YOLO-World结合YOLOv8和CLIP,实现快速开集目标检测,可自定义词汇表。
原文标题:YOLO-World开集目标检测,可直接上手
原文作者:数据派THU
冷月清谈:
YOLO-World是一个基于YOLOv8的开集目标检测框架,结合了YOLO系列的轻量、快速和高性能的特点,以及CLIP文本嵌入模块的优势。
安装过程包括安装Ultralytics库和CLIP库。可以使用pip install ultralytics安装或更新Ultralytics库,并使用pip install openai-clip安装CLIP库。
YOLO-World模型可以直接下载使用,例如yolov8s-world.pt。用户可以根据需要选择不同的预训练模型。
在推理过程中,可以不指定词汇表直接进行推理,也可以指定词汇表进行推理。指定词汇表时,CLIP会将词汇嵌入转换为文本特征向量,与图像一起进行推理。
代码示例演示了如何使用set_classes()方法设置词汇表,并进行目标检测。实验证明,YOLO-World的推理速度非常快,符合YOLO系列的特性。
安装过程包括安装Ultralytics库和CLIP库。可以使用pip install ultralytics安装或更新Ultralytics库,并使用pip install openai-clip安装CLIP库。
YOLO-World模型可以直接下载使用,例如yolov8s-world.pt。用户可以根据需要选择不同的预训练模型。
在推理过程中,可以不指定词汇表直接进行推理,也可以指定词汇表进行推理。指定词汇表时,CLIP会将词汇嵌入转换为文本特征向量,与图像一起进行推理。
代码示例演示了如何使用set_classes()方法设置词汇表,并进行目标检测。实验证明,YOLO-World的推理速度非常快,符合YOLO系列的特性。
怜星夜思:
1、YOLO-World相比其他开集目标检测方法有哪些优势?
2、CLIP在YOLO-World中扮演什么角色?能否替换成其他文本编码器?
3、YOLO-World的未来发展方向有哪些?
2、CLIP在YOLO-World中扮演什么角色?能否替换成其他文本编码器?
3、YOLO-World的未来发展方向有哪些?
原文内容

来源:机器学习AI算法工程本文约1200字,建议阅读5分钟
本文介绍了YOLO-World开集目标检测。
1. 前言
关于Demo:尽管YOLO-World官方给出了在线试用的Demo:https://huggingface.co/spaces/stevengrove/YOLO-World
但还是不如在自己电脑上离线运行一遍来得直接。恰好,近期Ultralytics(YOLOv8)也新增了对YOLO-World的支持,我们不如直接体验一把。
关于YOLO-World:
其是一个使用开放词汇进行目标检测的新框架,且是以YOLOv8框架为detector,所以其特点就继承了YOLO系列,也即轻量、快速、性能好。另外,既然是文本和图片一起作为输入,那么就需要有一个文本embedding的模块,这里用的是CLIP,其将用户输入的词汇列表转换为特征向量,与输入图像一起进行推理。
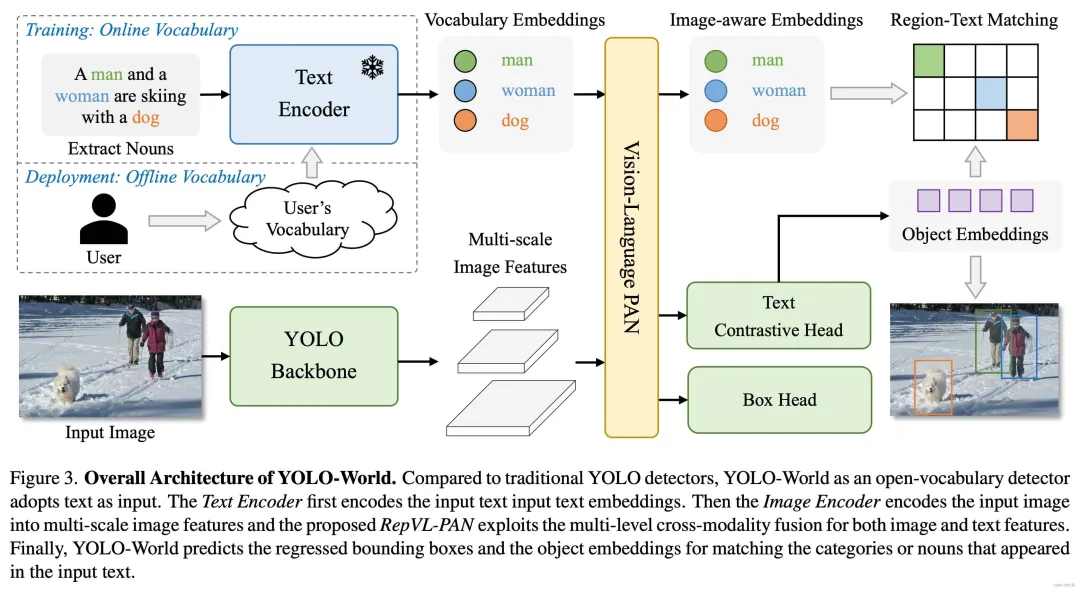
2. 安装(更新)
由于YOLO-World主要包括两部分内容:YOLO-style的检测器、用于文本embedding的CLIP。因此,我们需要安装一个Ultralytics库、一个CLIP库。
# 新安装:pip install ultralytics # 已有Ultralytics,
更新:pip install -U ultralyticspip install openai-clip
3. 上手体验
模型下载:
这里选用
yolov8s-world.pt:
https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8s-world.pt
当然,也可以使用其他模型,可自行从Ultralytics的官网下载:。
不设定词汇表,进行推理:
这里没有用到CLIP,因为没有设定词汇,也就不需要进行text embedding了
设定词汇,进行推理:
from ultralytics import YOLOif name == ‘main’:
Initialize a YOLO-World model
model = YOLO(‘yolov8/yolov8s-world.pt’) # or choose yolov8m/l-world.pt
Define custom classes
model.set_classes([“person”])
Execute prediction for specified categories on an image
results = model.predict(‘image_01.jpg’)
Show results
results[0].show()
这里,我们设定了只包括一个词汇的词汇表:["person"],那么自然,我们也可以根据需要设定多个词汇。由于设定了词汇表,所以就会用到CLIP,它会将各个词汇进行嵌入,转换为text feature。
上述代码中用到了set_classes(),其实现如下:
def set_classes(self, text): """Perform a forward pass with optional profiling, visualization, and embedding extraction.""" try: import clip except ImportError: check_requirements("git+https://github.com/openai/CLIP.git") import clip
model, _ = clip.load(“ViT-B/32”)
device = next(model.parameters()).device
text_token = clip.tokenize(text).to(device)
txt_feats = model.encode_text(text_token).to(dtype=torch.float32)
txt_feats = txt_feats / txt_feats.norm(p=2, dim=-1, keepdim=True)
self.txt_feats = txt_feats.reshape(-1, len(text), txt_feats.shape[-1])
self.model[-1].nc = len(text)
运行效果:
["person"]:

["person", "motorcycle"]:

运行过程中,时间消耗也是极小的,这也符合YOLO系列的风格。
Speed: 0.9ms preprocess, 43.5ms inference, 1.1ms postprocess per image at shape (1, 3, 448, 640)
可以预见的是,YOLO-World会是未来实时开放词汇检测领域的一个重量级选手。
