GoldenDB的LoadServer工具,实现高效数据迁移和备份,支持断点续传、NULL值转换等特性,适用于多种场景。
原文标题:数据库系列之GoldenDB数据迁移
原文作者:牧羊人的方向
冷月清谈:
LoadServer的架构包含LoadServer、ClusterManager、Metadataserver和DBAgent四个模块。LoadServer负责处理客户端命令和执行数据导入导出任务;ClusterManager负责转发命令和汇总响应;MetaDataServer提供元数据信息和鉴权服务;DBAgent连接数据库节点执行命令。
数据导入流程:客户端发送请求->LoadServer解析命令并获取元数据->LoadServer拆分文件并发送导入命令->ClusterManager下发命令到DBAgent->DBAgent下载文件并导入数据->DBAgent回复响应->LoadServer汇总结果。
数据导出流程:客户端发送请求->LoadServer校验命令并获取元数据->LoadServer发送导出请求->ClusterManager转发请求到DBAgent->DBAgent导出数据->DBAgent上传数据文件->LoadServer合并文件->LoadServer发送删除命令->LoadServer发送结果信息。
LoadServer的使用需要准备充足的磁盘空间,开启FTP服务,并安装FTP客户端和expect插件。运行环境需要保证Metadataserver和ClusterManager运行正常,并保证Loadserver与它们的通信正常。LoadServer的数据目录包括backup、in、out、errordata、split/merge等。
LoadServer支持导出全量字段、部分字段和筛选字段,也支持导入全部字段、部分字段、筛选字段和加工字段,并可通过修改配置文件参数进行性能调优。LoadServer的应用场景包括异构数据库迁移和数据卸数。在异构数据库迁移场景中,通常采用全量+增量的方式,以减少停业时间。在数据卸数场景中,LoadServer可以替代Datastage等平台,提升卸数性能。
怜星夜思:
2、LoadServer的安全模式是如何实现的?除了文中提到的鉴权和目录访问控制,还有哪些安全措施?
3、在实际应用中,如何根据数据量、网络状况等因素选择合适的LoadServer调优参数?
原文内容
LoadServer是GoldenDB自研的数据迁移工具,适用于数据备份、业务迁移、数据批处理等场景,本文简要介绍loadserver的架构和功能特性。
1、数据导入导出工具loadserver介绍

LoadServer支持分布式数据库批量数据的导入和导出。在导入场景中,比如异构数据库之间的迁移如Oracle数据库迁移到GoldenDB,可以将Oracle数据库导出为文件,然后使用loadserver工具导入到GoldenDB中。在导出场景中,比如数据表的逻辑备份,替代ODS或者DATAX的功能通过文件形式对下游报表平台进行供数等。
LoadServer支持基本的导入导出功能外,还有一些面向实际使用过程中的高级特性:
1)支持断点续传
当导数过程中出现异常,数据迁移工具需要支持从中断点继续任务,提升导数的效率。针对中断的异常,loadserver中会在服务端失败文件目录或者导入临时文件目中保存本次导入失败的文件,同时会记录已经成功的记录数。当导数重传的时候,loadserver会自动到失败的目录下,将失败的文件重新导入。导数失败重试命令如下:
dbtool --loadserver -load-retry–clusterid=1 –tablename= db01.tb01
同时,loadserver也支持指定时间和指定表重新导入,命令如下:
dbtool –loadserver -load-retry –clusterid=1 -importdate=‘2017-07-07’ –tablename= db01.tb01
2)自动导入转化NULL值
当其它数据库如DB2中没有值的字段导出时,文件里是长度为0的字符串,这种字符串直接导入到mysql中会报错。为此,loadserver中支持将数据文件中的零长度字符串转换为NULL插入到表中,同时兼容DB2/Oracle和mysql。NULL模式下导入命令格式:
dbtool -loadserver -type="in" [-loadin-support-null=1] -clusterid=1
-loadin-support-null为是否支持零长度字符串配置项,1表示支持、0表示不支持,缺省为1
3)导入失败转SQL
在导数过程中会出现异常失败,业务端往往需要知道哪些数据出现了问题,待将这些数据重新处理后再导入到目标库。为满足这种场景,loadserver在load失败后将失败的数据转换为insert语句,通过这些语句可以快速定位异常问题,同时也能够形成可执行的sql脚本,再次执行。转SQL命令功能格式如下:
dbtool -loadserver -convert-to-insert -tablename | -importdir
转SQL有两种输入方式:-tablename指定表名和-importdir指定目录。指定表名会将错误目录该表所有load失败的文件转换为SQL;指定目录要求目录中存在.sql的表结构。
4)安全模式
在很多业务场景下,导数需要通过导入导出平台完成,将loadserver部署在该平台,因此不仅需要支持远程调用服务,同时也需要进行严格的权限控制。在loadserver中通过鉴权和目录访问控制来加强数据隔离:不同应用之间不能访问loadserver导入导出的数据;只有当集群ID+用户名+密码和要访问的集群匹配时候,才可以执行导入导出任务。命令如下:
dbtool -loadserver -type="out" -clusterid=1 … -user="xxxx" -password="xxxx"
loadserver中新增配置项load_trust_cluster_list,配置集群是否需要鉴权,默认为空,所有集群需要鉴权。
5)全局唯一字段
当源数据中没有唯一字段,但是导入的分布式表中需要增加全局唯一字段。loadserver中的解决方案是在导入数据时,增加文件级别的唯一字段,导数的时候会自动添加全局唯一值,保证插入的数据做到全局唯一。示例如下:
dbtool -loadserver -type="in" -clusterid=1 -skip-ok-check -set-unique-column=unique_c
选项-set-unique-column指定唯一序列字段。注意指定的唯一字段必须为表中已经存在的字段,并且不能在导入字段中列出,同时只能为一个字段,建议建表时使用bigint类型。
6)状态上报和实时查询
loadserver作为一个提供数据服务的组件,可以定时将状态信息上报,上报数据保存在rdb数据库gdb_stat_lds_task表中。上报的字段包括loadserver IP、loadserver端口、任务说明、任务开始时间、任务结束时间、导入成功数量、导入失败数量、导入/导出文件总大小、导入/导出耗时(当前时间-开始时间)、导入/导出平均速度。loadserver中的配置项statistic_report_interval指定了上报的时间间隔,默认为5分钟,0表示不上报:
#time interval for report statistic to metadataserver;unit:s;0: means timing report been closed; recommended value range:0~172800
statistic_report_interval=300
同时为了方便了解loadserver的实时负载情况,LoadServer提供了查询状态的接口:
dbtool -loadserver -q[uery] -w[ork]l[oad]
-
LoadServer:数据导入导出工具,负责处理dbtool客户端命令,执行数据导入导出任务;
-
ClusterManager:数据库集群管理中心,负责转发LoadServer命令到DBAgent模块,接收汇总DBAgent命令响应并回复LoadServer模块;
-
MetaDataServer:数据库元数据服务器,负责向LoadServer服务器提供数据库表的元数据信息,负责提供鉴权服务;
-
DBAgent:数据库监控代理程序,负责连接数据库节点,执行LoadServer服务器下发的导入导出命令。


-
用户使用dbtool客户端,向LoadServer服务器发送数据导入请求,LoadServer解析命令正确后,向MetadataServer模块发送获取元数据请求,然后校验元数据信息
-
校验通过后,LoadServer服务器在本地将导入数据文件split为小文件,当split文件达到配置的下发数目时,向ClusterManager模块发送导入命令,ClusterManager根据请求信息将导入命令下发到各DBAgent模块,DBAgent下载数据文件到临时目录并连接数据节点执行数据文件导入(并发执行)
-
DBAgent执行结束后,向ClusterManager回复数据导入响应,ClusterManager转发响应到LoadServer服务器
-
LoadServer汇总分裂文件导入结果,待收到所有文件结果后,向dbtool客户端打印本次导入详细结果信息

-
用户使用dbtool客户端发起数据导出请求,LoadServer校验命令通过后,向MetadataServer请求元数据信息,根据元数据信息获取数据分发节点。
-
LoadServer发送导出数据请求到ClusterManager模块,ClusterManager根据导出请求转发到指定数据节点的DBAgent,此时DBAgent模块连接数据节点执行数据导出命令。
-
各DBAgent执行数据导出后,将结果发送给ClusterManager模块汇总,然后转发汇总结果到LoadServer模块。
-
LoadServer发送文件上传请求,将各DBAgent导出的数据文件上传到LoadServer服务器。LoadServer收到ClusterManager汇总发送的上传文件响应后,在本地将各DBAgent节点上传的数据文件合并为一个完整的数据文件。
-
同时继续发送各DBAgent上子数据文件删除命令,然后等待ClusterManager汇总删除文件响应。
-
等以上流程结束以后,向dbtool客户端发送导出命令结果信息。
2、Loadserver工具使用
1)充足的磁盘空间:建议保证剩余磁盘空间是数据文件大小两倍以上
2)确认FTP服务开启
service vsftpd status
vsftpd (pid 3308) is running...
3)各集群节点已经安装FTP客户端和except插件
rpm -qa |grep ftp
rpm -qa |grep expect
Loadserver在执行导入导出任务时,需要与Metadataserver和ClusterManager模块进行通信,因此必须保证以上模块运行正常。
-
通过dbstate命令检查模块进程运行正常
dbstate
[metadataserver]The metadataserver process is running
[clustermanager]The clustermanager process is running
[loadserver]The loadserver process is running
-
检测Loadserver和Metadataserver的通信状态
dbtool -mds -linkstate
Send message to other module successfully!
The response message: RSP Code[0].{0:success; 1:provisional response; other: fail.}
-
检测loadserver与ClusterManager的通信状态
dbtool -cm -linkstate
Send message to other module successfully!
The response message: RSP Code[0].{0:success; 1:provisional response; other: fail.}
-
backup目录:导入任务结束,导入数据文件保存目录,由配置参数backup_path指定,是否保存文件依赖配置文件选项loadin_backup_required,默认为保存。
-
in目录:导入数据文件存放目录,由配置参数loadin_path指定,该目录中子目录名称为集群号,第一次使用需创建,并且需要将数据文件移到至该目录中。
-
out目录:导出数据文件存放目录,由配置参数loadout_path指定。
-
errordata目录:导入失败中间数据文件存放目录,由配置参数fail_file_save_path指定。
-
split/merge目录:导入/导出临时数据文件存放目录,由配置参数split_path和merge_path指定。
1)数据导入导出命令
数据导入导出命令是由Loadserver所在服务器的dbtool客户端发起的,使用命令如下:
dbtool -loadserver [OPTION]
---------------------------------------------------------------------------------------------------
#-l[ink]s[tate]:查看模块链路信息
#-l[oad-]c[onfig]:动态生效配置参数
#-type:命令类型:in-导入;out-导出
#-load-retry:导入重试
#-convert-to-insert:导入失败文件转sql文件
#-skip-ok-check:不起实际作用,仅保持业务接口兼容
#-clusterid:导入导出功能所在集群号
#-errorignore:导入过程容忍最大错误数据条数,超过该值,导入任务失败
#-backup:备份导入文件到备份目录
#-errordata:导入过程中失败数据、错误数据存放文件
#-endstate:结束阶段标志:导出:0-导出文件在out目录,并合并为一个文件;1-导出文件在out目录,不合并;2-导出文件存放在DBAgent端。导入:不填时默认导入全流程;split-导入在拆分阶段后停止
#-splitpath:导入在拆分阶段停止时指定拆分文件路径
#-sql:SQL命令
#-host:LoadServer服务器所在IP(域名)及端口
#-loadin-support-null:是否支持0长度字符串为NULL,0为不支持,1为支持
#-set-unique-column=:导入时指定文件内唯一列,注意:当使用该option时,需要列出除指定文件内唯一列之外的所有导入列
#-user=:集群鉴权用户名
#-password=:集群鉴权密码
#-q[uery] -w[ork]l[oad]:查询导入导出工作负载情况
#-tablename:重试命令中指定的表名或者导入失败文件转sql文件命令中指定的表名
#-importdate=:重试命令指定重试数据日期或者导入失败文件转sql文件命令中指定的数据日期
#-importdir=:导入失败文件转sql文件命令中指定的失败文件目录
#-exportdir=:导入失败文件转sql文件命令中指定的sql文件目录
#-batchcommit=:导入失败文件转sql文件时一次提交行数,0表示一次提交所有行,默认5000行
#-linkoffrebuild:Loadserver与Comtool断链重连参数
#-filenum=:Endstate=3时,指定导出文件数目
#-fileline=:Endstate=3时,指定导出文件最大行数
2)导入命令中SQL语法
LOAD DATA [LOW_PRIORITY | CONCURRENT] INFILE 'file_name' #CONCURRENT:LOAD data语句可与INSERT语句并行执行
[REPLACE | IGNORE] #当存在主键冲突或唯一索引冲突,REPLACE表示替换表中冲突数据、INGONE表示忽略该行导入数据
INTO TABLE tbl_name
[PARTITION (partition_name,...)]
[CHARACTER SET charset_name]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string'] #列值以’string’进行分割
[[OPTIONALLY] ENCLOSED BY 'char'|ENCLOSED BY''] #指定OPTIONALLY,非数据列值使用 'char' 字符引用,不指定则列数据值全部被 'char' 引用
[ESCAPED BY 'char'] #指定数据转义字符
]
[LINES
[STARTING BY 'string'] #指定行数据以’string’开始
[TERMINATED BY 'string'] #指定行数据以’string’结束
]
[IGNORE number {LINES | ROWS}] #忽略数据文件开始行数或列数
[(col_name_or_user_var,...)] #指定列导入,不指定则全部导入
[SET col_name = expr,...] #SET语句,对数据列值进行需要的转换
[WHEN when_clause]
[TRAILING NULLCOLS] #数据文件缺少的最后面的列,导入时用NULL补充
[gdb_format 'JCSV'] #对导入数据不做转义处理,‘/’不作为转义符,作为普通字符导入
3)导出命令中SQL语法
SELECT (col_name[,...]) FROM tbl_name INTO OUTFILE 'file_name' #指出导出的列,不支持*表示全部
[WHERE where_clause]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string'] #列值以’string’进行分割
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char'] #指定数据转义字符
]
[LINES
[STARTING BY 'string'] #指定行数据以’string’开始
[TERMINATED BY 'string'] #指定行数据以’string’结束
]
[gdb_format {'JCSV'|'nospace_filling'}] # nospace_filling表示导出数据格式没有分隔符;JCSV表示特殊字符导出时不做转义处理
Loadserver支持导出全量字段、部分字段和筛选字段。
1)导出全量字段示例
dbtool -loadserver -type="out" -clusterid=1 -sql="select id,name,rent from db01.tb01 into outfile 'tb01.data' fields terminated by ',' lines terminated by '\n';" -user="xxxx" -password="xxx"
导出的数据格式为列分隔符 ‘,’,行结束符 ‘\n’,字符串包含符‘”’。注:全部字段导出不支持“SELECT * FROM”,需要指定具体的column名称。
2)导出部分字段示例
dbtool -loadserver -type="out" -clusterid=1 -sql="select id,name from db01.tb01 into outfile 'tb01.data' fields terminated by ',' lines terminated by '\n';" -user="xxxx" -password="xxx"
SQL语句中指定需要导出的字段名可实现部分字段导出
3)导出筛选字段示例
dbtool -loadserver -type="out" -clusterid=1 -sql="select id,name from db01.tb01 where id>10 into outfile 'tb01.data' fields terminated by ',' lines terminated by '\n';" -user="xxxx" -password="xxx"
SQL语句中通过where语句筛选导出的数据
Loadserver导入功能支持导入全部字段、部分字段、筛选字段和加工字段。
1)导入全部字段示例
dbtool -loadserver -type="in" -clusterid=1 -sql="load data infile 'input.data' into table db01.tb01 fields terminated by ',' optionally enclosed by '\"' lines terminated by '\n' ;" -user="xxxx" -password="xxxx"
导入的数据格式为列分隔符 ‘,’,行结束符 ‘\n’,字符串包含符‘”’。注:导入数据文件每行必须包含命令指定行结束符,若最后一行不包含行结束符,则最行一行数据导入会丢失。
2)导入部分字段示例
dbtool -loadserver -type="in" -clusterid=1 -sql="load data infile 'input.data' into table db01.tb01 fields terminated by ',' optionally enclosed by '\"' lines terminated by '\n' ( id,name) ;" -user="xxxx" -password="xxxx"
在SQL语句后指定导入的列( id,name),其它未导入的列将置为NULL空值。注意导入部分字段的顺序要和源数据中字段顺序一致,比如源数据字段为(A,B,C,D),则导入字段可以是(A,B)但是不能是(A,C)或(B,C),否则导入会失败。
3)导入筛选字段示例
dbtool -loadserver -type="in" -clusterid=1 -sql="load data infile 'input.data' into table db01.tb01 fields terminated by ',' optionally enclosed by '\"' lines terminated by '\n' ( id,name) when id>=10;" -user="xxxx" -password="xxxx"
在SQL语句中指定WHEN进行数据筛选导入到表中。
4)导入加工字段示例
dbtool -loadserver -type="in" -clusterid=1 -sql="load data infile 'input.data' into table db01.tb01 fields terminated by ',' optionally enclosed by '\"' lines terminated by '\n' ( id,@name) set vname=concat(@name,’+’);" -user="xxxx" -password="xxxx"
通过set语句可以对导入的字段进行加工处理后再导入到表中。
当建表语句中使用自增列作为唯一索引的时候,在Loadserver导数过程中不会更新GTM中的自增序列信息,但是insert或source会更新GTM的自增序列信息,这样就会导致之后的数据insert后出现主键冲突。因此在使用loadserver导数以后,需要重置自增列的值,比如修改表db01.tb01自增列从1000000开始,执行dbtool命令:
dbtool -p -x -set-autoinc db01.tb01=1000000,c=1
c为实例ID(租户号),可以将自增列值修改为更大。GoldenDB后来的版本中优化了这个问题,在后续的使用中不需要单独处理。

在实际导入过程中,可通过lines_count_per_file或split_size_per_file控制生成的split文件大小,batch_count控制导入的并发数。由于loadserver服务器和DB数据节点之间的文件是通过vsftp方式传输的,文件传输的效率也在一定程度上影响着导数的效率。
3、Loadserver应用场景
随着业务的发展和技术的更新,很多应用系统需要迁移到异构的数据库平台,数据从集中式架构迁移到分布式架构,比如传统的Oracle/DB2数据库迁移到MySQL或GoldenDB数据库中。但是由于异构数据库之间的技术差异,比如SQL语法的兼容性、数据表设计的变化以及满足应用特殊需求的定制化功能等,很难做到不停机停服的数据迁移。
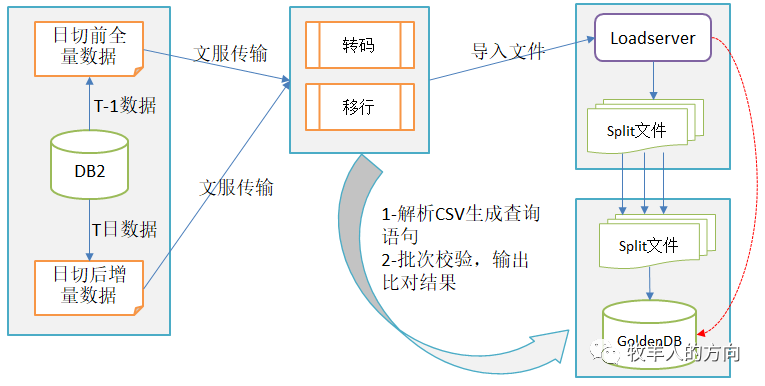
上图只是异构数据库迁移的简单例子,实际在数据迁移过程中因为停业窗口的限制,要考虑数据传输的性能、数据转码和移行的效率、源表和目标表之间的拆分转换以及如何保证数据迁移的完整性和校验核对。

如图所示,将loadserver和现有的卸数服务融合,在GoldenDB备节点导数并将多个数据文件融合为完整的数据文件传到下游业务系统进行分析。
参考资料:
-
GoldenDB分布式数据导入导出方案
-
GoldenDB分布式数据导入与导出产品手册