利用阿里云EMR StarRocks构建游戏数据分析平台,实现玩家画像和行为分析,提升游戏运营效率。
原文标题:手把手进行数据分析,解锁游戏行为画像
原文作者:阿里云开发者
冷月清谈:
该方案利用 StarRocks 的物化视图功能,自动化构建数据仓库中的 DWD 层和 ADS 层数据表,并支持每小时自动刷新。
流程主要分为以下几个步骤:
1. 将存储在 OSS 中的模拟游戏用户数据和行为数据导入到 StarRocks 中,作为 ODS 层数据。
2. 在 StarRocks 中进行即席分析,例如统计用户数量,校验数据导入是否成功等。
3. 使用 StarRocks 的物化视图自动化构建 DWD 层和 ADS 层数据表,例如用户留存率、用户地理分布、设备使用习惯、用户购买趋势等。
4. 将 ADS 层数据回写到 Paimon 数据湖中,并可以直接通过 StarRocks 查询 Paimon 中的数据。
通过以上步骤,可以构建一个性能与成本均衡的游戏玩家画像和行为分析平台。
怜星夜思:
2、StarRocks 的物化视图相比于传统的 ETL 方式有什么优势?
3、Paimon 作为新兴的数据湖存储技术,与其他数据湖方案(例如 Hudi、Iceberg)相比有什么特点?
原文内容

阿里妹导读
前言
一款游戏的成功不仅依赖于其引人入胜的故事情节和精美的画面,更在于能否精准地理解和满足玩家的需求。准确刻画出玩家的画像行为就能更好地提升游戏的可玩性,那么你想知道自己的游戏玩家画像是什么吗?
E-MapReduce StarRocks 版是阿里云提供的 Serverless StarRocks 全托管服务,提供高性能、全场景、极速统一的数据分析体验,内核 100% 兼容 StarRocks,性能比传统 OLAP 引擎提升 3-5 倍,3.X版本提供了物化视图,Paimon读写等多种新能力。
Apache Paimon作为新兴的数据湖存储技术,2024 年 4 月完成孵化成为Apache顶级项目。Apache Paimon 采用开放的数据格式和技术理念,提供高吞吐、低延迟的数据摄入、更新及查询能力,且与诸多业界主流计算对接,是 LakeHouse 架构中不可或缺的一部分。
本文将基于阿里云的EMR Serverless StarRocks,将模拟数据用户表与行为表导入到StarRocks,作为ODS层数据,然后通过使用StarRocks的物化视图,自动化构建数据仓库中DWD层与用于分析的ADS层数据表(按小时自动刷新),最后我们将通过数据湖DLF体验EMR StarRocks读写Paimon的最新能力,通过3个环节构建一个性能与成本均衡的游戏玩家画像和行为分析平台。
4. 将ADS层数据回写Paimon,并直接查询Paimon数据;

实践教程
在方案体验之前请先完成环境准备:
https://emr-next.console.aliyun.com/进行连接实例。(实例可通过免费试用领取)
-
数据准备
a. 创建StarRocks表。进入EMR StarRocks Manager控制台,单击左侧导航栏SQL Editor > +文件。在新建文件对话框中,输入名称后单击确认。
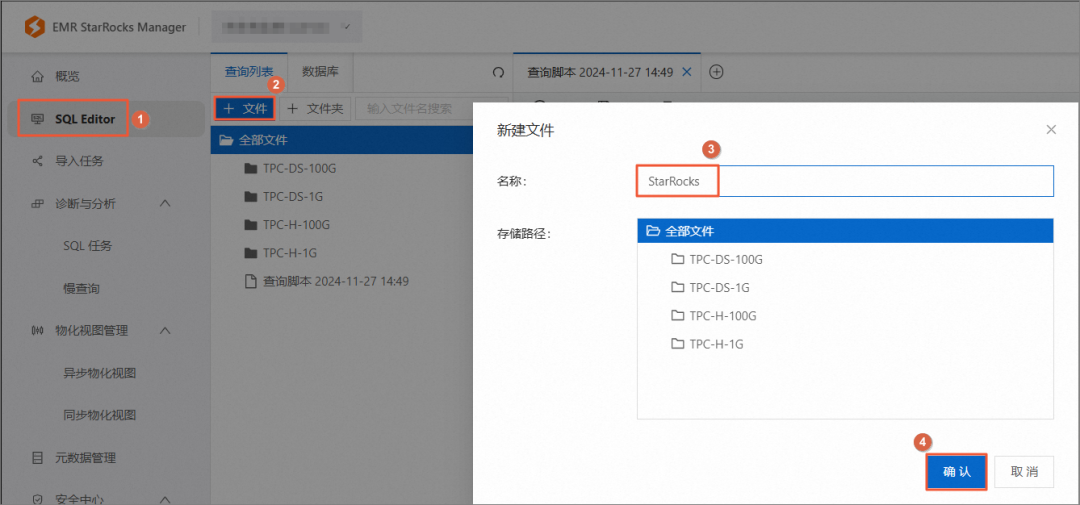
b. 在刚刚创建的文件中,执行如下代码创建StarRocks表,用于接收导入的OSS数据。
--- ********************************************************************** --- --- 初始化:创建StarRocks表,用于接收导入的OSS数据。 --- ********************************************************************** --- -- 创建用户画像(user_profile) 与 用户行为表(user_event) CREATE DATABASE IF NOT EXISTS game_db; use game_db; -- DROP TABLE IF Exists openlake_win.sr_etl_db.user_profile; --用户信息表 CREATE TABLE IF NOT EXISTS ods_user_profile ( user_id INT NOT NULL, registration_date DATE NOT NULL, last_login_date DATE, age_group VARCHAR(20), gender VARCHAR(10), location VARCHAR(50), game_hours INT, favorite_game_mode VARCHAR(20), play_frequency VARCHAR(20), device_type VARCHAR(20), os_version VARCHAR(20), current_level INT, total_deaths INT, active_time VARCHAR(20), language_preference VARCHAR(10) ) PRIMARY KEY (user_id) DISTRIBUTED BY HASH(user_id) PROPERTIES ( "replication_num" = "1" ) ;– 用户事件表
– DROP TABLE IF Exists openlake_win.sr_etl_db.user_event;
CREATE TABLE IF NOT EXISTS ods_user_event (
user_idINT,
event_typeSTRING,
timestampdatetime,
locationSTRING,
levelINT,
event_detailsSTRING
)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
“replication_num” = “1”
)
;
– 清空之前数据
truncate table game_db.ods_user_profile;
truncate table game_db.ods_user_event;
重要:本SQL会以杭州为例,需将${REGION}替换为cn-hangzhou。如果是其他Reigon请将代码中${REGION}部分替换为相应地域。
--- ********************************************************************** --- --- 使用Broker Load 将OSS数据导入数据到StarRocks表中 --- ********************************************************************** --- use game_db; --导入新的数据 LOAD LABEL game_db.user_profile_20240902_22 ( DATA INFILE("oss://emr-starrocks-benchmark-resource-${REGION}/sr_game_demo/user_profile/*") INTO TABLE ods_user_profile FORMAT AS "parquet" ) WITH BROKER ( "fs.oss.endpoint" = "oss-${REGION}-internal.aliyuncs.com" ) PROPERTIES ( "timeout" = "3600" );LOAD LABEL game_db.user_event_20240902_22
(
DATA INFILE(“oss://emr-starrocks-benchmark-resource-${REGION}/sr_game_demo/user_event/*”)
INTO TABLE ods_user_event
FORMAT AS “parquet”
)
WITH BROKER
(
“fs.oss.endpoint” = “oss-${REGION}-internal.aliyuncs.com”
)
PROPERTIES
(
“timeout” = “3600”
);/**
– 导入完成后,如果要查看导入进度,可以到StarRocks控制台的Manager中连接数据库后查看.
– 控制台地址: https://emr-next.console.aliyun.com/olap-dm
– 问题处理
– 如出现 Unexpected exception: Label [user_profile_01] has already been used. 则按照错误提示,修改load任务的名称为新的名称即可。
**/
d. 单击左侧导航栏导入任务 > Broker Load,查看任务状态和进度。
e. 执行如下命令,校验写入数据是否成功。执行此命令前需等待数据导入任务完成,数据导入一般需要1-3分钟左右。
use game_db;
select * from (
select
count(1),'ods_user_event' as tb
from
ods_user_event
union all
select
count(1),'ods_user_profile' as tb
from
ods_user_profile
) t
查询结果如图所示。

-
EMR-StarRocks物化视图,自动构建DWD-ADS
-
执行如下命令,创建DWD层EMR-StarRocks物化视图,每隔1小时刷新一次。
--- ********************************************************************** --- --- 使用StarRocks物化视图,自动化构建数据仓库DWD层 --- 说明:此处为了简化逻辑,仅直接将ODS层数据直接插入DWD,实际情况应该有更多业务逻辑需要处理。 --- ********************************************************************** --- use game_db; DROP MATERIALIZED VIEW IF EXISTS dwd_mv_user_profile; CREATE MATERIALIZED VIEW IF NOT EXISTS dwd_mv_user_profile DISTRIBUTED BY RANDOM REFRESH ASYNC EVERY(INTERVAL 1 HOUR) -- 每隔小时刷新一次 AS SELECT * FROM ods_user_profile;
DROP MATERIALIZED VIEW IF EXISTS dwd_mv_user_event;
CREATE MATERIALIZED VIEW IF NOT EXISTS dwd_mv_user_event
DISTRIBUTED BY RANDOM
REFRESH ASYNC EVERY(INTERVAL 1 HOUR) – 每隔小时刷新一次
AS
SELECT * FROM ods_user_event;
-- 校验上面步骤的数据加工结果 -- use game_db; select * from ( select count(1),'dwd_mv_user_profile' as tb from dwd_mv_user_profile union all select count(1),'dwd_mv_user_event' as tb from dwd_mv_user_event ) t
校验结果如下。

--- ********************************************************************** --- --- 使用StarRocks物化视图,自动化构建数据仓库ADS层 --- ********************************************************************** --- use game_db; --1. 创建ADS_MV_USER_RETENTION (用户留存率) CREATE MATERIALIZED VIEW IF NOT EXISTS ADS_MV_USER_RETENTION DISTRIBUTED BY RANDOM REFRESH ASYNC EVERY(INTERVAL 1 HOUR) AS SELECT DATE_TRUNC('day', registration_date) AS registration_day, DATE_TRUNC('day', last_login_date) AS last_login_day, COUNT(DISTINCT user_id) AS users_retained FROM dwd_mv_user_profile GROUP BY DATE_TRUNC('day', registration_date), DATE_TRUNC('day', last_login_date);– 2. ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION (用户地理分布)
CREATE MATERIALIZED VIEW IF NOT EXISTS ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION
DISTRIBUTED BY RANDOM
REFRESH ASYNC EVERY(INTERVAL 1 HOUR)
AS
SELECT
location AS geographic_location,
COUNT(DISTINCT user_id) AS total_users
FROM dwd_mv_user_profile
GROUP BY
location;– 3. ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION (设备使用习惯)
CREATE MATERIALIZED VIEW IF NOT EXISTS ADS_MV_USER_DEVICE_PREFERENCE
DISTRIBUTED BY RANDOM
REFRESH ASYNC EVERY(INTERVAL 1 HOUR)
AS
SELECT
device_type,
COUNT(DISTINCT user_id) AS total_users
FROM dwd_mv_user_profile
GROUP BY
device_type;
– 4. ADS_MV_USER_PURCHASE_TRENDS (用户购买趋势)
– 该视图用于分析玩家每天的购买趋势变化
CREATE MATERIALIZED VIEW IF NOT EXISTS ADS_MV_USER_PURCHASE_TRENDS
DISTRIBUTED BY RANDOM
REFRESH ASYNC EVERY(INTERVAL 1 HOUR)
AS
SELECT
DATE(timestamp) AS purchase_date,
COUNT(user_id) AS daily_purchase_events
FROM dwd_mv_user_event
WHERE event_type = ‘购买’
GROUP BY
purchase_date
ORDER BY
purchase_date;
执行如下命令,校验上面步骤的数据加工结果。
-- 校验上面步骤的数据加工结果 -- use game_db; select * from ( select count(1),'ADS_MV_USER_RETENTION' as tb from ADS_MV_USER_RETENTION union all select count(1),'ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION' as tb from ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION union all select count(1),'ADS_MV_USER_DEVICE_PREFERENCE' as tb from ADS_MV_USER_DEVICE_PREFERENCE union all select count(1),'ADS_MV_USER_PURCHASE_TRENDS' as tb from ADS_MV_USER_PURCHASE_TRENDS ) t
校验结果如下。

3. 创建RAM用户与授权
-
准备阿里云RAM账号。
-
为RAM账号添加EMR StarRocks用户权限。
-
在添加用户对话框中,完成用户来源、用户名、密码、用户类型等参数填写后,单击确定。
4. 写入查询Paimon数据
-
开通DLF2.0。进入数据湖构建DLF2.0控制台,根据页面引导开通DLF2.0。
-
单击左侧导航栏数据目录 > 新建Catalogs。(本场景示例地域为杭州)
-
在数据湖构建页面输入Catalog名称后,单击创建Catalog。
-
单击刚刚创建的Catalog名称,选择权限 > 授权,并完成基本信息和权限参数以添加RAM账号授权。
-
新建EMR-StarRocks RAM账号连接。
-
写入数据湖中(Paimon格式)。
${DLF_CATALOG_ID}需要替换为刚刚创建的Catalogs ID。
--- ********************************************************************** --- --- 写入数据湖中(Paimon格式)- 初始化Catalog信息 --- ********************************************************************** --- -- 1. 在StarRocks中创建Catalog -- MyFirstCatalog可以根据您的实际情况调整。 -- DROP CATALOG `myfirstcatalog`; CREATE EXTERNAL CATALOG `myfirstcatalog` PROPERTIES ( "type" = "paimon", "paimon.catalog.type" = "dlf-paimon", "dlf.catalog.instance.id" = "${DLF_CATALOG_ID}" );
--- ********************************************************************** --- --- 写入数据湖中(Paimon格式) --- ********************************************************************** --- create database if not exists myfirstcatalog.game_db; CREATE TABLE IF NOT EXISTS myfirstcatalog.game_db.ADS_USER_PURCHASE_TRENDS( purchase_date DATE COMMENT '购买日期', daily_purchase_events INT COMMENT '每日购买事件数量' );
– ADS:ETL加工数据
INSERT
INTO myfirstcatalog.game_db.ADS_USER_PURCHASE_TRENDS
SELECT * from default_catalog.game_db.ADS_MV_USER_PURCHASE_TRENDS;
-- 校验写入数据湖中的数据情况 select count(1),'myfirstcatalog.game_db.ADS_USER_PURCHASE_TRENDS' as tb from myfirstcatalog.game_db.ADS_USER_PURCHASE_TRENDS

重要:在完成实验后,如果无需继续使用资源,请根据以下步骤,先删除相关资源后,再结束实操,否则资源会持续运行产生费用。
Tip:阿里云EMR-StarRocks联合镜舟科技,基于EMR-StarRocks实现游戏实时湖仓分析,免费试用物化视图、Paimon写入查询等新能力,前45位赢取StarRocks定制T恤、Lamy钢笔,小米充电宝,阿里云拍拍灯等活动礼品,前500位均可获得创意马克杯。
点击下方阅读原文立即参与~