研究表明tokenization策略显著影响LLM的数学能力,单位数tokenization和从右到左(R2L)方法表现最佳。
原文标题:从2019年到现在,是时候重新审视Tokenization了
原文作者:机器之心
冷月清谈:
这篇文章探讨了不同的tokenization策略如何影响大型语言模型(LLM)的数学能力,特别是算术能力。文章指出,传统的BPE算法对数字的编码方式不一致,导致模型在处理数字时出现问题。
文章比较了三种tokenization方法:GPT-2的BPE、Llama 3的三位数和Deepseek的单位数tokenization。结果表明,单位数tokenization在各种算术问题上表现最佳,特别是在复杂问题上。此外,从右到左(R2L)的tokenization方法比从左到右(L2R)的方法表现更好,尤其是在加法运算中。
研究还发现,对于已经训练好的模型,即使不重新训练,只需在推理阶段使用R2L tokenization,也能提高数学性能。
最后,文章总结了不同tokenization方法的优缺点,并建议根据具体问题类型选择合适的策略。对于算术运算,单位数tokenization是最佳选择;如果必须使用三位数tokenizer,则应选择R2L方法。
文章比较了三种tokenization方法:GPT-2的BPE、Llama 3的三位数和Deepseek的单位数tokenization。结果表明,单位数tokenization在各种算术问题上表现最佳,特别是在复杂问题上。此外,从右到左(R2L)的tokenization方法比从左到右(L2R)的方法表现更好,尤其是在加法运算中。
研究还发现,对于已经训练好的模型,即使不重新训练,只需在推理阶段使用R2L tokenization,也能提高数学性能。
最后,文章总结了不同tokenization方法的优缺点,并建议根据具体问题类型选择合适的策略。对于算术运算,单位数tokenization是最佳选择;如果必须使用三位数tokenizer,则应选择R2L方法。
怜星夜思:
1、除了文章中提到的几种方法,还有哪些tokenization策略可以提升LLM的数学推理能力?
2、文章主要关注算术能力,那么tokenization对其他类型的数学推理,比如几何、逻辑推理等,会有什么影响?
3、未来,tokenization技术在提升LLM数学能力方面有哪些发展方向?
2、文章主要关注算术能力,那么tokenization对其他类型的数学推理,比如几何、逻辑推理等,会有什么影响?
3、未来,tokenization技术在提升LLM数学能力方面有哪些发展方向?
原文内容
机器之心报道
编辑:陈陈
2019 年问世的 GPT-2,其 tokenizer 使用了 BPE 算法,这种算法至今仍很常见,但这种方式是最优的吗?来自 HuggingFace 的一篇文章给出了解释。
「9.9 和 9.11 到底哪个大?」这个问题一度难坏了各家大模型。
关于模型为什么会答错,研究人员给出了各种猜测,包括预训练数据的构成和模型架构本身。
在一篇新博客中,来自 HuggingFace 的研究者讨论了可能造成这一问题的原因之一 ——tokenization,并重点分析了它如何影响模型的数学能力,尤其是算术能力。
回顾 Tokenization
早在 2019 年,GPT-2 论文就详细介绍了将 BPE(byte-pair encoding)用于语言模型的 tokenization 方法。此方法的工作原理是将频繁出现的子词合并为单个单元,直到词汇量达到目标大小。
然而,这种做法生成的词汇表在很大程度上取决于输入到 tokenizer 中的训练数据,从而导致了在数字编码方式上的不一致性。例如,在训练数据中常见的数字(例如 1-100、1943 年这样的表示)很可能被表示为单个 token,而较少见到的数字则被拆分成多个 token,如下所示:

四年后,Llama 系列来了!Llama 和 Llama 2 使用 SentencePiece (一个用于基于文本生成的无监督文本 tokenizer )的 BPE 实现,并对数字进行了显著的调整:它们将所有数字拆分为单个数字。这意味着只有 10 个唯一 token(0-9)来表示任何数字,从而简化了 LLM 的数字表示。Deepseek 后来发布了一个模型 (DeepSeek-V2),它有一个类似的单位数(single-digit)的 tokenizer 。
后来,Llama 3 采用了不同的方法来处理数字,将它们 tokenizing 为三位数。因此,从 1 到 999 的数字每个数都有唯一的 token,而从 1000 开始的数字由这些 token 组成。
一个新的范式:从右到左的 Tokenization
到目前为止,我们所看到的 tokenization 方法都是从左到右处理文本的。例如,如果三位数字的分词法遇到序列 12345,它将从开头扫描,将其分解为 123 和 45 这样的片段。
与从左到右(L2R)的分词方法不同,从右到左(R2L)的分词方法以三个字符为一组,从文本的末尾开始向开头处理。使用 R2L 分词,序列 12345 将通过从右侧扫描进行分词,首先分割出 345,然后再处理 12。最近,一些前沿的闭源模型也在探索使用这种 R2L 分词方法,这已经被证明对某些算术运算有益,因为 R2L 表示可以防止操作数的错位。还有传言称 Claude 使用了这种 R2L 分词方法。
为了更好地理解错位是什么样子的,让我们以 3789 + 8791 为例:

如上所示,在三位数从左到右(L2R)的例子中,9 + 1 应该映射到数字 0,但实际上却与 8 组合在一起形成了 80,因为前面的三个 token(125)已经被分在一起了。tokenization 边界的偏移在学习过程中引入了额外的复杂性,已经证明准确性是有害的。
而在从右到左(R2L)的例子中,数字 580 和对应的子操作数 789 和 791 很好地对齐了。
以下是用于处理数字 tokenization 的技术概述:
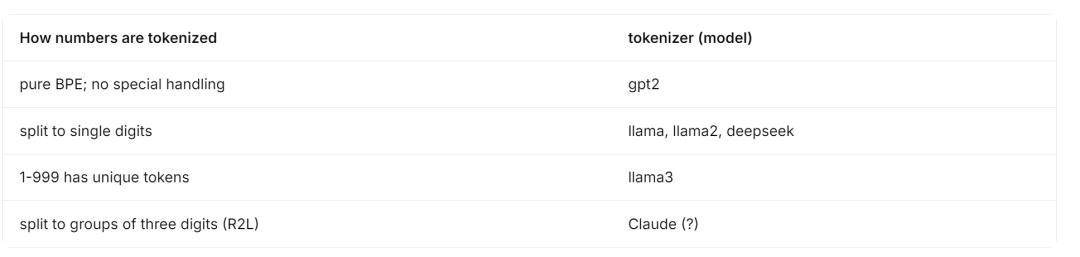
不同方法的比较
该研究旨在比较多个 tokenizer 以及它们处理数字的不同方式,以尽量减少模型架构、训练配置和预训练数据等外部因素在评估结果中的影响。因此,每个模型之间唯一的区别应该是 tokenizer。
实验选择了 3 种 tokenizer,分别是 GPT-2 的 BPE tokenizer、Llama 3 的三位数 tokenizer(three-digit tokenizer)和 Deepseek 的单位数 tokenizer(single-digit tokenizer)。
from transformers import AutoTokenizer from tokenizers import pre_tokenizers, RegexInitialize all tokenizers
tokenizer = AutoTokenizer.from_pretrained (“meta-llama/Meta-Llama-3-8B”)
Add an extra step to the existing pre-tokenizer steps
tokenizer._tokenizer.pre_tokenizer = pre_tokenizers.Sequence (
[Added step: split by R2L digits
pre_tokenizers.Split (pattern = Regex (r"\d {1,3}(?=(\d {3})*\b)"),
behavior=“isolated”, invert = False),Below: Existing steps from Llama 3’s tokenizer
pre_tokenizers.Split (pattern=Regex (r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p {L}\p {N}]?\p {L}+|\p {N}{1,3}| ?[^\s\p {L}\p {N}]+[\r\n]|\s[\r\n]+|\s+(?!\S)|\s+"),
behavior=“isolated”, invert=False),
pre_tokenizers.ByteLevel (add_prefix_space=False, trim_offsets=True, use_regex=False)
]
)
print (tokenizer.tokenize (“42069”)) # [42, 069]
训练模型使用了原始的 Llama 架构,此外,该研究还调整了隐藏层的数量,以确保每个模型大致具有相同数量的参数(约 14.5 亿)。
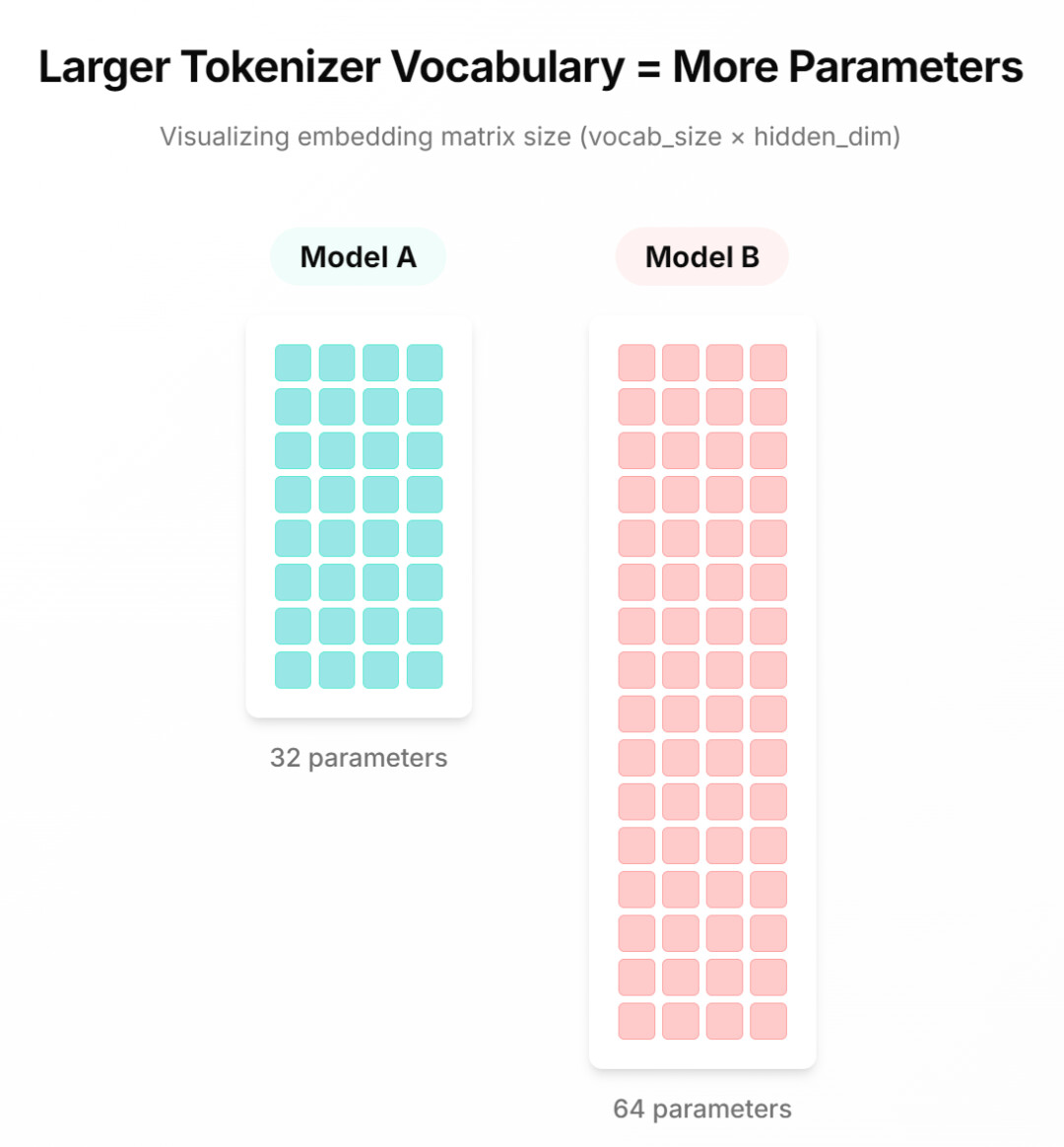
为了保持恒定的计算预算,本文减少了具有更大词汇表模型中的隐藏层数量。
结果
算术问题
如下图所示,单位数 tokenization 优于其他 tokenizer 方法。

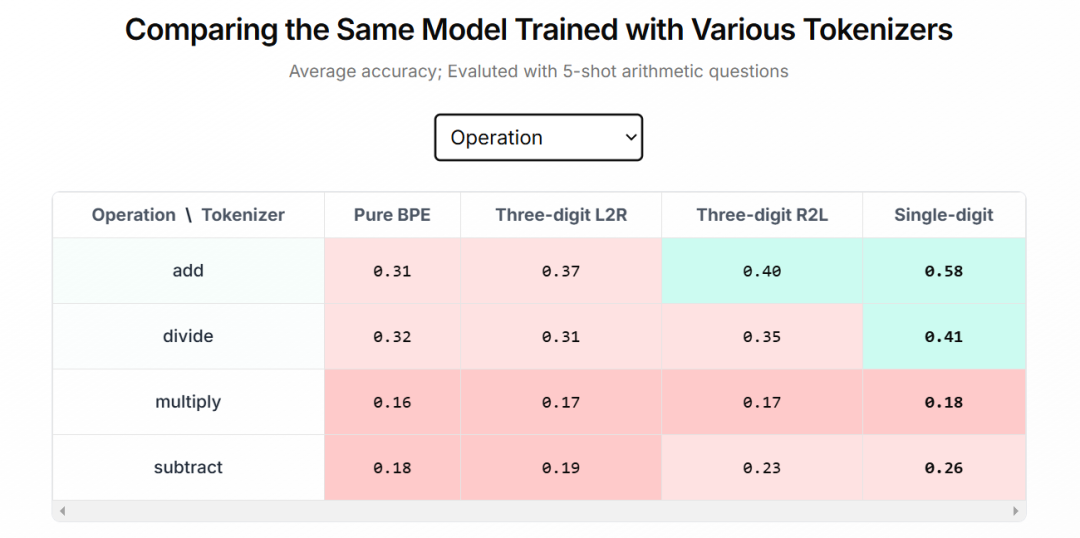

结果显示,虽然在较简单的问题上差异不太明显,但随着问题复杂性的增加,表现最佳的 tokenizer(单位数分词)与其他 tokenizer 之间的差距越来越大。这表明单位数分词对于输入数据长度的变化更为鲁棒,并且能够更好地捕捉复杂的模式,从而在其他分词方法难以应对的场景中提升性能。
此外,本文还发现浮点数和整数之间的性能差距在所有 tokenizer 中都是相似的。这表明在这两个类别中选择 tokenizer 时,并不存在固有的权衡,即对于整数最优的 tokenizer 对于浮点数也是最优的。
如下图所示,三位数 R2L tokenization 比标准三位数 L2R tokenization 具有更好的性能。
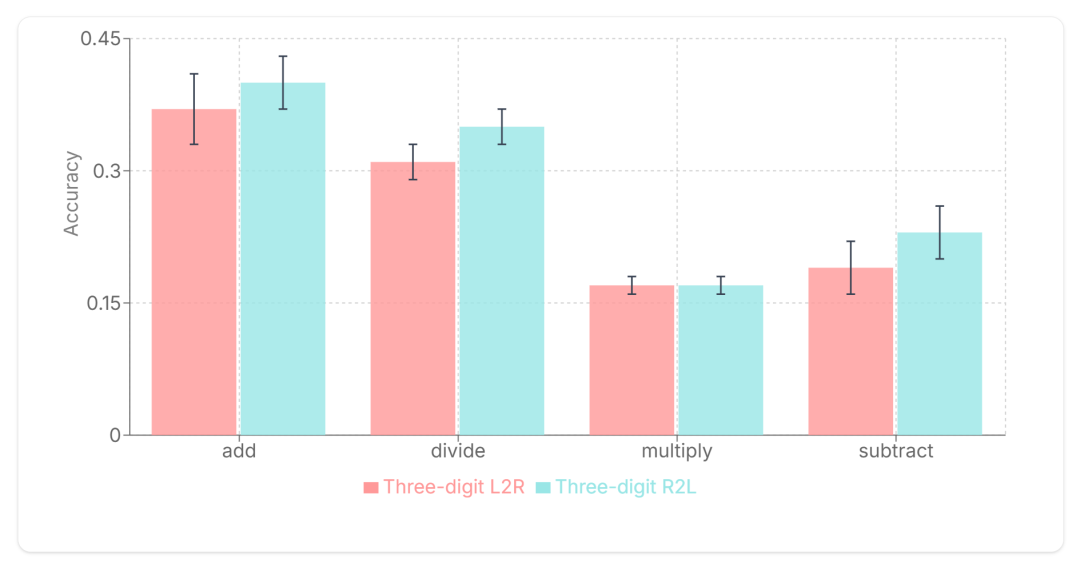
本文发现,与使用默认 L2R token 数据进行训练相比,使用 R2L token 数据进行训练的模型取得了显著的改进(乘法除外)。这表明,与典型的从左到右编码相比,它是算术运算的最佳设置。
当数字被从右向左每 3 位一组进行分块时,Pure-BPE(Byte Pair Encoding)tokenizer 显示出不一致的性能。
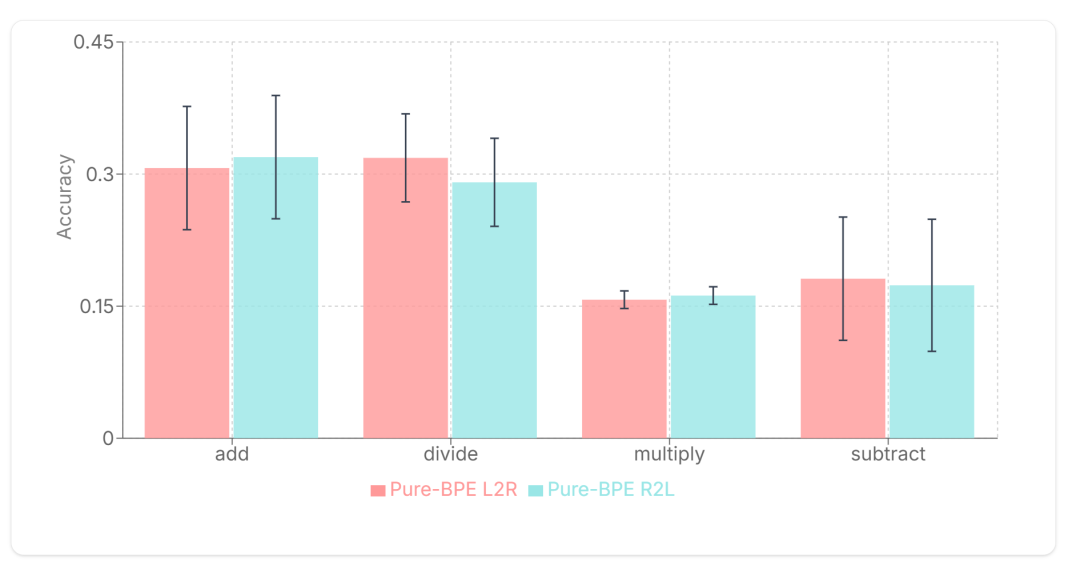
显然,没有任何额外数字预处理的纯基于 BPE 的 tokenizer 不会从使用 R2L token 化中受益。一个可能的解释是,这些 tokenizer 中数字分组的方式缺乏结构。
基于单词的问题

虽然在基于单词的问题上,不同 tokenizer 之间的性能差距不太明显,但本文观察到单位数 tokenizer 和三位数 tokenizer 通常优于基于 BPE 的 tokenizer。这表明,无论是单词问题还是数字问题,这种趋势都是一致的。
Llama 3 R2L 推理
接下来本文进行了另一项测试,即现有的预训练 / 指令模型在接受与最初训练方案不同的 token 化方案时表现如何,而无需重新训练或微调。因此,本文基于 Llama3 8B Instruct 模型,并使用上述相同的代码修改其 tokenizer,以在推理期间执行 R2L tokenization,而无需重新训练新模型。
在三位数 tokenization 方案中进行两个数相加需要注意的是:结果有时会产生比输入数字更多的 token。例如将 999 和 111 相加时,它们单独只需要一个 token,但是当它们相加产生 1110 时,需要两个 token(1 和 110)。基于这个观察,本文想探索在使用 L2R 和 R2L tokenization 对不同的 token 长度执行加法时,会产生多大的差异。
接下来,本文将把导致额外 token 的加法称为进位(carry)加法,而那些没有进位的加法称为无进位(without carry)加法。
本文用 Llama3 8B Instruct 执行了不同数字长度和进位设置的算术任务。结果发现,减法、乘法或除法没有任何显著的性能差异,因此结果只展示了加法。
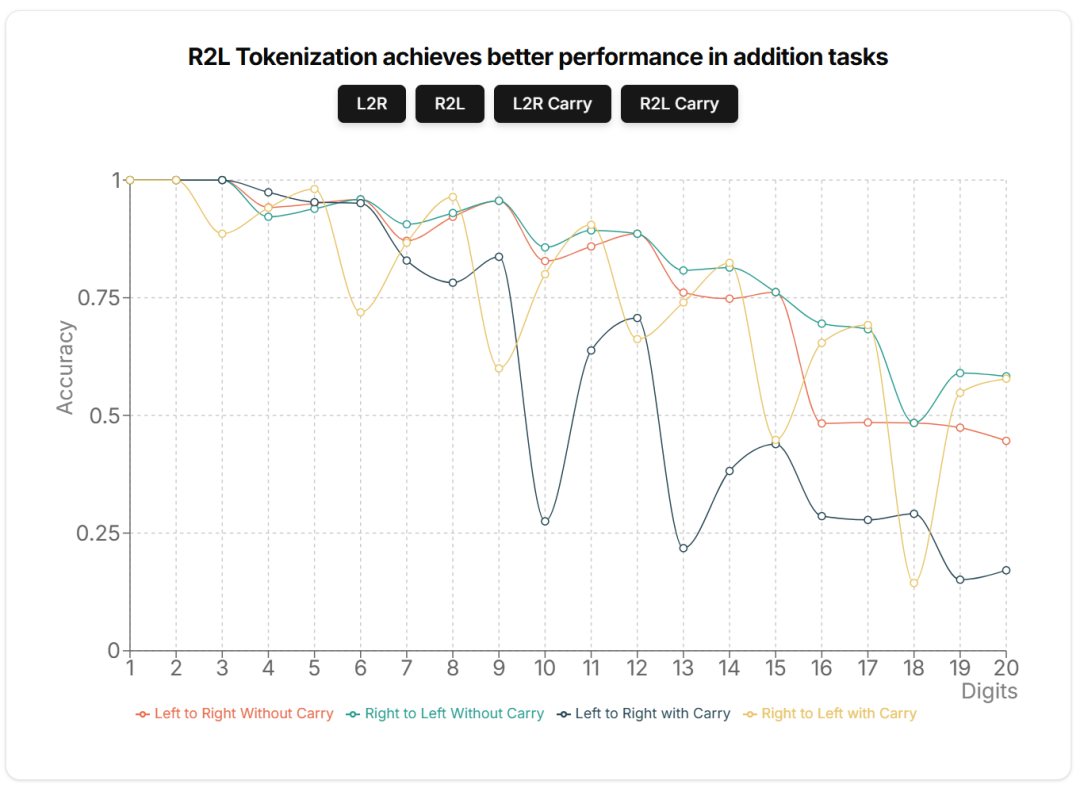
对于非进位加法,数字个数为 3 的倍数会产生完全相同的结果,因为像 528、491 这样的数字无论 token 化方向如何都具有相同的 token。
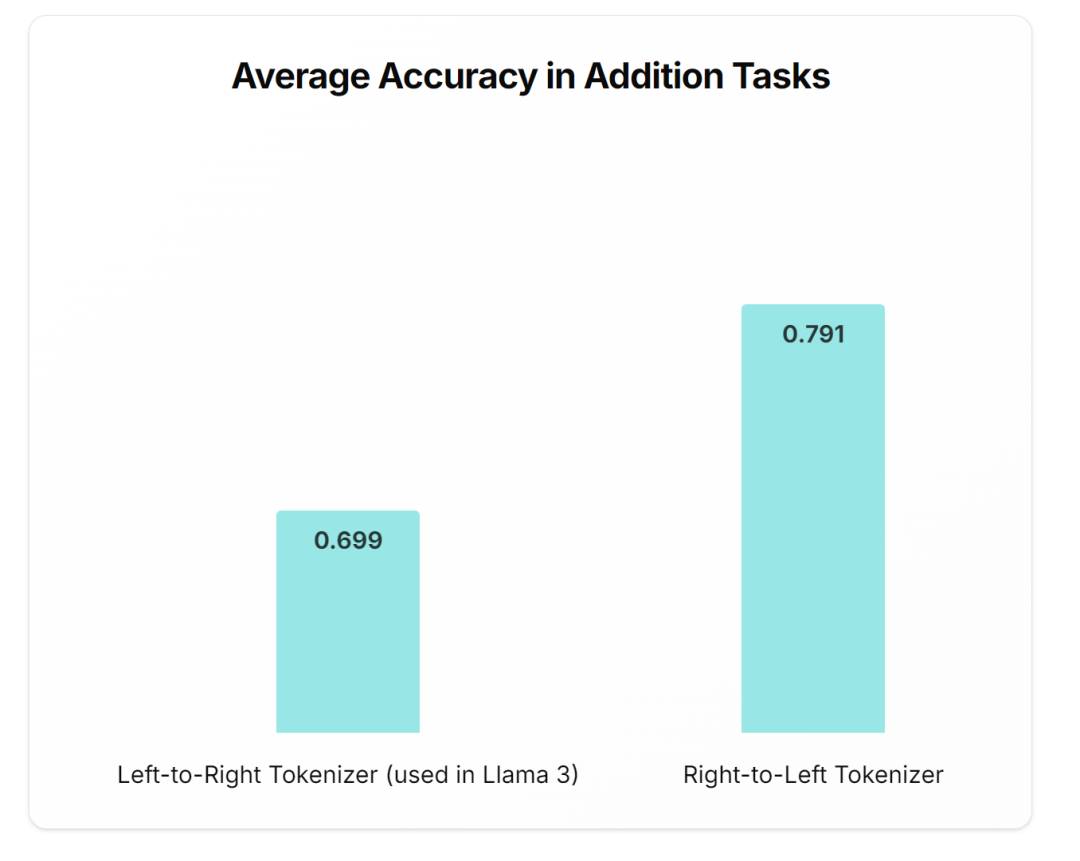
哪种 tokenization 方法适合数学
虽然 BPE 仍然是一种流行的 tokenization 方法,但如果你必须使用具有最多 3 位数的 tokenizer,请确保数据 token 方向为 R2L。
如果你已经有一个经过训练的模型,数据 token 方式为 L2R,那么你可以通过使用 R2L 来获得更好的数学性能。
最重要的是,对于算术运算,单位数 tokenization 的性能明显优于其他方法。
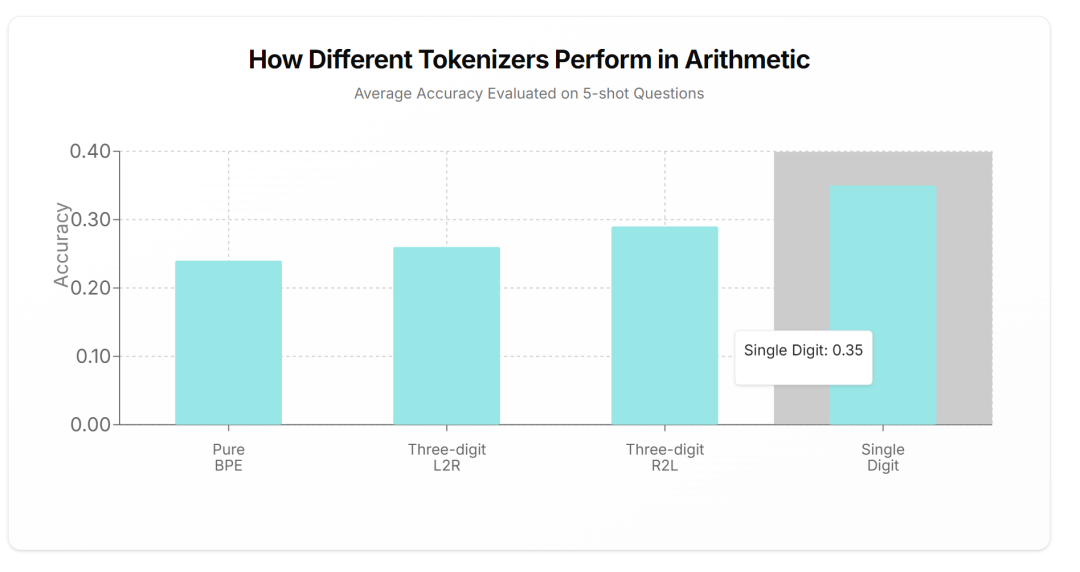
总结而言,tokenization 对语言模型中的算术性能有显著影响。通过仔细选择,我们可以根据问题类型优化 tokenization 策略,从而提高 LLM 在数学任务上的表现。
原文链接:https://huggingface.co/spaces/huggingface/number-tokenization-blog
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com