港大等发布深度伪造检测综述,聚焦可靠性,探讨迁移性、可解释性、鲁棒性三大挑战,并提出新的评估方法。
原文标题:ACM Computing Surveys | 港大等基于可靠性视角的深度伪造检测综述,覆盖主流基准库、模型
原文作者:机器之心
冷月清谈:
这篇由港大、齐鲁工大、湖南大学、圭尔夫大学联合发布的综述,从可靠性角度探讨了深度伪造检测的现状和挑战。文章回顾了主流的深度伪造基准数据库和检测模型,并提出了迁移性、可解释性和鲁棒性三大核心挑战。
迁移性方面,理想的检测模型应能适应新的数据和篡改算法,避免重复训练。可解释性方面,模型需要提供易于理解的证据,方便非专业人士使用。鲁棒性方面,模型需要抵抗画质损失和人为噪声干扰,保持检测准确性。
文章提出了一种受司法鉴定启发的可靠性评估方法,模拟真实世界场景,用统计学方法评估模型性能,为法庭审判提供潜在证据。实验部分,文章复现了七个深度伪造检测模型,并在不同条件下进行可靠性分析,并将这些模型应用于实际案例,验证了其有效性。
实验结果表明,现有模型在三大挑战方面各有优势,但难以同时兼顾。文章指出,一个可靠的深度伪造检测模型应该兼具良好的迁移性、可解释性和鲁棒性,为受害者提供更全面的隐私保护。
迁移性方面,理想的检测模型应能适应新的数据和篡改算法,避免重复训练。可解释性方面,模型需要提供易于理解的证据,方便非专业人士使用。鲁棒性方面,模型需要抵抗画质损失和人为噪声干扰,保持检测准确性。
文章提出了一种受司法鉴定启发的可靠性评估方法,模拟真实世界场景,用统计学方法评估模型性能,为法庭审判提供潜在证据。实验部分,文章复现了七个深度伪造检测模型,并在不同条件下进行可靠性分析,并将这些模型应用于实际案例,验证了其有效性。
实验结果表明,现有模型在三大挑战方面各有优势,但难以同时兼顾。文章指出,一个可靠的深度伪造检测模型应该兼具良好的迁移性、可解释性和鲁棒性,为受害者提供更全面的隐私保护。
怜星夜思:
1、除了文中提到的三个挑战,大家觉得深度伪造检测还有什么其他重要的挑战?
2、文中提到的可靠性评估方法,大家觉得在实际应用中有哪些局限性?
3、对于普通用户来说,如何有效地识别深度伪造内容?
2、文中提到的可靠性评估方法,大家觉得在实际应用中有哪些局限性?
3、对于普通用户来说,如何有效地识别深度伪造内容?
原文内容
![]()
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者包括香港大学的王天一、Kam Pui Chow,湖南大学的廖鑫 (共同通讯),圭尔夫大学的林晓东和齐鲁工业大学 (山东省科学院) 的王英龙 (第一通讯)。
基于深度神经网络对人脸图像进行编辑和篡改,深度伪造的发展为人们的生活带来了便利,但对其错误的应用也同时危害着人们的隐私和信息安全。
近年来,针对深度伪造对人们隐私安全造成的危害,虽然领域内的研究者们提出了基于不同角度和不同算法的检测手段,但是在实际的深度伪造相关案例中,鲜有检测模型被成功应用于司法判决,并真正做到保障人们的隐私安全。
近日,一篇基于可靠性视角的深度伪造检测综述收录在 ACM Computing Surveys (IF=23.8)。文章作者分析,在当前深度伪造领域内的研究中,尚缺乏一条完整的桥梁,可以将成熟的深度伪造检测模型与其在实际案例中的潜在应用联系起来。

-
论文标题:Deepfake Detection: A Comprehensive Survey from the Reliability Perspective
-
arXiv 地址: https://arxiv.org/abs/2211.10881
本综述由香港大学、齐鲁工业大学、湖南大学、圭尔夫大学联合发布,从可靠性的角度全面回顾了当前领域内的常用深度伪造基准数据库 (表 1) 和代表性检测模型,并基于现有检测模型的类型和优缺点,提出了三个值得领域内研究者们持续探索的话题和挑战 (图 1):迁移性、可解释性和鲁棒性。
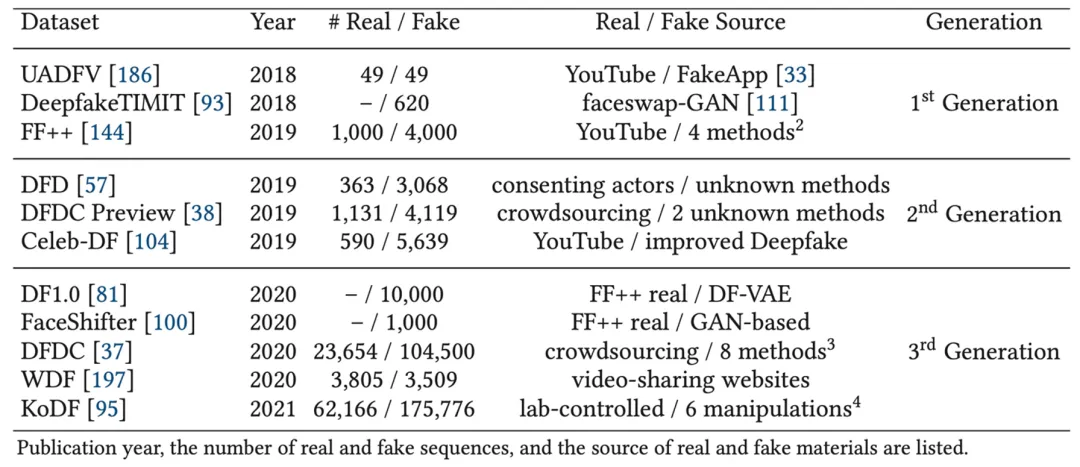
表 1: 依据质量、多样性、难度等特点而划分的三代深度伪造基准数据库信息。
三大话题和挑战
迁移性话题关注已完成训练的深度伪造检测模型是否能够在未曾见过的数据和篡改算法上依然维持令人满意的检测准确率。
详细来说,当一个深度伪造检测器在被广泛使用的 FaceForensics++ 数据集上完成训练后,除了在 FaceForensics++ 的测试集上展现出色的检测准确率,仍需要能够在 cross-dataset 和 cross-manipulation 设定下,维持较为稳定的效果。此目标旨在避免针对持续迭代出现的新的伪造数据和伪造算法时无休止地增加模型训练成本。
可解释性话题侧重于检测模型在判断真伪的同时能否额外提供令人信服的证据和通俗易懂的解释。
详细来说,当一个深度伪造检测器判断一张图片的真伪时,通常只能提供对其真或假的判断结论,以及在各个实验数据集上测试时的检测准确率。然而,对于需要依赖于检测模型来保护个人隐私信息的非专业人士,能够提供除准确率指标之外通俗易懂的额外证据 (例如,被标记的伪造区域定位或被可视化的伪造痕迹和噪声) 是极其重要的。
鲁棒性话题则基于已有的客观模型检测效果,着眼于实际生活场景,关注深度伪造素材在传播中遭受主观和客观画质损失后,是否依然可以被检测器正确判断。
详细来说,深度伪造素材的危害随着其在网络中的持续性传播而不断增加,而在上传、下载、转载等传播过程中,受不同平台对素材属性的限制和协议要求,该素材将不可避免地遭受质量上的折损和降低。另一方面,当攻击者 (即深度伪造素材的制造者) 已知领域内已有针对各类深度伪造算法的检测手段时,其会刻意向伪造的素材内有针对性地添加能够一定程度上扰乱深度伪造检测器的噪声。以上两类情况,都需要依赖于深度伪造检测模型的鲁棒性,从而可以持续地在实际生活案例中发挥作用。
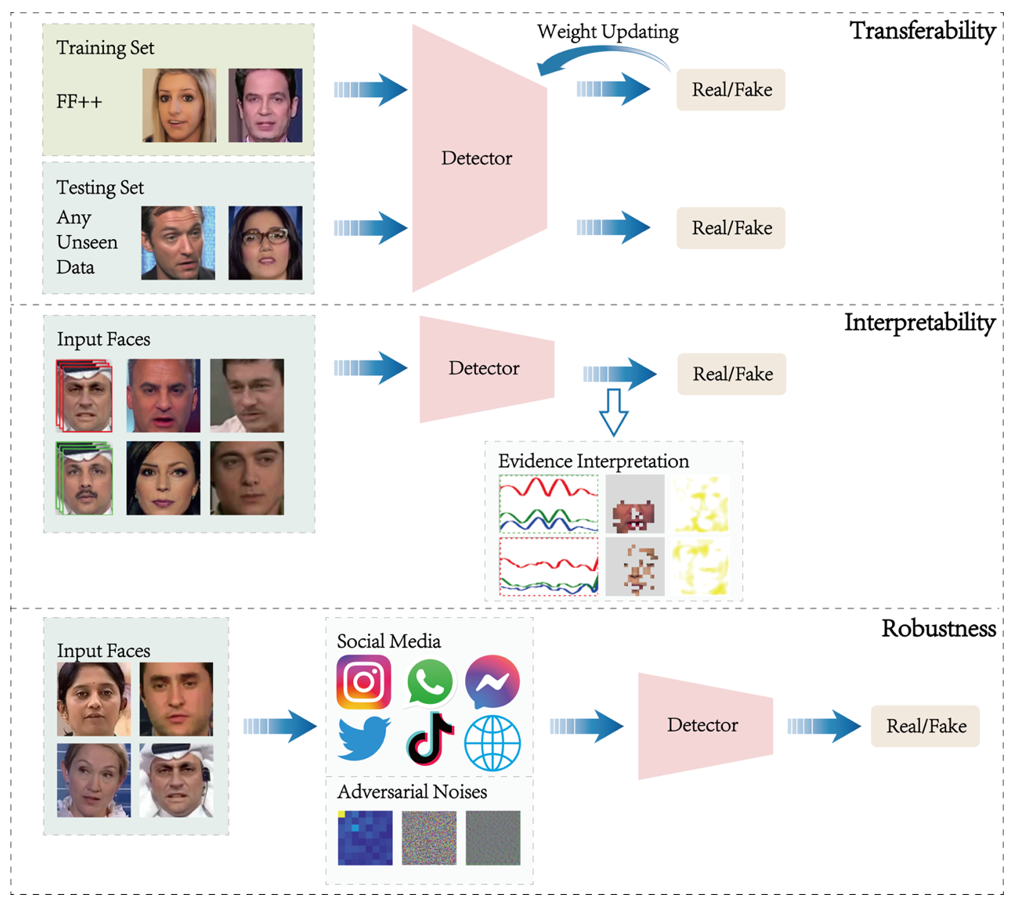
图 1 : 关于三种话题和挑战的阐述
评估与实验
除了深入探讨三个话题和挑战的意义以及综述性地总结领域内的相关工作之外,本文还着重提出了一个针对模型可靠性的评估方法 (图 2)。
该方法受到司法鉴定中对 DNA 比对过程的启发,通过模拟和构建真实世界中的深度伪造数据的总 population,引入统计学中随机采样的方法,科学且严谨地评估深度伪造检测模型的可靠性,从而提供关于模型性能的统计学指标,以作为法庭审判的潜在证据和辅助证据。基于该指标,可得出在不同置信度条件下的模型检测准确率结论。该可靠性评估方法的初步探索,旨在提供一条路线可以使众多深度伪造检测模型能够在实际生活案例中真正发挥价值。
同时,该综述通过进行大量实验,在不同的样本集大小、置信度、采样次数等环境设定下,对为解决三种话题和挑战的七个深度伪造检测模型进行模型复现和可靠性分析。

图 2: 深度伪造检测模型可靠性分析算法。
此外,该综述将实验中的深度伪造检测模型应用在受害者分别为明星、政客、普通人的实际深度伪造案例中的假视频进行鉴伪和分析,并针对检测结果提供基于特定置信度条件下的模型检测准确率结论 (图 3)。
实验结果表明,当前领域内的现存深度伪造检测模型分别在迁移性、可解释性、鲁棒性话题方面各有建树,但当令其兼顾两个或三个话题和挑战时,在模型效果上则展现出了显著的权衡和取舍。
然而,通常来说,人们希望,一个可靠的深度伪造检测模型应同时具备良好的迁移性、通俗易懂的可解释性、稳定的鲁棒性,以便能够在实际生活中的深度伪造案例中保护和保障受害者的隐私安全。
因此,本综述论文所总结的理念、发现、结论也为深度伪造检测领域的研究者们提供了新的研究挑战与研究方向。
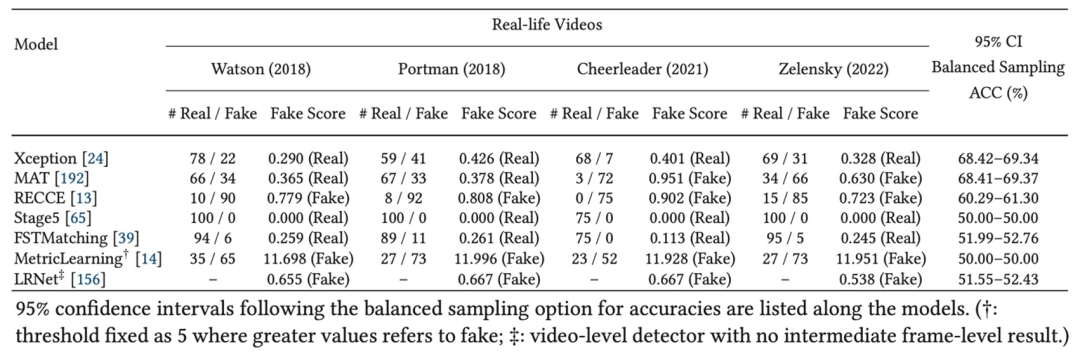
图 3: 深度伪造检测模型在四个实际案例中的视频上的检测结果以及其对应的 95% 置信度可靠性结论。
第一作者信息
王天一,本科毕业于美国华盛顿大学西雅图分校,修习计算机科学和应用数学双专业;博士毕业于香港大学,研究方向为多媒体取证;现为南洋理工大学在职博士后研究员。

引用信息
Tianyi Wang, Xin Liao, Kam Pui Chow, Xiaodong Lin, and Yinglong Wang. 2024. Deepfake Detection: A Comprehensive Survey from the Reliability Perspective. ACM Comput. Surv. 57, 3, Article 58 (March 2025), 35 pages. https://doi.org/10.1145/3699710
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com