李飞飞团队研究发现,多模态大语言模型初步具备空间思维能力,但与人类相比仍有较大差距。
原文标题:李飞飞、谢赛宁等探索MLLM「视觉空间智能」,网友:2025有盼头了
原文作者:机器之心
冷月清谈:
斯坦福大学李飞飞教授团队最新研究探索了多模态大语言模型 (MLLM) 的视觉空间智能。他们创建了一个名为 VSI-Bench 的基准测试,包含近 290 个室内场景视频和 5000 多个问答对,用于评估 MLLM 对空间信息的理解和推理能力。
研究发现,虽然 MLLM 在某些任务上展现出初步的空间推理能力,但与人类相比仍有较大差距。人类评估者的平均准确率达到 79%,比最佳模型高出 33%。谷歌的 Gemini Pro 表现最佳,尤其在绝对距离和房间大小估计等任务上接近人类水平。然而,大多数开源模型的性能低于随机猜测的基线。
研究指出,空间推理是 MLLM 在 VSI-Bench 上的主要瓶颈。模型在理解距离、大小和方向等方面存在困难。此外,常用的语言提示技术,如思维链 (CoT) 和多数投票,反而会降低 MLLM 在空间推理任务上的表现。
该研究表明,MLLM 在空间思维方面仍有很大提升空间,未来需要进一步研究如何提高模型对空间信息的理解和推理能力。
研究发现,虽然 MLLM 在某些任务上展现出初步的空间推理能力,但与人类相比仍有较大差距。人类评估者的平均准确率达到 79%,比最佳模型高出 33%。谷歌的 Gemini Pro 表现最佳,尤其在绝对距离和房间大小估计等任务上接近人类水平。然而,大多数开源模型的性能低于随机猜测的基线。
研究指出,空间推理是 MLLM 在 VSI-Bench 上的主要瓶颈。模型在理解距离、大小和方向等方面存在困难。此外,常用的语言提示技术,如思维链 (CoT) 和多数投票,反而会降低 MLLM 在空间推理任务上的表现。
该研究表明,MLLM 在空间思维方面仍有很大提升空间,未来需要进一步研究如何提高模型对空间信息的理解和推理能力。
怜星夜思:
1、除了文中提到的任务,大家觉得MLLM在哪些涉及空间推理的场景下还有应用潜力?
2、文章提到语言提示技术对空间推理有害,为什么会出现这种情况?大家有什么看法?
3、MLLM的空间思维能力与人类相比还有哪些关键差距?如何弥补这些差距?
2、文章提到语言提示技术对空间推理有害,为什么会出现这种情况?大家有什么看法?
3、MLLM的空间思维能力与人类相比还有哪些关键差距?如何弥补这些差距?
原文内容
机器之心报道
机器之心编辑部
希望 2025 年 AI 领域能带来推理之外的突破。
在购买家具时,我们会尝试回忆起我们的客厅,以想象一个心仪的橱柜是否合适。虽然估计距离是困难的,但即使只是看过一次,人类也能在脑海里重建空间,回忆起房间里的物体、它们的位置和大小。
我们生活在一个感官丰富的 3D 世界中,视觉信号围绕着我们,让我们能够感知、理解和与之互动。
这是因为人类拥有视觉空间智能(visual-spatial intelligence),能够通过连续的视觉观察记住空间。然而,在百万级视频数据集上训练的多模态大语言模型 (MLLM) 是否也能通过视频在空间中思考,即空间思维(Thinking in Space)?
为了在视觉空间领域推进这种智能,来自纽约大学、耶鲁大学、斯坦福大学的研究者引入了 VSI-Bench,这是一个基于视频的基准测试,涵盖了近 290 个真实室内场景视频,包含超过 5000 个问答对。
其中,视频数据是通过捕捉连续的、时间性的输入来完成的,不仅与我们观察世界的方式相似,而且比静态图像更能丰富空间理解和推理。在 VSI-Bench 上评估开源和闭源模型显示,尽管模型与人类之间存在较大的性能差距,尽管 MLLM 面临视频理解、文本理解和空间推理的挑战,但其仍展现出了新兴的视觉空间智能。
为了对模型行为展开研究,本文受到双重编码理论的启发(该理论认为语言处理和视觉处理既有区别又相互补充),他们提出了用于自我解释(语言)和认知图(视觉)的选择模型(selected models)。

-
论文地址:https://arxiv.org/pdf/2412.14171v1
-
论文主页:https://vision-x-nyu.github.io/thinking-in-space.github.io/
-
论文标题:Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
这篇论文作者有我们熟悉的斯坦福大学教授李飞飞,她提倡的「空间智能」最近正在引领 AI 发展方向,还有纽约大学计算机科学助理教授谢赛宁等。
谢赛宁表示,「视频理解是下一个研究前沿,但并非所有视频都是一样的。模型现在可以通过 youtube 片段和故事片进行推理,但是我们未来的 AI 助手在日常空间中导航和经验如何呢?空间思维正是为这一问题诞生的,我们的最新研究 VSI-Bench,可以探索多模态 LLM 如何看待、记忆和回忆空间。」

「在视觉处理方面,我们通常处理空间问题,但很少进行推理;而多模态大语言模型(LLM)虽然能够思考,但通常忽略了逻辑空间。然而,作为人类 —— 无论是做心理旋转测试还是为新家定制家具 —— 我们依赖于空间和视觉思维 。而这些思维并不总能很好地转化为语言。」
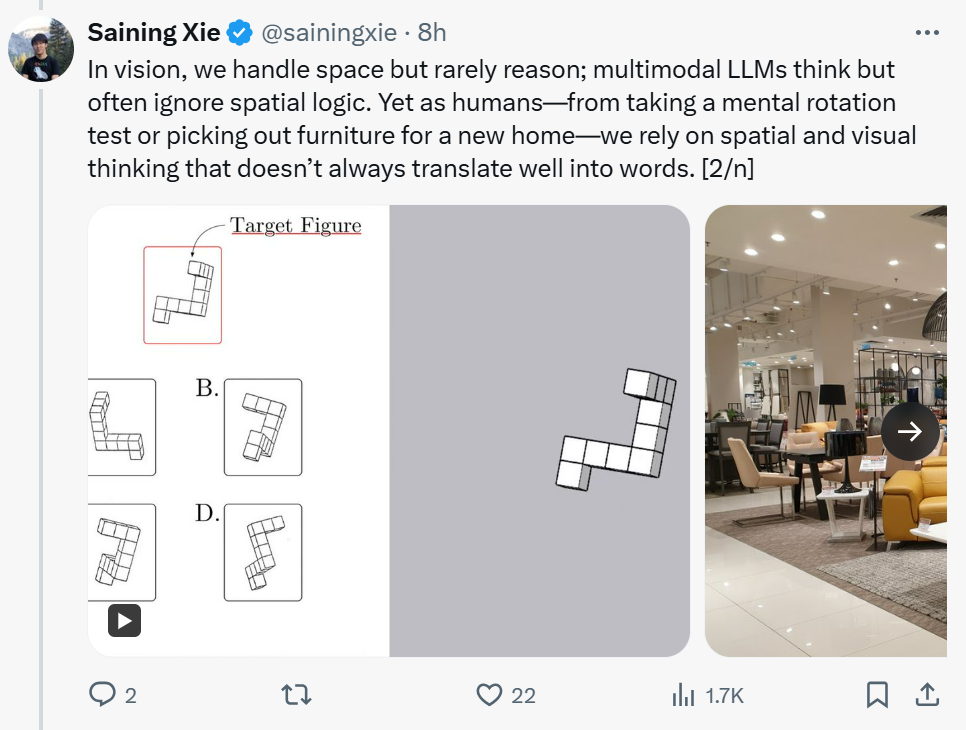
「我们通过研究涵盖各种视觉空间智能任务(关系和度量)的新基准来探索这一点。」
李飞飞也对这项研究进行了宣传,她表示这项名为「Thinking in Space」的研究,是对 LLM(大部分都失败了)在空间推理方面表现的评估,而空间推理对人类智能至关重要。2025 年还有更多值得期待的事情,以突破空间智能的界限!

在李飞飞的这条推文下,网友已经开始期待即将到来的 2025 年。
在论文主页给出的 Demo 中,作者提供了谷歌 Gemini 模型在视觉空间智能上的一些表现。(以下视频均以 2 倍速播放。)
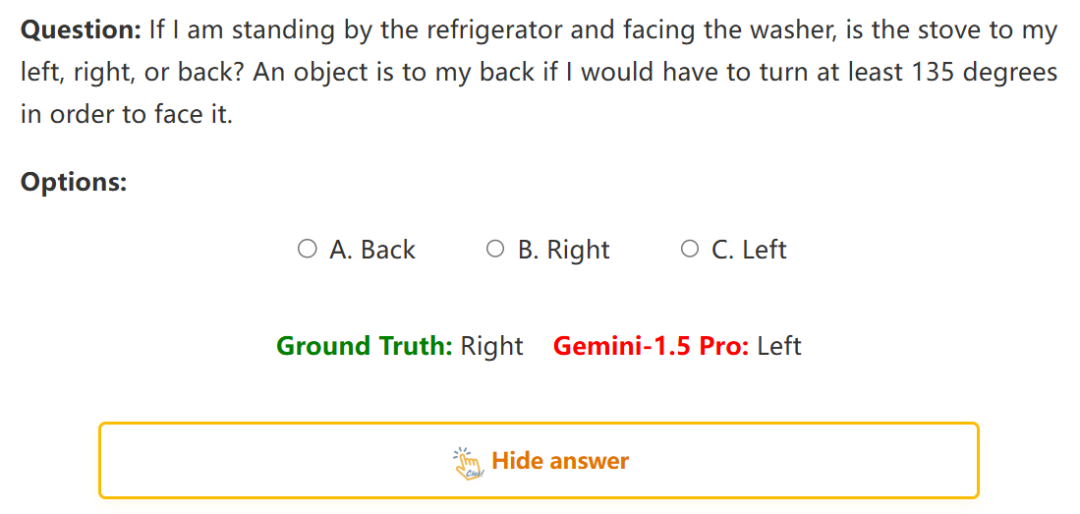
1:估计相对距离
问:如果我站在冰箱旁边,面对着洗衣机,炉子是在我的左边、右边还是后面……
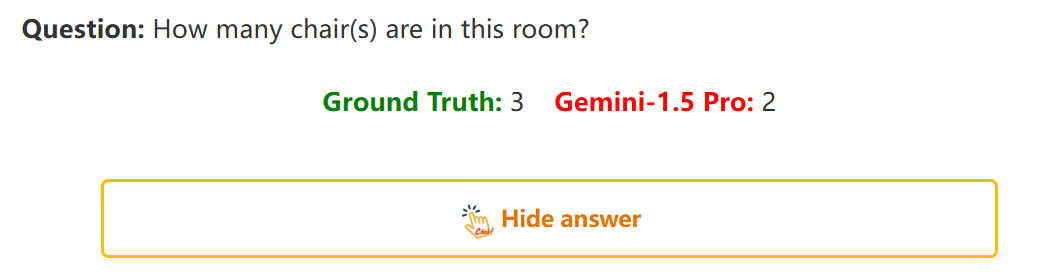
2:让大模型数物体
问:房间里有几把椅子?Gemini-1.5 Pro 给出了 2。
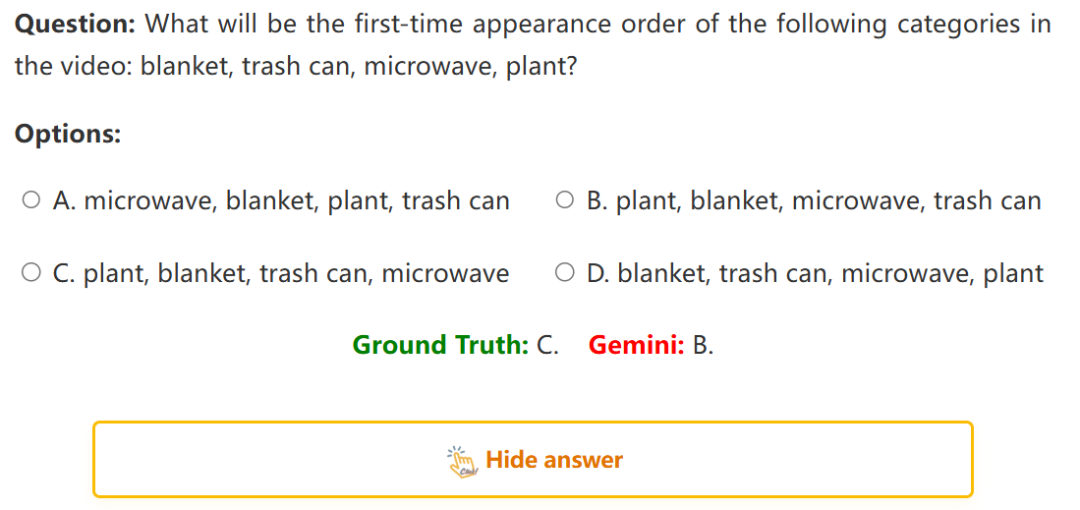
3:根据视频猜测物体出现的顺序
问:以下类别在视频中第一次出现的顺序是:毯子、垃圾桶、微波炉、植物?Gemini 给出 B 选项,正确答案是 C。
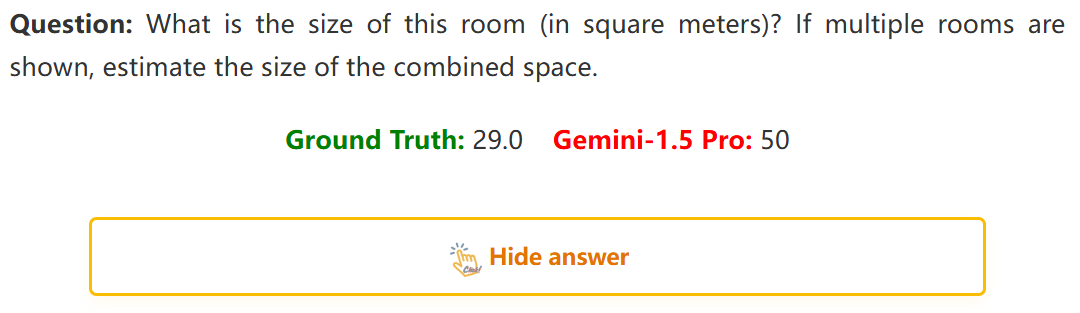
4:估计房间大小
问:这个房间有多大(平方米)?如果展示了多个房间,估计一下组合空间的大小。
VSI-Bench 介绍
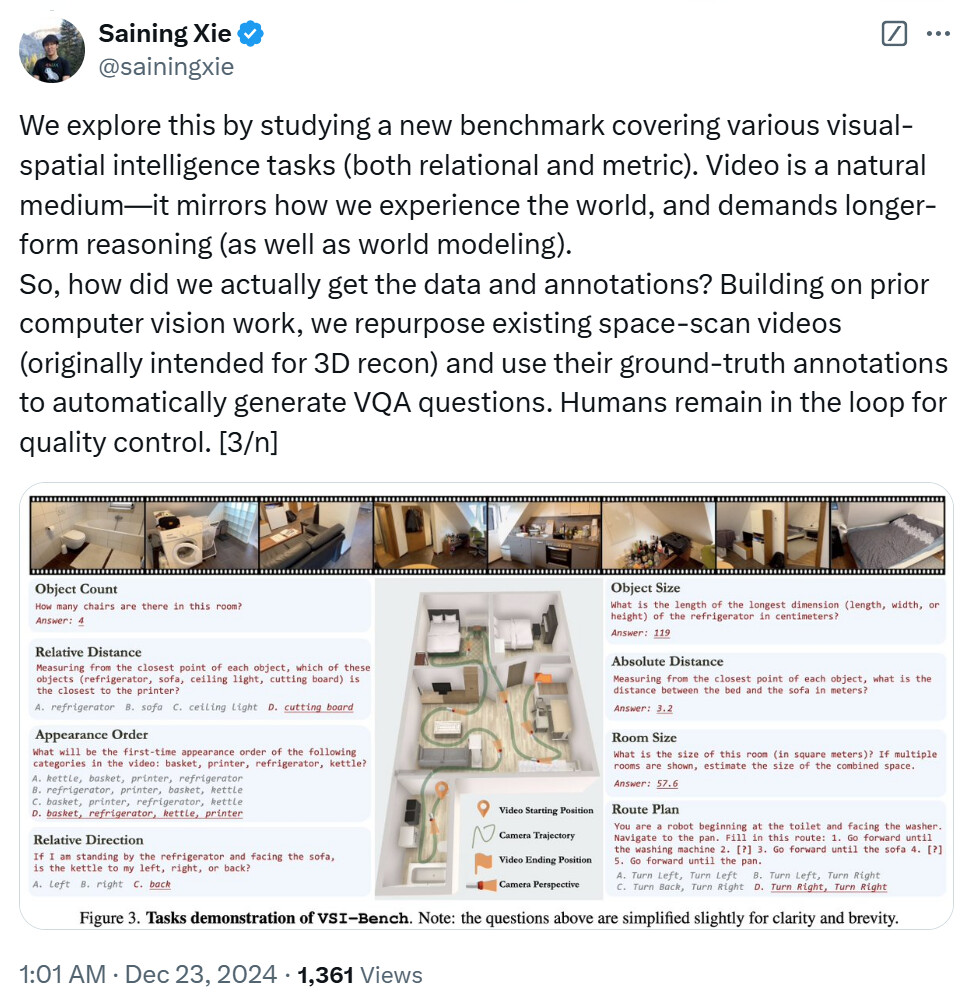
VSI-Bench 是一个用于定量评估从第一视角视频出发的 MLLM 视觉空间智能的工具。VSI-Bench 包含了超过 5000 个问答对,这些问答对来源于 288 个真实视频。这些视频包括居住空间、专业场所(例如,办公室、实验室)和工业场所(例如,工厂)—— 以及多个地理区域。VSI-Bench 的质量很高,经过迭代审查以最小化问题的歧义,并移除了从源数据集中传播的错误注释。
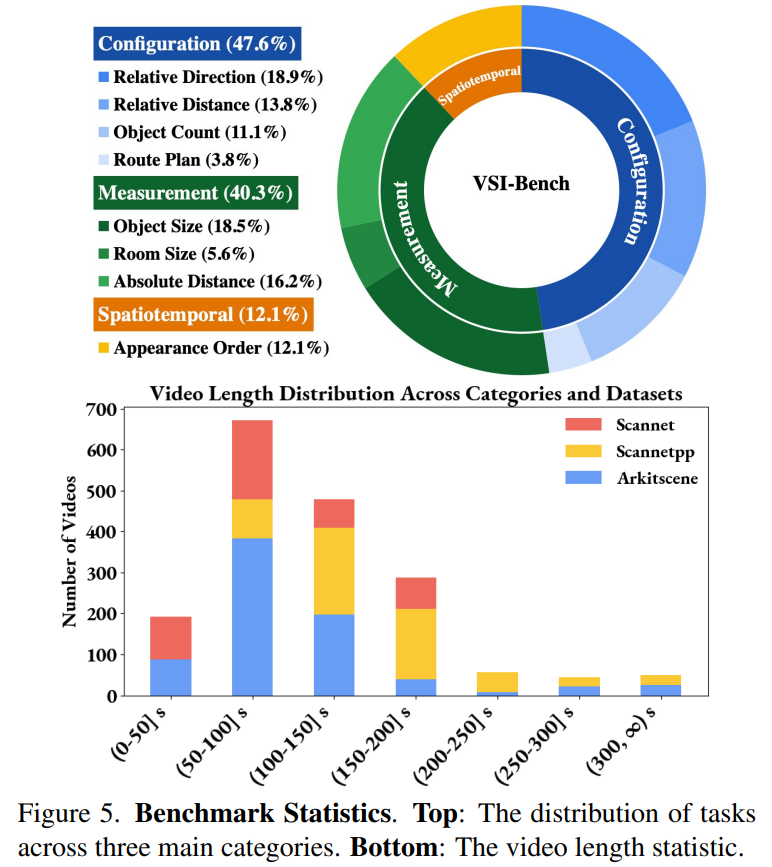
VSI-Bench 包括八项任务,如图 3 所示,包括:物体计数、相对距离、出现的顺序、相对方向、物体大小、绝对距离、房间面积、路径规划。

VSI-Bench 的任务演示。注意:为清晰简洁起见,上述问题略作简化。
数据集统计见图 5。
此外,本文还开发了一个复杂的基准构建流程,以有效地大规模生成高质量问答(QA)对,如图 4 所示。
评估
评估设置:本文对 15 个支持视频的 MLLM 进行了基准测试。专有模型包括 Gemini-1.5 和 GPT-4o。开源模型包括 InternVL2、ViLA、LongViLA、LongVA、LLaVA-OneVision 和 LLaVA-NeXT-Video 。
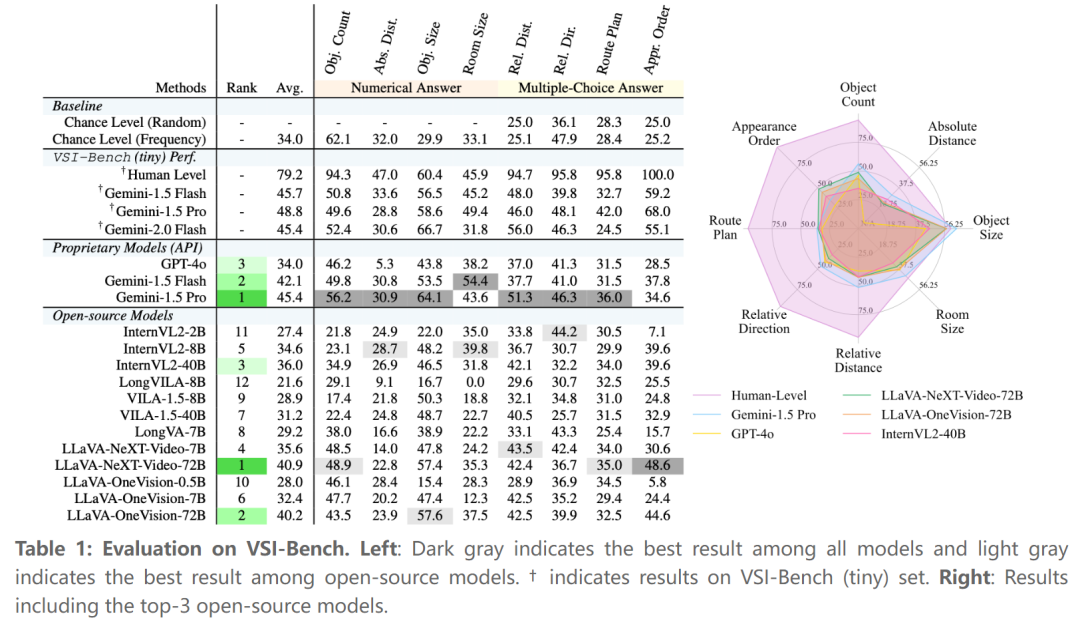
主要结果:通过 5000 多个问答对,作者发现 MLLM 表现出了有竞争性的视觉空间智能(尽管仍然低于人类)。Gemini Pro 表现最佳,但与人类的表现仍有差距。
具体而言,人类评估者的平均准确率达到 79%,比最佳模型高出 33%,在配置和时空任务上的表现接近完美(94%-100%)。
然而,在需要精确估计的测量任务上,差距缩小了,MLLM 在定量任务中表现出相对优势。
在专有模型中,Gemini-1.5 Pro 脱颖而出,尽管只在 2D 数字数据上进行训练,但它大大超过了机会基线,并在绝对距离和房间大小估计等任务中接近人类表现。
表现最佳的开源模型,如 LLaVA-NeXT-Video-72B 和 LLaVA-OneVision-72B,取得了有竞争力的结果,仅落后 Gemini-1.5 Pro 4%-5%。然而,大多数开源模型(7/12)都低于机会基线,暴露出视觉空间智能的明显缺陷。
为了更好地理解模型成功或失败的时间和原因,并阐明它们所拥有的视觉空间智能的各个方面,本文研究了 MLLM 如何在空间语言中思考。
当被要求解释自己时,LLM 表示空间推理(而不是物体识别或语言能力)是主要瓶颈。
在成功示例中,该模型展示了高级视频理解能力,具有准确的时间戳描述和正确的逐步推理过程。全局坐标系的使用表明 MLLM 可以通过整合空间背景和推理来构建隐式世界模型。

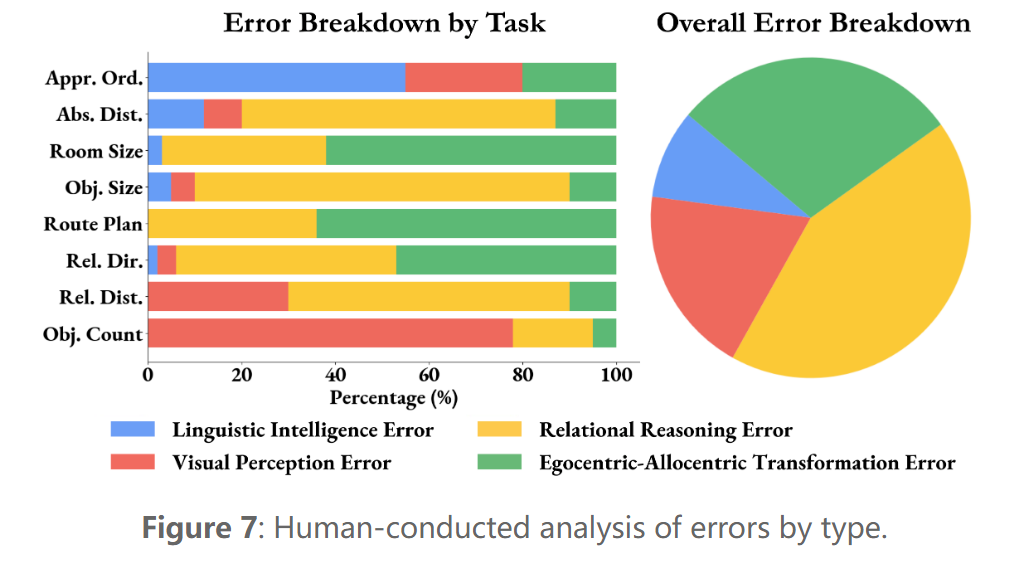
错误分析:对 VSI-Bench(tiny)上表现最佳的 MLLM 的错误进行分析,发现主要有四种错误类型:视觉感知、语言智能、关系推理和第一视角 - 他人视角转换。图 6 显示,71% 的错误源于空间推理,特别是在理解距离、大小和方向方面。这表明空间推理仍然是提高 VSI-Bench 上 MLLM 性能的关键瓶颈。
此外,本文还有一些其他发现。
-
发现 1:空间推理是影响 MLLM 在 VSI-Bench 上的主要瓶颈。
-
发现 2:语言提示技术虽然在语言推理和一般视觉任务中有效,但对空间推理有害。
-
发现 3:在记忆空间时,MLLM 会根据给定的视频在模型中形成一系列局部世界模型,而不是统一的全局模型。
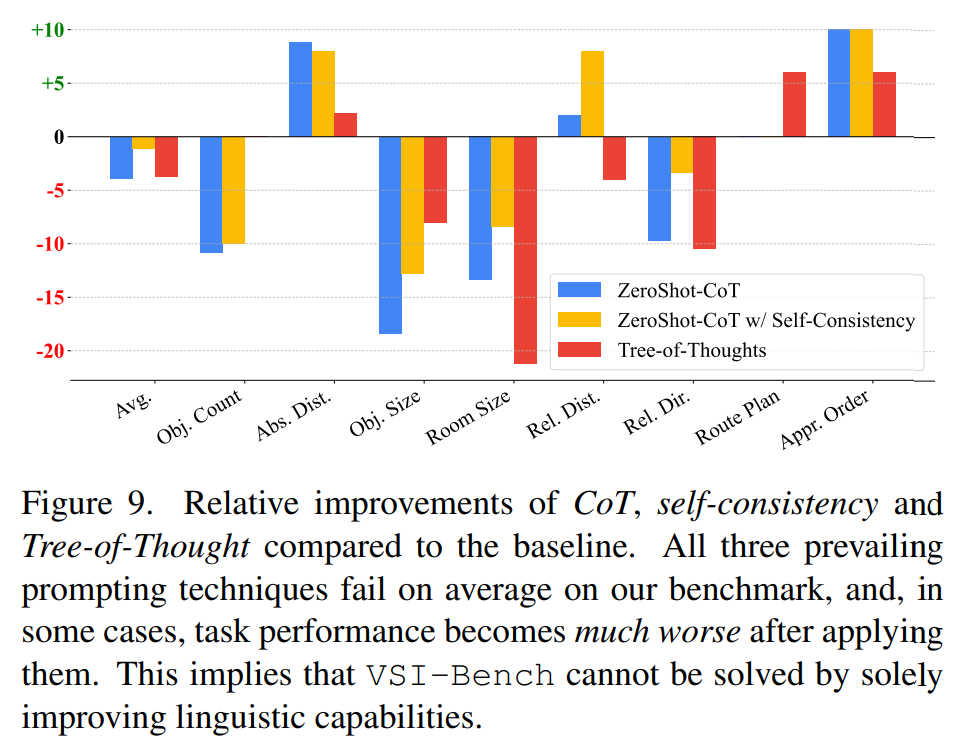
语言提示技术在这种情况下是无效的 —— 像 CoT 或多数投票这样的方法实际上对本文任务是非常有害的。
了解更多内容,请参考原论文。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com