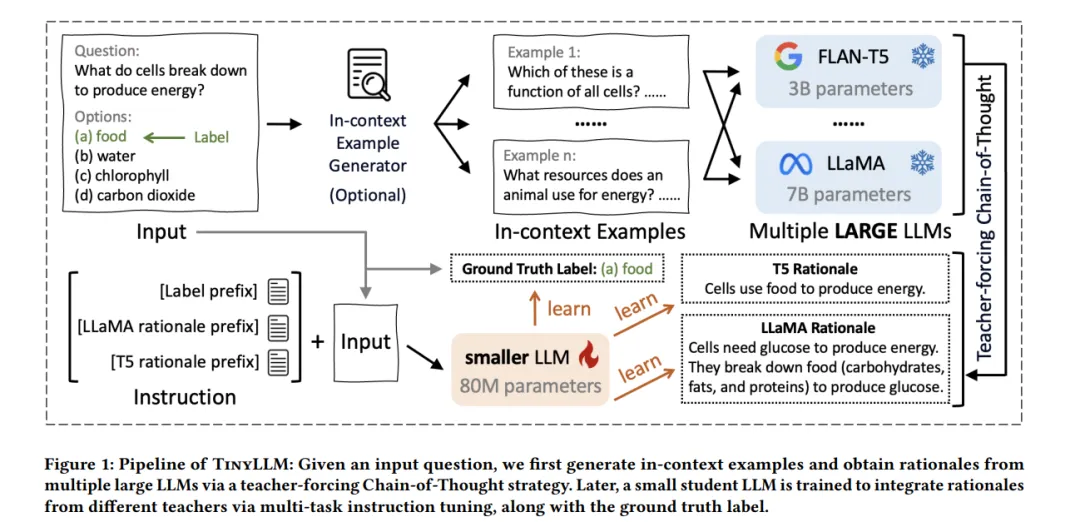
TinyLLM利用多教师知识蒸馏,显著提升小型语言模型推理能力,性能超越大型教师模型。
原文标题:【WSDM2025】通过多教师知识蒸馏将推理能力转移到小型大语言模型
原文作者:数据派THU
冷月清谈:
本文介绍了一种名为TinyLLM的新型知识蒸馏范式,用于提升小型大语言模型的推理能力。TinyLLM通过多教师知识蒸馏,从多个大型语言模型中学习,使其不仅能生成正确答案,还能理解答案背后的推理过程。
相较于现有方法,TinyLLM解决了知识多样性有限和缺乏丰富上下文信息的问题。它引入了一个上下文示例生成器和教师引导的思维链策略,确保推理过程准确且符合上下文。
在涵盖两个推理任务的六个数据集上进行的实验表明,TinyLLM的性能显著优于大型教师LLM。
相较于现有方法,TinyLLM解决了知识多样性有限和缺乏丰富上下文信息的问题。它引入了一个上下文示例生成器和教师引导的思维链策略,确保推理过程准确且符合上下文。
在涵盖两个推理任务的六个数据集上进行的实验表明,TinyLLM的性能显著优于大型教师LLM。
怜星夜思:
1、TinyLLM的多教师学习机制与传统的单教师模型相比有哪些优势?除了文章提到的,还有什么潜在的优势或不足?
2、文章中提到的“上下文示例生成器”和“教师引导的思维链策略”是如何具体运作的?它们对TinyLLM的性能提升起到了什么作用?
3、未来如何将TinyLLM等小型大语言模型更好地应用于实际场景?有哪些潜在的应用方向?
2、文章中提到的“上下文示例生成器”和“教师引导的思维链策略”是如何具体运作的?它们对TinyLLM的性能提升起到了什么作用?
3、未来如何将TinyLLM等小型大语言模型更好地应用于实际场景?有哪些潜在的应用方向?
原文内容

来源:专知本文约1000字,建议阅读5分钟
尽管模型规模较小,TinyLLM在性能上显著超越了大型教师LLMs。

将推理能力从更强大的大型语言模型(LLMs)转移到较小模型一直具有很大的吸引力,因为较小的LLMs在部署时更加灵活且成本较低。在现有的解决方案中,知识蒸馏因其卓越的效率和泛化能力而脱颖而出。然而,现有的方法存在若干缺点,包括知识多样性有限和缺乏丰富的上下文信息。为了应对这些问题并促进紧凑语言模型的学习,我们提出了TinyLLM,一种新的知识蒸馏范式,用于从多个大型教师LLMs学习一个小型学生LLM。具体来说,我们鼓励学生LLM不仅生成正确的答案,还要理解这些答案背后的推理过程。鉴于不同的LLMs拥有多样的推理能力,我们引导学生模型从各种教师LLMs吸收知识。我们进一步引入了一个上下文示例生成器和一个教师引导的思维链策略,以确保推理过程准确并且在上下文中恰当。我们在六个数据集上的大量实验,涵盖了两个推理任务,证明了我们方法的优越性。结果表明,尽管模型规模较小,TinyLLM在性能上显著超越了大型教师LLMs。源代码可在以下网址获取:https://github.com/YikunHan42/TinyLLM。