全套 GET 👇
学习技术不孤单,扫一扫入群,一起进步~


 ;
;









