本文介绍混沌工程原理及实践,通过模拟故障提高分布式系统稳定性和可用性,并介绍Chaos Blade平台的使用。
原文标题:混沌工程初识及落地实践
原文作者:牧羊人的方向
冷月清谈:
怜星夜思:
2、除了 Chaos Blade,还有哪些其他的混沌工程平台或工具值得推荐?它们各自有什么特点?
3、文章提到了可观测性指标的重要性。在实际操作中,如何选择合适的指标并进行有效的监控?
原文内容
在分布式系统架构下,服务组件之间的调用链路和访问关系愈发的复杂,同时很难评估单个服务组件故障对整个系统的影响。监控告警的不完善导致发现问题、定位问题难度增大,同时业务和技术迭代快,如何持续保障系统的稳定性和高可用性受到很大的挑战。为此,混沌工程的出现显得尤为重要,在可控范围或环境下,通过故障注入,来持续提升系统的稳定性和高可用能力,提高业务连续性。
1、混沌工程初识
混沌工程(Chaos Engineering)是一种在分布式系统上进行由经验指导的受控实验,观察系统行为并发现系统弱点,以建立对系统在规模增大时因意外条件引发混乱的能力和信心。它的目标是提高系统对不确定事件的抵御能力。
混沌工程是在分布式系统上进行的实验科学,旨在提高系统容错性,建立系统抵御生产环境中发生不可预知问题的信心。

-
混沌工程对系统开发不同角色的提升
-
对于系统和应用架构师,可以验证系统架构的容错能力
-
对于运维和开发,可以提升故障的应急效率,实现故障的及时告警、精确定位和快速恢复
-
对于测试,从系统架构角度进行测试,弥补未知场景测试的空白
-
对于产品和设计,通过测试查看产品的表现,提升客户的体验
-
混沌工程的应用场景
-
容灾能力测试:通过故障注入,验证个别组件故障时对整个系统的影响,以及限流降级、熔断、切换、故障转移等应急手段的有效性;
-
微服务强弱依赖治理:在被调服务注入和去除故障中,观察主调服务的指标表现,获得核心服务和非核心服务之间的依赖关系和耦合度,对于不符合预期依赖的进一步优化;
-
验证系统配置的合理性:通过模拟系统资源的可用性,观察系统服务配置、副本配置和资源限制的合理性
-
监控告警:通过故障注入检测监控指标是否准确、监控维度是否完善、告警阈值是否合理、告警信息的及时性等;
-
应急演练:通过红蓝对抗等真实场景下的演练,验证相关问题处理的应急能力、应急预案和应急流程是否完善

-
建立稳定状态的假设:一是定义能直接反应业务运行状态的指标,比如交易TPS和响应时间变化等;二是故障触发时能够对系统变化做出预期的反应及指标变化。
-
用多样的现实世界事件做验证:引入真实世界中存在的且频繁发生的事件,非凭空想象的,这样的实验才有意义,比如服务调用的时延、磁盘故障等。
-
在生产环境中进行实验:尽量在类生产环境中进行测试,生产环境的多样性是其它环境没法比拟的。但是如果生产系统在某些故障场景下不具备容灾能力,不能执行混沌实验,避免发生损失。
-
自动化实验以持续运行:持续自动化的故障实验能够降低故障复发率并提前发现故障,最大程度的保证业务连续性验证。
-
最小化爆炸半径:混沌工程实施过程中需要确保对生产的业务影响最小,因此在实验过程中从小范围开始,不断扩大范围,如做好环境隔离、在业务低峰期时段执行。
混沌工程的目的是验证生产系统的稳定性和可用性,保障业务的连续性,因此在设计混沌工程实验时,遵循以上五大基本原则为基础,提高实验的价值。
-
初始级(Level 1):开始尝试进行混沌实验,但缺乏统一的混沌工程策略和规范,处于混沌实验的探索阶段。
-
已认证级(Level 2):已经完成混沌实验的探索,开始对混沌实验进行标准化管理,并开始构建自己的混沌工程平台。
-
已定义级(Level 3):已经建立起混沌实验的标准化流程和管理制度,开始对混沌实验进行量化分析,并开始构建自己的混沌工程平台。
-
已管理级(Level 4):已经建立起完善的混沌工程平台,可以对混沌实验进行全面的量化分析和监控,开始对混沌实验进行自动化的管理和优化。
-
优化级(Level 5):已经达到混沌工程能力的最高级别,拥有完全自动化的混沌实验管理能力,可以对混沌实验进行全面的优化和改进,保证软件系统的稳定性和可靠性。

CEMM可以帮助企业评估自身的混沌工程能力水平,并指导其逐步提升混沌工程能力的成熟度,实现软件系统的稳定性和可靠性。

-
准备阶段:故障演练前的准备工作,比如环境和流量的准备、监控指标项的配置等,以保证在故障注入前系统达到指定的要求,对应混沌工程稳态的假设。
-
执行阶段:按照设定的实验范围和监控指标,执行实验。执行阶段需要注意故障演练的影响范围可控、故障场景可配置化。
-
验证阶段:检查实验的结果是否达到预期、监控指标是否完善,以及对系统和业务的影响;如符合预期,可考虑扩大实验范围以全面验证系统的稳定性。
-
恢复阶段:执行故障注入的恢复操作,系统和业务恢复到演练前的状态。

在上图的混沌工程实践中,将金融行业关注的高可用案例封装成混沌案例库,其中包含高可用相关停应用、停服务、宕网卡、宕机、假死等案例,以及从生产事件、应急预案中抽象的如存储占满、损坏,交易一致性相关等案例。

-
系统可观测性:主要包含Metrics(指标)、Logging(日志)和Tracing(追踪)等。
-
业务性指标:这类指标通常和业务价值、用户体验等直接相关,是混沌工程实验中最重要的观测指标之一。
-
应用健康指标:反映应用系统的健康状况,包括错误异常、性能瓶颈、安全漏洞、TPS和响应时间变化、成功率波动等。
-
其他系统指标:反映基础设施和系统的运行状况,包括CPU使用率、内存消耗情况、网络延迟等。
这些指标可以为混沌工程实验提供有力的数据支撑,帮助团队解读实验结果、追踪问题以及最终解决问题。在指标的观测中,还可以结合一些统计学方法如贝叶斯检测、指数平滑、PCA分析等对多个指标项进行关联分析,以确定准确的系统影响。
2、开源混沌工程平台实践
Chaosblade是阿里巴巴内部MonkeyKing对外开源的项目,建立在阿里十几年的故障测试和演练基础上,GitHub地址为:https://github.com/chaosblade-io/chaosblade。Chaosblade目前支持的实验场景包括基础设施资源、Java类应用、C++应用、Docker容器和云原生平台。

1)下载Chaosblade实验包
##下载路径
https://github.com/chaosblade-io/chaosblade/releases
##解压安装包
# tar -xzvf chaosblade-1.7.2-linux-amd64.tar.gz
[root@tango-DB01 chaosblade-1.7.2]# pwd
/usr/local/chaosblade/chaosblade-1.7.2
[root@tango-DB01 chaosblade-1.7.2]# ls -l
total 39324
drwxr-xr-x 2 root root 111 May 19 11:36 bin
-rwxr-xr-x 1 root root 40265968 May 19 11:32 blade
drwxr-xr-x 4 root root 34 May 19 11:44 lib
drwxr-xr-x 2 root root 316 May 19 11:44 yaml
2)使用chaosblade模拟故障场景
##1、模拟CPU满载实验
##执行命令./blade create cpu load,code=200表示执行成功,
{"code":200,"success":true,"result":"9eb3770e8fa40287"}
##使用TOP显示执行效果,CPU使用率已经接近99%
Tasks: 163 total, 2 running, 161 sleeping, 0 stopped, 0 zombie
%Cpu0 : 98.9 us, 0.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.4 si, 0.0 st
KiB Mem : 1867024 total, 600356 free, 639152 used, 627516 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 1040792 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2003 root 20 0 710452 9632 3008 R 98.7 0.5 2:16.89 chaos_os
##销毁实验
# ./blade destroy 9eb3770e8fa40287
{"code":200,"success":true,"result":{"target":"cpu","action":"fullload","ActionProcessHang":false}}
再次查看CPU使用率,已经恢复正常
##2、指定百分比负载
# ./blade create cpu load --cpu-percent 60
{"code":200,"success":true,"result":"847419202a931560"}
##查看CPU使用情况
top - 19:30:23 up 26 min, 2 users, load average: 1.24, 1.31, 0.81
Tasks: 163 total, 1 running, 162 sleeping, 0 stopped, 0 zombie
%Cpu0 : 59.4 us, 0.3 sy, 0.0 ni, 40.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1867024 total, 602488 free, 636560 used, 627976 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 1043252 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2111 root 20 0 710452 7352 2880 S 59.5 0.4 0:24.80 chaos_os
-
chaosblade:混沌实验管理工具,包含创建实验、销毁实验、查询实验、实验环境准备、实验环境撤销等命令,是混沌实验的执行工具,执行方式包含CLI和HTTP两种。提供完善的命令、实验场景、场景参数说明,操作简洁清晰。
-
chaosblade-spec-go:混沌实验模型Golang语言定义,便于使用Golang语言实现的场景都基于此规范便捷实现。
-
chaosblade-exec-os:基础资源实验场景实现。
-
chaosblade-exec-docker::Docker容器实验场景实现,通过调用Docker API标准化实现。
-
chaosblade-exec-cri::容器实验场景实现,通过调用CRI标准化实现。
-
chaosblade-operator:Kubernetes平台实验场景实现,将混沌实验通过Kubernetes标准的CRD方式定义,很方便的使用Kubernetes资源操作的方式来创建、更新、删除实验场景,包括使用kubectl、client-go 等方式执行,而且还可以使用上述的chaosblade cli工具执行。
-
chaosblade-exec-jvm:Java应用实验场景实现,使用Java Agent技术动态挂载,无需任何接入,零成本使用,而且支持卸载,完全回收Agent创建的各种资源。
-
chaosblade-exec-cplus:C++应用实验场景实现,使用GDB技术实现方法、代码行级别的实验场景注入。
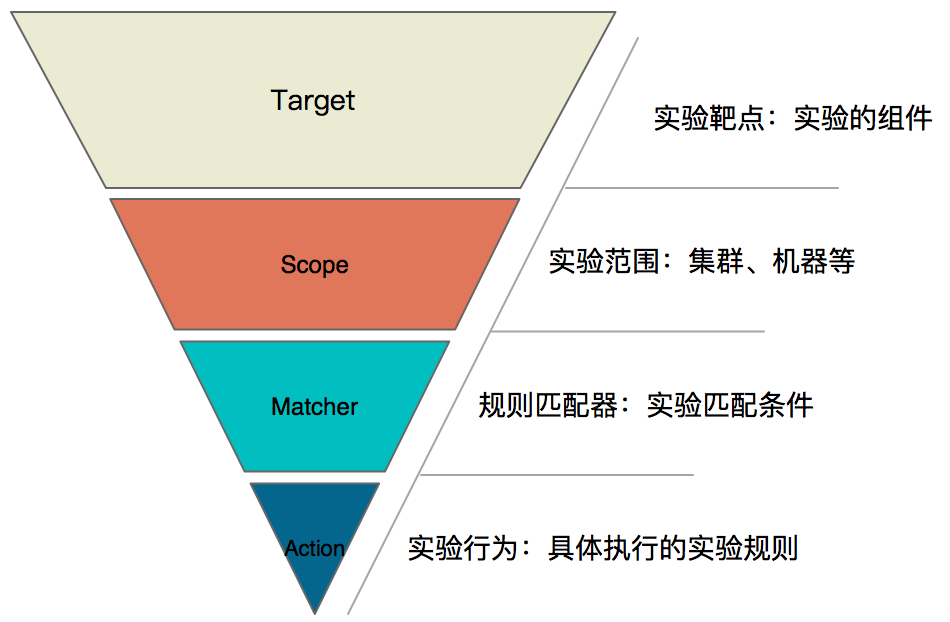
-
Target:实验靶点,指实验发生的组件,例如容器、应用框架(Dubbo、Redis、Zookeeper)等。
-
Scope:实验实施的范围,指具体触发实验的机器或者集群等。
-
Matcher:实验规则匹配器,根据所配置的Target,定义相关的实验匹配规则,可以配置多个。由于每个Target可能有各自特殊的匹配条件,比如RPC领域的HSF、Dubbo,可以根据服务提供者提供的服务和服务消费者调用的服务进行匹配,缓存领域的Redis,可以根据set、get操作进行匹配。
-
Action:指实验模拟的具体场景,Target不同,实施的场景也不一样,比如磁盘,可以演练磁盘满,磁盘IO读写高,磁盘硬件故障等。如果是应用,可以抽象出延迟、异常、返回指定值(错误码、大对象等)、参数篡改、重复调用等实验场景。
基于以上模型,再进行chaosblade故障场景的模拟实验。
参考资料:
-
[1] 阿里巴巴混沌工程实践,阿里云云栖号
-
[2] https://cloud.tencent.com/developer/article/1828940
-
[3] Netfix混沌工程成熟度模型
-
[4] 中电金信混沌工程实践平台
-
[5] 如何利用混沌工程应对未知故障,云原生基础
-
[6] https://github.com/chaosblade-io/chaosblade