OpenAI o1 给大模型规模扩展 vs 性能的曲线带来了一次上翘。它在大模型领域重现了当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。
但这种突破背后是庞大的算力支持与推理开销:API 的价格上,o1-preview 每百万输入 15 美元,每百万输出 60 美元,而最新版的 o3 在处理复杂推理任务时,单次成本更是高达数千美元。
业界一直在寻找一个更经济、更高效的解决方案。而这个答案可能比预期来得更快一些。
今天登顶 Hugging Face 热门榜一的论文展示了小模型的潜力。来自微软亚洲研究院的研究团队提出了 rStar-Math。rStar-Math 向我们证明,1.5B 到 7B 规模的小型语言模型(SLM)无需从更大模型蒸馏,就能在数学推理能力上媲美甚至超越 OpenAI o1。
-
论文标题:rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
-
论文链接:https://arxiv.org/pdf/2501.04519
-
Github 链接:https://github.com/microsoft/rStar(即将开源)
经过 4 轮自我进化,吸纳了 747k 数学问题合成的数百万数据,rStar-Math 将 SLM 的数学推理能力提升到了最先进水平。
例如,在 MATH 基准测试上,它将 Qwen2.5-Math-7B 的成绩从 58.8% 提升到了 90.0%,将 Phi3-mini-3.8B 的正确率从 41.4% 提升到了 86.4%,分别超过了 o1-preview 4.5% 和 0.9%。
拉到美国数学奥林匹克(AIME)的考场上,15 道题,rStar-Math 能够做对 8 道,在最优秀的高中数学竞赛生中也能排到前 20%。
更重要的是,他们只花了 60 块 A100 就达到了如此效果,项目和代码即将开源。
AI 投资人 Chetan Puttagunta 锐评:「对创业公司来说,这将是一个绝佳的机会!」
当如此强大的推理能力可以用更低的成本实现时,Keras 创始人 François Chollet 也感叹道:「2025 年将是开源 o3 复刻之年。」
学术圈的人对 rStar-Math 的欣赏,表达起来就直白多了:
发布不到 20 个小时,甚至就已经有人专门做了一期视频来深度解读。
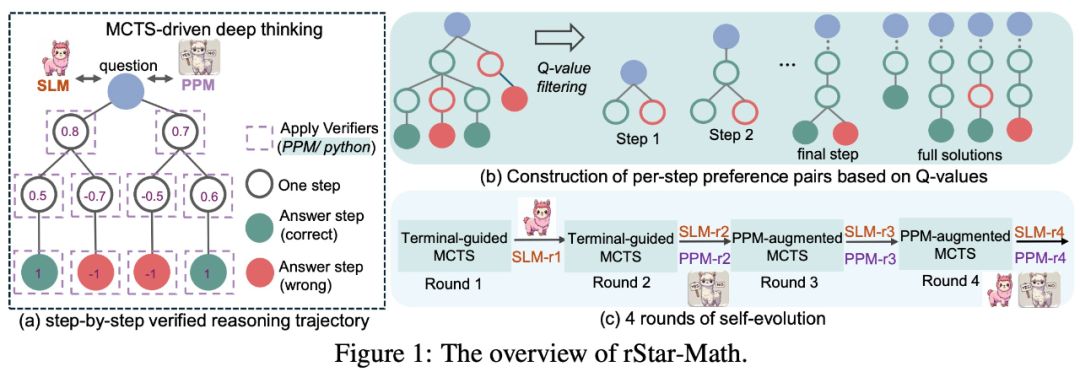
从技术层面来说,rStar-Math 引入了一种可以自己进化的 System 2 推理方法,通过蒙特卡洛树搜索(MCTS)来实现「深度思考」能力。在测试阶段,它会在奖励模型的指导下,让数学策略模型进行搜索推理。
具体来看,在 MCTS 中,数学问题求解被分解为多步生成。每一步都将作为策略模型的 SLM 采样候选节点。每个节点生成一步 CoT 和相应的 Python 代码。为验证生成质量,只保留 Python 代码执行成功的节点,从而减少中间步骤的错误。
此外,大量 MCTS rollout 基于每个中间步骤的贡献自动分配 Q 值:对正确答案贡献更多的步骤获得更高 Q 值,被认为质量更高。这确保了 SLM 生成的是正确、高质量的推理轨迹。
由于 rStar-Math 的总体架构涉及两个 SLM,一个是数学策略模型,一个是奖励模型,该团队引入了三个关键创新:
-
创新的代码增强 CoT 数据合成方法,通过大量 MCTS rollout 生成经过验证的逐步推理轨迹,用于训练策略 SLM;
-
过程奖励模型训练方法也有所改进,避免了简单的步级分数标注,提升了过程偏好模型(PPM)的评估效果;
-
模型会自我进化,采用完全自主训练方案,从零开始构建并训练模型,通过持续的迭代优化来不断提升推理能力。
方法
该研究的目标是训练数学策略 SLM 和过程奖励模型 (PRM),并将两者集成到蒙特卡罗树搜索 (MCTS) 中以实现 System 2 深度思考。
选择 MCTS 有两个主要原因。
首先,它将复杂的数学问题分解为更简单的单步生成任务,与 Best-of-N 或 self-consistency 等其他 System 2 方法相比,MCTS 降低了策略 SLM 的难度。
其次,MCTS 中的逐步生成会自然产生两个模型的 step-level 训练数据。标准 MCTS rollout 会根据每个步骤对最终正确答案的贡献自动为每个步骤分配 Q 值,从而无需人工生成步骤级注释来进行过程奖励模型训练。
理想情况下,GPT-4 等高级 LLM 可以集成到 MCTS 中以生成训练数据。然而,这种方法面临两个关键挑战。首先,即使是强大的模型也难以持续解决难题,例如奥林匹克级别的数学问题。
因此,生成的训练数据将主要由更简单的可解决问题组成,限制了其多样性和质量。
其次,注释每步 Q 值需要广泛的 MCTS 部署;树探索(tree exploration)不足可能会导致虚假的 Q 值分配,例如高估次优步骤。鉴于每次 rollout 都涉及多个单步生成,并且这些模型的计算成本很高,因此增加 rollout 会显著提高推理成本。
为此,该研究探索使用两个 7B SLM(策略 SLM 和 PRM)来生成更高质量的训练数据,其较小的模型大小允许在可访问的硬件(例如 4×40GB A100 GPU)上广泛部署 MCTS。
然而,由于自生成数据的能力较弱,SLM 经常无法生成正确的解决方案,即使最终答案正确,中间步骤也常常存在缺陷或质量较差。此外,与 GPT-4 等高级模型相比,SLM 解决的挑战性问题较少。
如图 1 所示,为了减少错误和低质量的中间步骤,该研究提出了一种代码增强的 CoT 合成方法,该方法执行广泛的 MCTS 部署以生成逐步验证的推理轨迹,用 Q 值注释。
为了进一步提高 SLM 在挑战性问题上的性能,该研究提出了四轮自进化方案。在每一轮中,策略 SLM 和奖励模型都会更新为更强的版本,逐步解决更困难的问题并生成更高质量的训练数据。
最后,该研究提出了一种新颖的流程奖励模型训练方法,无需精确的每步奖励注释,从而产生更有效的流程偏好模型(PPM)。
实验评估
该团队在多个数学数据集上对 rStar-Math 进行了评估,并与多个模型进行了对比。具体设置请参阅原论文,这里我们主要来看研究结果。
主要结果
表 5 展示了 rStar-Math 与其它 SOTA 推理模型在不同的数学基准上的结果。
基于这些结果,该团队得出了三点观察:
-
rStar-Math 显著提高了小语言模型(SLM)的数学推理能力,在模型规模显著缩小(1.5B-7B)的情况下,其性能可媲美甚至超越 OpenAI o1。
-
尽管使用了较小的策略模型(1.5B-7B)和奖励模型(7B),rStar-Math 的表现仍明显优于最先进的 System 2 基线。
-
除了 MATH、GSM8K 和 AIME 等可能存在过度优化风险的知名基准之外,rStar-Math 在其他具有挑战性的数学基准上表现出很强的通用性,包括 Olympiad Bench、College Math 和 Chinese College Entrance Math Exam(Gaokao),创下了新的最高分。
扩展测试时间计算。rStar-Math 使用了 MCTS 来增强策略模型,在 PPM 的引导下搜索问题的解。通过增加测试时间计算,它可以探索更多轨迹,从而可能实现性能提升。
在图 3 中,该团队通过比较官方 Qwen Best-of-N 在四个高难度数学基准上不同数量的采样轨迹的准确度,展示了测试时间计算扩展的影响。
消融研究和分析
该团队也进行了消融研究,证明了三项创新的有效性。
自我进化的有效性。表 5 展示了经过 4 轮 rStar-Math 自我进化深度思考后得到的结果。可以看到,表现很不错。
表 6 给出了每一轮的数学推理性能,可以明显看到其准确度在不断提高。
表 7 则展示了在不同数据集上微调的 Qwen2.5-Math-7B 的数学推理准确度。
该团队给出了两项重要观察:
-
使用新提出的逐步验证的轨迹进行微调明显优于所有其他基线。这主要归功于用于代码增强型 CoT 合成的 PPM 增强型 MCTS,它能在数学解答生成期间提供更密集的验证。
-
使用该团队的小语言模型,即使随机采样代码增强型 CoT 解答,得到的结果也可媲美或优于 GPT-4 合成的 NuminaMath 和 MetaMath 数据集。这表明,经过几轮自我进化后,新的策略 SLM 可以生成高质量的数学解答。这些结果证明新方法在不依赖高级 LLM 蒸馏的情况下,就具备自我生成更高质量推理数据的巨大潜力。
另外,在最后一轮策略模型的基础上,该团队比较了 ORM、PQM 和 PPM 在 System 2 推理上的性能。结果见表 8。
可以看到,PQM 和 PPM 都优于 ORM,因为它们可提供更密集的步骤级奖励信号,从而在复杂的数学推理任务上获得更高的准确度。然而,由于 Q 值固有的不精确性,PQM 在更难的基准测试(例如 MATH 和 Olympiad Bench)上表现不佳。相比之下,PPM 构建了步骤级偏好数据进行训练,使该团队的 7B 策略模型在所有基准测试中都能够实现与 o1-mini 相当或更优的性能。
发现与讨论
模型出现自我反思能力
OpenAI o1 的一个重要突破是它能自省。当它出错时,o1 能识别错误并自我纠正。这在开源 LLM 中一直难以实现。在实验中,该团队意外发现 MCTS 驱动的深度思考展现出了反思能力。如图 4 所示,模型最初在前三步使用 SymPy 形式化方程会写出错误答案(左分支)。
在我们的实验中,我们意外地观察到我们的 MCTS 驱动的深度思考在解决问题过程中表现出自反思。如图 4 所示,模型最初在前三步使用 SymPy 形式化方程,这将导致答案错误 (左分支)。
但在第四步,模型就识别出了前几步的问题(右分支),并主动回溯采用更简单的方法重新求解,最终得到正确答案。
值得注意的是,这种自反思能力是在没有专门训练和提示的情况下自发产生的,表明高级 System 2 推理可以自然培养出内在的自省能力。
PPM 塑造 System 2 深度思考的推理边界
策略模型和奖励模型对 System 2 深度推理都至关重要。实验表明,一旦策略模型达到相当强的能力水平,PPM 就成为决定性能上限的关键。
如下图 5 所示,通过加入 System 2 推理机制,即使是 Phi3.8B 这样的小模型也能获得显著性能提升,在多个数学基准测试中的准确率提高了约 20-30 个百分点。这表明,奖励模型(而不是基础模型的大小)才是决定最终性能的关键因素。
更多研究细节,请参阅论文原文。
参考链接:
https://arxiv.org/pdf/2501.04519
https://www.reddit.com/r/MachineLearning/comments/1hxk2ab/r_rstarmath_small_llms_can_master_math_reasoning/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com