Spark分布式分析引擎解析:架构、核心概念RDD、运行模式及YARN执行流程介绍。
原文标题:分布式分析计算引擎Spark解析
原文作者:牧羊人的方向
冷月清谈:
Spark的核心组件包括:
1. Spark Core:提供底层服务,定义了弹性分布式数据集(RDDs)以及操作RDDs的API。
2. Spark SQL:支持使用SQL处理结构化数据,提供了DataFrame和DataSet两种数据抽象。
3. Spark Streaming:实现实时流处理,将流式计算分解成一系列短小的批处理作业。
4. MLib:提供常用的机器学习算法库,支持流水线学习模式。
5. GraphX:提供图和图并行计算的API。
Spark的架构包括Cluster Manager、Worker、Driver和Executor等组件。Cluster Manager负责资源管理和调度;Worker执行任务提交;Executor是真正的计算单元;Driver创建SparkContext,负责执行应用程序;SparkContext是Spark功能的主要入口点。
RDD是Spark中数据处理的最基本抽象,是一个只读的分区记录集合。RDD支持Transformation(转换)和Action(执行)两种操作。
Spark的运行模式包括local、standalone、yarn、mesos和k8s等。在YARN上,Spark有yarn-client和yarn-cluster两种模式。
怜星夜思:
2、RDD的惰性计算机制有什么优缺点?在实际应用中应该如何权衡?
3、Spark on YARN的两种模式,yarn-client和yarn-cluster,分别适用于哪些场景?
原文内容
Spark作为一种通用的大数据分析引擎,集成了批处理、流式查询以及交互式查询于一体,其技术体系相当复杂,本文简要介绍了Spark中的基本架构和基本概念RDD和执行流程,以及Spark on YARN两种模式。
1、Spark基本介绍
Apache Spark是一种通用可扩展的大数据分析引擎,集批处理、实时流处理、交互式查询与流计算于一体,避免了多种运算场景下需要部署不同集群带来的资源浪费。另外,Spark是基于内存的计算,相较于MapReduce或者Hive,处理效率上要提升数倍。

1)Spark Core
包含Spark的基本功能,包含任务调度,内存管理,容错机制等,为其他组件提供底层的服务。在内部定义了RDDs(弹性分布式数据集),提供了很多APIs来创建和操作这些RDDs。
-
DataFrame是spark Sql对结构化数据的抽象,可以简单的理解为spark中的表
-
DataSet是数据的分布式集合

MLIB是Spark对常用的机器学习算法的实现库,包括分类、回归、聚类、协同过滤、降维等算法,同时支持流水线的学习模式,即多个算法使用不同的参数以流水线的形式编排运行,得到算法的结果。
Spark提供的关于图和图并行计算的API,集ETL、试探性分析和迭代式图计算于一体。

集群管理器,它存在于Master进程中,主要用来对应用程序申请的资源进行管理和调度,根据其部署模式的不同,可以分为local,standalone,yarn,mesos等模式。
-
worker节点通过注册机向cluster manager汇报自身的cpu,内存等信息。
-
worker节点在spark master作用下创建并启用executor,executor是真正的计算单元。
-
spark master将任务Task分配给worker节点上的executor并执行运用。
-
worker节点同步资源信息和executor状态信息给cluster manager。
Executor是真正执行计算任务的组件,它是application运行在worker上的一个进程。这个进程负责Task的运行,它能够将数据保存在内存或磁盘存储中,也能够将结果数据返回给Driver。Executor宿主在worker节点上,每个Worker上存在一个或多个Executor进程,每个executor持有一个线程池,每个线程可以执行一个task。根据Executor上CPU-core的数量,其每个时间可以并行多个跟core一样数量的task,其中task任务即为具体执行的Spark程序的任务。
Application是Spark API编程的应用程序,它包括实现Driver功能的代码和在程序中各个executor上要执行的代码,一个application由多个job组成。其中应用程序的入口为用户所定义的main方法。
Driver的功能是创建SparkContext,负责执行用户写的Application的main函数进程,创建SparkContext的目的是为了准备Spark应用程序的运行环境。Application通过Driver和Cluster Manager及executor进行通讯,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。Driver可以运行在application节点上,也可以由application提交给Cluster Manager,再由Cluster Manager安排worker节点运行。Driver节点也负责提交Job,并将Job转化为Task,在各个Executor进程间协调Task的调度。
sparkContext是整个spark应用程序最关键的一个对象,是Spark所有功能的主要入口点。核心作用是初始化spark应用程序所需要的组件,同时还负责向master程序进行注册等。
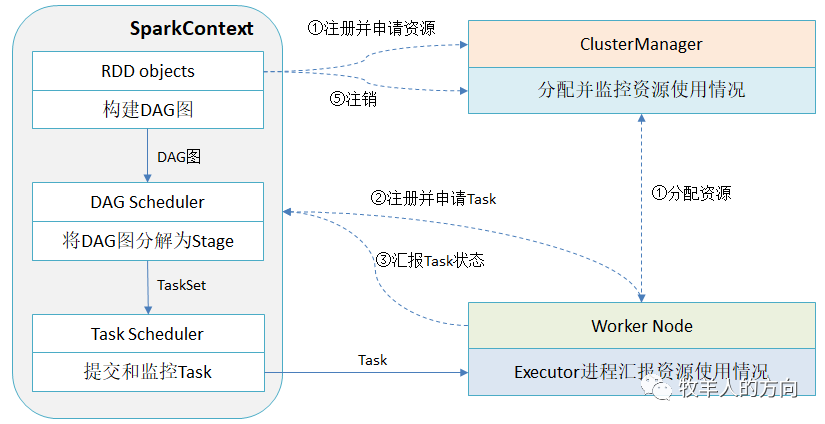
用户程序从最开始提交到最终的计算执行,需要经历以下几个阶段:
-
用户程序创建SparkContext时,新创建的SparkContext实例会连接到ClusterManager。ClusterManager根据用户提交时设置的CPU和内存信息为本次的提交分配计算资源,启动Executor进程
-
Driver会根据用户程序划分为不同的执行阶段,每个执行阶段由一组完全相同的Task组成,这些Task分别作用于待处理数据的不同分区。SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理。在阶段划分完成和Task创建后,Driver会向Executor发送Task
-
Executor在接收到Task后,会下载Task运行时候的依赖,在准备好Task的执行环境后,开始执行Task并将Task的运行状态汇报给Driver
-
Driver会根据收到的Task状态来处理不同的状态更新。Task分为两种:一种是shuffle map task,实现数据的重新洗牌,洗牌的结果保存到Executor所在节点的文件系统中;另外一种是result Task,负责生成结果数据。
-
Driver会不断的调用Task,重复2~4的过程,将Task发送到Executor执行,在所有的Task都正常执行或超过执行次数的限制仍然没有执行成功时停止。
2、Spark基本概念
RDD是弹性分布式数据集,是Spark中数据处理的最基本抽象,可以被并行操作的元素集合。RDD在本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群的不同节点上进行并行计算。
-
Transformation(转换):是对已有的RDD进行换行生成新的RDD,对于转换过程采用惰性计算机制,不会立即计算出结果。常用的方法有map,filter,flatmap等。
-
Action(执行):对已有的RDD对数据执行计算产生结果,并将结果返回Driver或者写入到外部存储中。常用的方法有reduce,collect,saveAsTextFile等。

RDD具有自动容错、位置感知性调度和可伸缩性的特点,每个RDD主要有以下属性:
-
分片Partition:数据集的基本组成单位,对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定分片的个数,默认为分配的CPU core数目
-
计算每个分区的函数:Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数,compute函数会对迭代器进行汇总,不需要保存每次的计算结果
-
RDD之间的依赖关系:RDD每次转换都会生成新的RDD,所以RDD之间会形成类似流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不需要对RDD的所有分区进行重新计算
-
RDD的分片函数Partitioner:Spark中实现两种类型的分片函数,基于哈希函数HashPartitioner和基于分区函数RangePartitioner。Partitioner函数决定了RDD本身的分片数量,也决定了RDD Shuffle输出时的分片数量
-
存储每个分片的优先位置的列表:对于HDFS文件,这个列表保存了每个partition所在块的位置。Spark在进行任务调度的时候,会尽可能的将计算任务分配到其所要处理的数据块的存储位置。
-
DAGScheduler是面向stage的高层级的调度器,DAG Scheduler把DAG拆分为多个Task,每组Task都是一个stage,解析时是以shuffle为边界进行反向构建的,每当遇见一个shuffle,spark就会产生一个新的stage,接着以TaskSet的形式提交给底层的调度器(task scheduler),每个stage封装成一个TaskSet。DAG Scheduler需要记录RDD被存入磁盘物化等动作,同时会需要Task寻找最优等调度逻辑,以及监控因shuffle跨节点输出导致的失败。
-
TaskScheduler负责每一个具体任务的执行,包括任务集的调度管理、状态结果跟踪、物理资源调度管理、任务执行和获取结果。TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。

3、Spark运行模式及运行流程
Spark的运行模式主要有以下几种:
| 运行模式 | 运行类型 | 说明 |
|---|---|---|
| local | 本地模式 | 常用于本地开发测试,分为local单线程和local-cluster多线程模式 |
| standalone | 集群模式 | 独立模式,在spark自己的资源调度管理框架上运行,该框架采用master/salve结构 |
| yarn | 集群模式 | 在yarn资源管理器框架上运行,由yarn负责资源管理,spark负责任务调度和计算 |
| mesos | 集群模式 | 在mesos资源管理器框架上运行,由mesos负责资源管理,spark负责任务调度和计算 |
| k8s | 集群模式 | 在k8s上运行 |
Spark on YARN分为两种模式yarn-client模式和yarn-cluster模式,一般采用的是yarn-cluster模式。yarn-cluster和yarn-client的区别在于yarn appMaster,yarn-cluster中ApplicationMaster不仅负责申请资源,并负责监控Task的运行状况,因此可以关掉client;yarn-client中ApplicationMaster仅负责申请资源,由client中的driver来监控调度Task的运行,因此不能关掉client。

-
ResourceManager接到请求后在集群中选择一个NodeManager分配Container资源为AppMaster作准备
-
在Container中启动ApplicationMaster进程;driver进程运行在client中,并初始化sparkContext;
-
sparkContext初始化完后与ApplicationMaster通讯,通过ApplicationMaster向ResourceManager申请Container,ApplicationMaster通知NodeManager在获得的Container中启动excutor进程;1.sparkContext分配Task给excutor,excutor发送运行状态给driver。

-
client 向yarn提交应用程序,包含ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等。
-
ApplicationMaster程序启动ApplicationMaster的命令、需要在Executor中运行的程序等。
-
ApplicationMaster向ResourceManager注册申请Container资源,这样用户可以直接通过ResourceManage查看应用程序的运行状态。
-
ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,启动excutor进程。
-
Task向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
-
应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
4、总结
Spark技术体系相当复杂,本文简要介绍了Spark中的基本架构和基本概念RDD和执行流程,以及Spark on YARN两种模式。Spark有关的开发在之前的大数据系列中有所涉及,这里不再赘述。
参考资料:
-
《Spark技术内部:深入解析Spark内核架构设计与技术原理》,张安站著
-
https://spark.apache.org/docs/latest/index.html
-
https://blog.csdn.net/weixin_45366499/article/details/110010589
-
https://blog.csdn.net/zxc123e/article/details/79912343
-
https://blog.csdn.net/crazybean_lwb/article/details/106316513