ReconDreamer实现单视角视频构建4D世界,显著提升自动驾驶场景重建效果,支持大范围自由视角渲染。
原文标题:世界模型进入4D时代!单视角视频构建的自由视角4D世界来了
原文作者:机器之心
冷月清谈:
李飞飞团队的单图生成三维世界研究推动了AI在场景重建领域的进步。在此基础上,极佳科技、北京大学、理想汽车及中科院自动化所联合推出的ReconDreamer,实现了从单视角视频构建自由视角4D世界的突破。
ReconDreamer通过结合传统三维重建方法与视频生成世界模型,并引入渐进式修复策略,解决了现有技术在大范围视角变化和复杂驾驶操作下重建效果不佳的问题。该方法首先使用传统方法进行场景重建,然后通过采样新轨迹进行渲染。为消除渲染视频中的伪影,ReconDreamer利用视频生成世界模型DriveRestorer进行视频修复,并将修复后的视频与原始视频一同用于优化重建模型。此外,渐进式数据更新策略的应用,也使得ReconDreamer能够逐步处理更大范围的渲染,最终实现高质量的场景重建。
实验结果表明,ReconDreamer在大范围相机运动下的渲染质量显著优于现有方法,尤其是在变道、加速、减速等复杂驾驶操作场景下。与DriveDreamer4D和Street Gaussians等方法相比,ReconDreamer生成的视频在车辆、车道线等元素的时空一致性方面表现更佳,能够有效提升闭环仿真的精度和可靠性。此外,用户研究也表明ReconDreamer的渲染效果更受用户青睐。
ReconDreamer通过结合传统三维重建方法与视频生成世界模型,并引入渐进式修复策略,解决了现有技术在大范围视角变化和复杂驾驶操作下重建效果不佳的问题。该方法首先使用传统方法进行场景重建,然后通过采样新轨迹进行渲染。为消除渲染视频中的伪影,ReconDreamer利用视频生成世界模型DriveRestorer进行视频修复,并将修复后的视频与原始视频一同用于优化重建模型。此外,渐进式数据更新策略的应用,也使得ReconDreamer能够逐步处理更大范围的渲染,最终实现高质量的场景重建。
实验结果表明,ReconDreamer在大范围相机运动下的渲染质量显著优于现有方法,尤其是在变道、加速、减速等复杂驾驶操作场景下。与DriveDreamer4D和Street Gaussians等方法相比,ReconDreamer生成的视频在车辆、车道线等元素的时空一致性方面表现更佳,能够有效提升闭环仿真的精度和可靠性。此外,用户研究也表明ReconDreamer的渲染效果更受用户青睐。
怜星夜思:
1、ReconDreamer 的核心创新点是什么?它与之前的 DriveDreamer 系列工作有什么联系和区别?
2、ReconDreamer 提出的渐进式修复策略具体是如何工作的?为什么这种策略能够提升大范围相机运动下的渲染质量?
3、ReconDreamer 在实际应用中有哪些潜在的应用场景?除了自动驾驶,它还可以应用于哪些领域?
2、ReconDreamer 提出的渐进式修复策略具体是如何工作的?为什么这种策略能够提升大范围相机运动下的渲染质量?
3、ReconDreamer 在实际应用中有哪些潜在的应用场景?除了自动驾驶,它还可以应用于哪些领域?
原文内容
![]()
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
人工智能技术正以前所未有的速度改变着我们对世界的认知与构建方式。近期,李飞飞教授团队通过单张图片生成三维物理世界的研究,再次向世界展示了空间智能技术的巨大潜力。
单图生成三维世界,不仅让人们能以交互方式探索静态图像,更标志着 AI 在重建与理解物理场景方面迈入全新阶段。
近日,极佳科技、北京大学、理想汽车及中国科学院自动化研究所联合推出 ReconDreamer,实现了自动驾驶场景自由视角重建+生成。正如同李飞飞及其团队在「空间智能」模型中展现的革新一样,ReconDreamer 仅需要单视角输入视频,即可通过同时重建+生成构建逼真的 4D 世界,第一次实现了平移 6 米范围的高精度渲染,推动这一领域从静态跨越至动态,从单点扩展到全域通用。

-
论文链接:https://www.arxiv.org/abs/2411.19548
-
项目主页:https://recondreamer.github.io/
-
代码地址:https://github.com/GigaAI-research/ReconDreamer
-
论文标题:ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration
引言&方法概览
闭环仿真是实现大规模端到端自动驾驶落地的关键步骤,而场景重建是闭环仿真中的重要一步。现有的驾驶场景重建技术,如 NeRF 和 3DGS,受限于训练数据的分布,仅能有效重建与之相似的驾驶环境。这些方法在处理复杂驾驶操作(如变道、加速或减速)时,其重建效果往往不尽人意,尤其是在面对大幅变化的相机视角时表现欠佳。
由极佳科技领衔的 DriveDreamer4D 工作,通过利用预训练的世界模型扩展相机视角,一定程度上缓解了这些问题,但在大范围视野变化的渲染下仍有局限性。相比之下,ReconDreamer 则通过训练世界模型来减少传统三维重建算法中的伪影,并引入了一种渐进式的修复策略,确保在大幅度相机运动下的高质量渲染。
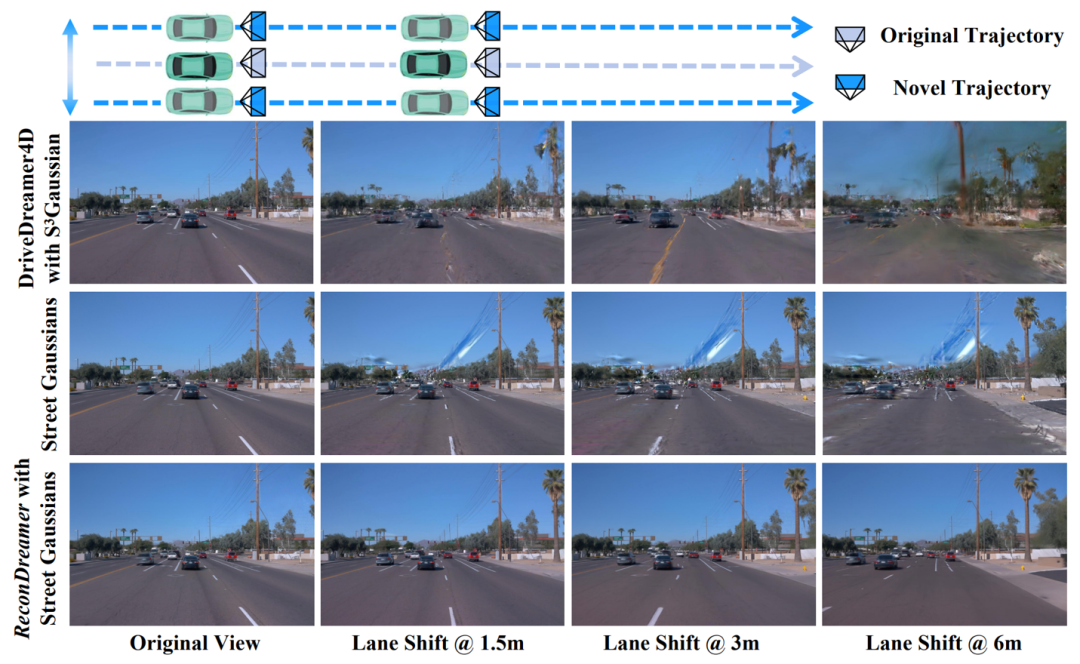
如下图所示,ReconDreamer 相较于 DriveDreamer4D 和 Street Gaussians,在大范围相机运动下展现了显著更优的渲染质量,不仅提升了驾驶前景(如车辆)和背景(如车道线)的时空一致性,还大大增强了动态驾驶场景中闭环仿真的精度和可靠性,为端到端自动驾驶系统的开发和测试提供了更为逼真和可靠的环境。
ReconDreamer 的整体框架如下图所示,首先用传统方法如 Street Gaussians 进行场景重建,然后采样新轨迹并进行渲染,为了消除渲染视频中的伪影和缺陷,创新性地利用视频生成世界模型 DriveRestorer 进行视频修复,然后将这些恢复的视频与原始视频一起用于优化重建模型。ReconDreamer 还提出了渐进式数据更新策略,从小位移渲染开始修复,逐步扩展到大范围渲染的修复,这个迭代过程会持续进行直到重建模型收敛为止。
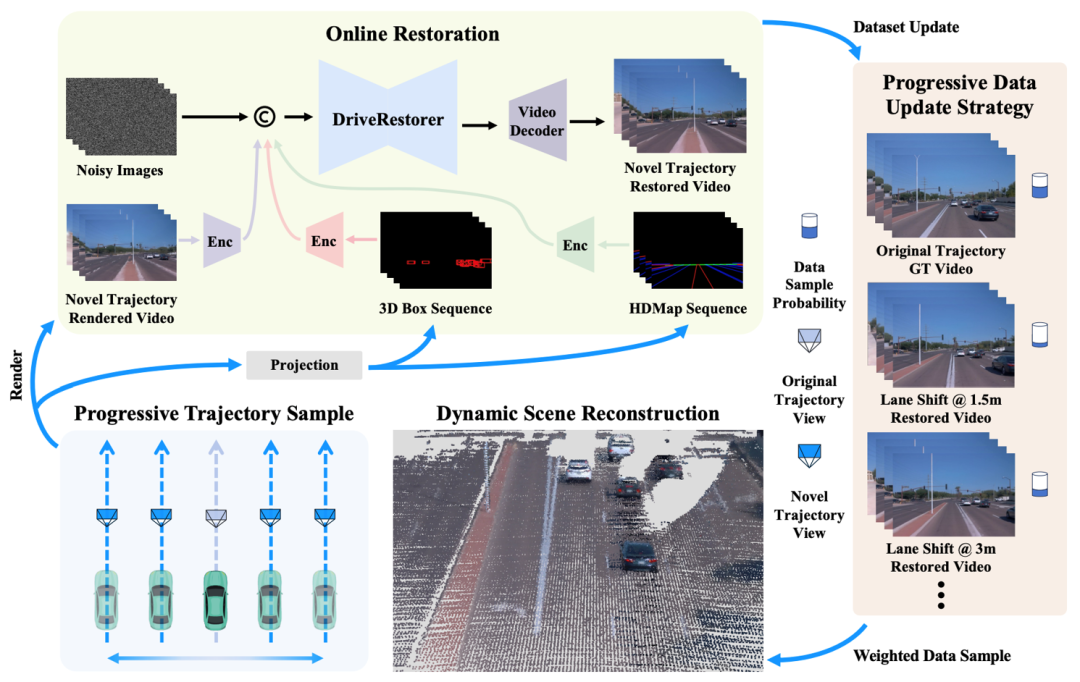
为了训练 DriveRestorer,需要构建驾驶视频修复数据集。其构建过程如左下图所示,本文使用原始轨迹的 GT 视频来训练一个欠拟合的 3DGS 模型,并在 3DGS 训练过程中渲染低质量视频。这些低质量视频与它们对应的 GT 视频配对,形成了修复数据集。在训练过程中还利用 mask 让网络加强对天空、远处区域的关注。如右下图所示为修复数据集 pair 的可视化。

经过训练后,DriveRestorer 可以修复低质量视频,如下视频所示,左下角为修复前视频,右下角为修复后视频。
此外,ReconDreamer 还提出了一种渐进式修复策略,其算法流程图如下所示,通过逐渐扩大渲染视角范围来逐步更新训练数据,以提升大范围相机运动时的渲染质量。

实验结果
在实验中,如下视频所示,可以看出当前最先进的三维重建算法 Street Gaussians 在大范围相机变换视角时(例如平移 6 米)渲染质量不佳,其车道线、天空、车辆都会模糊,甚至出现 “鬼影” 现象。而 ReconDreamer 可以提升复杂变道场景下的视频渲染效果,不仅消除了 “鬼影”,而且提升了交通元素的渲染质量,车辆和车道线都更加清晰。
此外,ReconDreamer 可以实现大范围自由视角的变化渲染,例如 z 字漂移,横跨运镜等渲染操作。
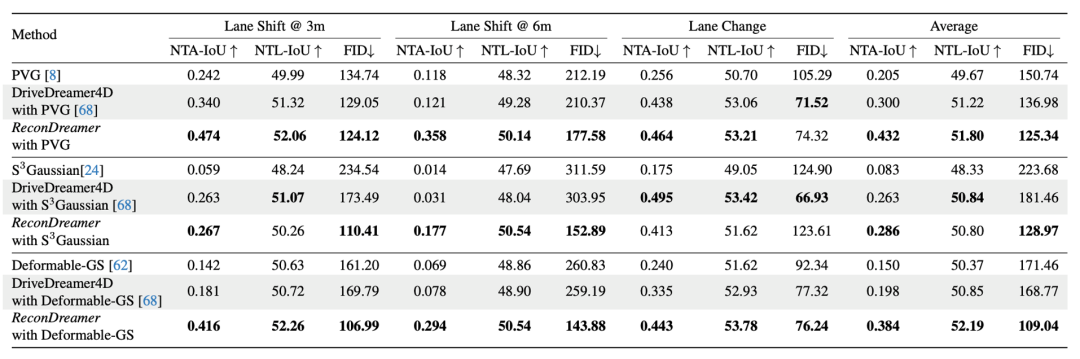
在定量实验中,本文证明了 ReconDreamer 在大范围的相机运镜渲染(例如横跨 3 米,横跨 6 米,变道)等场景下,可以显著超越传统三维重建算法的性能,尤其是提升车辆和车道线渲染的时空一致性。

不仅如此,与最近的 DriveDreamer4D 相比,ReconDreamer 所提出的渐进式修复方案可以在大范围相机运镜下显著提升渲染性能,其对比结果如下所示。
此外,本文还通过 user study 证明用户更加偏好 ReconDreamer 的渲染效果,获得了超过 95% 的投票率。

总结
本项 ReconDreamer 工作是极佳科技研究团队之前 DriveDreamer、DriveDreamer-2 和 DriveDreamer4D 工作的延续。
DriveDreamer 是首个面向真实驾驶场景的世界模型,可以根据不同的控制条件生成自动驾驶周视视频,有效提升了 BEV 感知的性能;DriveDreamer-2 在此基础上,引入大语言模型,可以生成用户自定义的驾驶数据,进一步提升了长尾和 corner case 场景下的数据生成能力。针对端到端自动驾驶和闭环仿真对于场景重建的迫切需求,DriveDreamer4D 利用 DriveDreamer 系列工作的能力,用以生成新轨迹视频(例如变道、加减速),从而大幅提升了多种 4DGS 算法的重建效果。
ReconDreamer 则是通过训练世界模型 DriveDreamer-2 让其具备视频修复能力,再通过渐进式修复方案进一步提升了大范围视角变化时的渲染效果。
团队介绍
本篇论文的牵头完成单位为极佳科技,是一家空间智能公司,致力于将视频生成提升到 4D 世界模型,赋予 AI 大模型对于 4D 空间的理解、生成、常识和推理的能力,实现 4D 空间中的交互和行动,走向通用空间智能。通用空间智能对于影视游戏、元宇宙等虚拟空间的内容创作,以及自动驾驶、具身智能等物理空间的数据生成和认知推理能力,都有巨大的价值和作用。极佳科技是国内最早开始探索和布局世界模型和空间智能方向的公司,在物理空间和虚拟空间两方面都已取得显著的技术和商业进展,获得了行业广泛的认可。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com