TDSQL分布式数据库采用存算分离架构,支持强一致性和高可用性,具备水平扩展能力,适用于金融等核心业务场景。
原文标题:TDSQL分布式数据库架构简介
原文作者:牧羊人的方向
冷月清谈:
核心架构包含:
* **存储层**: 由数据库节点组(SET)组成,每个 SET 采用主从高可用架构,确保数据强一致性。
* **计算层**: 由 SQL 引擎(Proxy)组成,负责 SQL 解析、分布式事务处理等,本身无状态。
* **配置管理决策调度集群**: 包括 Zookeeper、Scheduler、Manager 等组件,负责配置维护、选举决策等。
* **GTM(Metacluster)**: 提供分布式事务全局一致性,生成全局唯一时间戳。
* **运维支撑系统**: 包括 OSS、监控模块、赤兔管理系统等,简化运维工作。
TDSQL 的主要组件包括:决策组件 Zookeeper、管理模块 Manage/Scheduler、赤兔管理平台 chitu、操作接口 OSS、元数据库、监控模块 Monitor、Kafka、Agent 以及数据链路组件 DB Set 和 Proxy。
TDSQL 采用强同步复制机制,保证主备数据强一致性。容灾方面,支持多地多中心部署,本地和同城采用强同步,异地采用异步复制。
分布式特性方面,TDSQL 支持分库分表,采用 Hash、Range 和 List 等分片方案。分布式事务处理采用两阶段提交算法,保证数据一致性。
TDSQL 已在微众银行、平安银行等金融机构的核心业务系统中得到应用,基于其单元化架构和分布式特性,保障业务可用性和性能。
怜星夜思:
2、TDSQL 的两阶段提交算法如何保证分布式事务的一致性?它有什么局限性?
3、TDSQL 在金融行业的应用实践中,是如何应对高并发、高可用等挑战的?
原文内容
TDSQL数据库作为国产化数据库的代表,在金融行业等领域应用广泛,本文简要了解TDSQL分布式数据库的架构和核心组件、分布式特性,以了解。
1、TDSQL分布式数据库介绍
腾讯云数据库是腾讯云提供的一种云数据库服务,具有高可用性、高性能、可扩展性、安全可靠等特性。从TDSQL的产品矩阵中可以看到,云数据库为企业提供了完善的关系型数据库、非关系型数据库、分析型数据库和数据库生态工具。

-
强一致性:通过主备强一致性同步复制机制实现主备节点数据的一致性
-
高可用性:通过1主多备的部署架构实现高可用以及同城和灾备容灾架构
-
分布式水平扩展能力:支持数据分片和动态扩容,可以随着业务规模的增加而线性扩展。
-
高性能:通过分布式架构以及存算分离的机制,提高分布式架构下的数据处理能力
-
易运维:赤兔运维平台提供智能监控、告警、自动备份恢复等功能,简化运维工作。
-
企业级安全:提供多重安全防护措施,确保数据的安全性和隐私保护。

-
数据库存储层:由数据库节点组(SET)组成,SET是逻辑概念,由一组物理设备或虚拟化节点构成
-
SET存储数据库核心数据,采用主从高可用(HA)架构,节点数通常≥2,根据业务实际需求可扩展
-
每个节点(Node)信息采集与管理模块(Agent),互相检测心跳以确保集群的健壮性
-
数据库计算层:是由SQL引擎(SQL-Engine)组成,又称为Proxy。计算层既要管理客户端的长短连接,还要处理复杂的SQL语句进行汇总计算,属于CPU密集型高内存消耗的组件。
-
Proxy是无状态的,本身不存储数据,也没有主备之分可以同时与业务系统通讯。Proxy节点数通常≥2,根据业务实际需求进行动态扩展,并且前端需要部署负责均衡保证节点之前负载均衡。
-
Proxy层存储和处理数据库元数据,负责语法和语义解析。在分布式场景下,还需要处理分布式事务、维护全局自增字段、分布式SQL语句的下推和汇聚等。
-
配置管理决策调度集群,是由Zookeeper、Scheduler、Manager等组件组成。集群管理调度组件满足多数派选举通常需要奇数台,以基于raft协议实现对实例高可用切换的第三方选举。
-
GTM(Metacluster):提供分布式事务全局一致性的事务管理器,主要由Metacluster中心时钟源为事务的开启、提交阶段提供一个全局唯一且严格递增的事务时间戳以及事务管理器(TM)组成,为了提高并发效率TM模块目前内置于计算层。
-
运维支撑系统,是由OSS运营调度管理模块、监控采集与分析模块、赤兔管理系统组成。
以上组件共同构成了TDSQL分布式数据库的整体架构,实现分布式实例和集中式实例在数据库集群中的混合部署,并提供了扩展性、高可用性以及运维功能支持。

-
决策组件Zookeeper:提供配置维护、选举决策、路由同步等,并能支撑数据库节点的创建、删除、替换等工作,并统一下发和调度所有DDL操作;
-
管理模块Manage/Scheduler:无状态集群部署,主要用于数据库管理维护类的操作,比如数据库备份、收集监控、生成各种报表、主备切换、扩缩容、资源管理等;
-
赤兔管理平台chitu:数据库集群的可视化管理平台,提供TDSQL所有运维功能,包括管理集群的物理资源、调度决策系统、备份恢复系统、可用区管理、实例管理及性能分析与监控告警等;
-
操作接口OSS:负责接收用户的请求,使用HTTP的POST协议,根据用户请求调用对应的流程,封装获取的结果,是后台和前端的桥梁;
-
元数据库:有状态的主备集群部署,记录管理平台的任务流程、发起状态信息等;
-
Monitor:监控采集模块,从Zookeeper定期采集实例动态信息;
-
Kafka:基于Zookeeper协调的集群部署,Proxy日志持久化存储位置,以及数据同步锁依赖恶通道;
-
Agent:负责监控DB的存活状态,将健康状态上报Zookeeper,再被Scheduler感知触发切换流程。
除了以上管理链路组件,还有DB Set和Proxy数据链路组件。
-
Master等待Slave ACK超时时,返回给客户端失败,不会退化为异步复制,保证了主备数据的强一致性;
-
采用组提交的方式,增加rpl_slave_ack_thread线程,循环取出io thread接收到的binlog name和pos等信息,且只处理最后一个;
-
采用线程池+业务线程异步化,在Master等待Slave ACK的过程中将会话保存起来,然后线程切换到其他的会话处理,不用无谓的等待;
TXSQL的强同步机制,主机等待至少一个备机应答成功后才返回客户端成功,保证了数据的一致性,满足金融级的高可用要求。同时采用并行多线程和组提交技术,大幅提升主备复制的性能。

如上图所示客户端写请求提交后,线程池分配连接处理请求,但是并没有立即返回给客户端,而是将这部分信息保存在内存会话信息中。Master发起主备同步请求,接收备机收到binlog的ACK请求,当接收到备机日志落盘的ACK返回后,主节点的工作线程唤起刚刚保存的会话,执行后半段的提交操作,并将结果返回给客户端。因此在Master节点开启了两组线程:接收备机ACK应答线程(Dump ACK Thread)和唤醒hang住的客户端连接线程(User ACK Thread)。

TDSQL分布式数据库支持多地多中心的高可用部署架构,其中本地和同城作为一个可用区域,主备节点之间采用强同步方式;异地站点作为灾备可用域,生产站点的数据异步复制到灾备站点。如图所示两地三中心高可用部署采用2:2:2部署架构,生产和同城站点强同步复制保证RPO要求,当主节点故障时触发故障切换到可用的备节点。异地的逻辑主节点采用异步复制的方式同步主节点的数据,并有一个异地本地的备节点,异地的管理节点采用单独的集群和生产同城站点的区分开。当生产同城站点可用域出现异常是,可以快速的切换到异地站点,保障业务的可用性。
TDSQL分布式数据库采用计算和存储分离的方式,在计算层根据不同的分片规则将表数据分布在不同的数据存储节点中。

应用在创建表的时候需要指定分片字段shardkey,业务在增删改查时候包括分片键信息,Proxy根据不同的分片算法,将数据分发到对应的分片。如果SQL中没有指定分片键信息,则SQL会发往所有的分片。TDSQL中默认支持Hash方式进行分散,同时支持Range和list分表方案。
create table tb1 ( user_id int not null,age int not null, place char(20) not null,primary key(user_id, age) ,unique key(user_id, place)) shardkey= user_id;
如果一个查询SQL语句的数据涉及到多个分表,此时SQL会被路由到多个分表执行,TDSQL会将各个分表返回的数据按照原始SQL语义进行合并,并将最终结果返回给用户。

实际上在TDSQL数据库中物理分片和实际的数据库实例SET相对应,一个物理分片包括1主N备的SET组。但是物理分片和逻辑分表并不是一一对应的,一个物理分片上可以存储1个到多个逻辑分表,一个逻辑分表在后台对应了一个水平拆分后最小粒度的一张物理表,多个物理表组成一张逻辑大表。
分布式事务的处理是分布式数据库的关键能力,分布式事务就是指一个数据库事务在多个数据库实例上执行,并且多个实例执行了数据库操作。分布式事务处理的难点就是在多个数据库实例上实现统一的ACID原则,TDSQL数据库采用两阶段提交算法实现的。
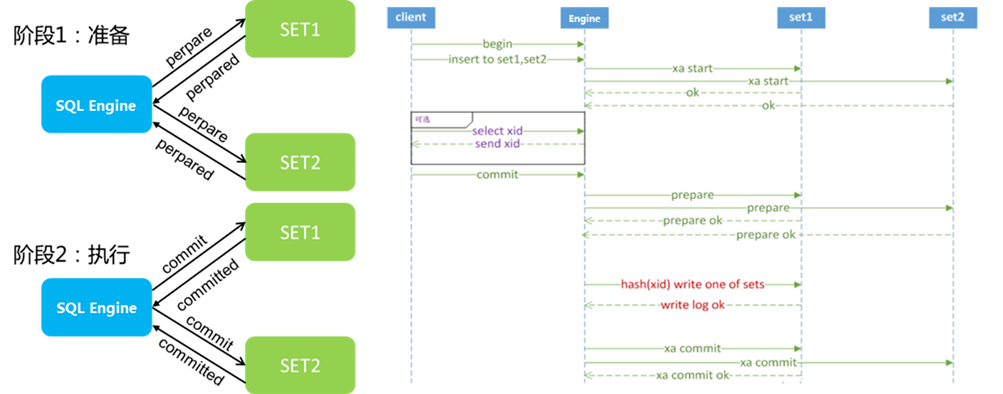
-
Prepare超时或者失败:向两个数据库分片分别进行写事务操作,当其中一个实例prepare超时或者错误的时候,会触发两个实例的XA rollback操作,并返回给客户端事务报错。
-
Commit log写失败:当其中一个实例写commit log报错时,会触发xa rollback动作,同时另外一个实例也会进行xa rollback操作,回滚完成后向客户端发送报错信息。
-
Commit log写超时:当Proxy层写commit log超时后,会返回给客户端超时,客户端继续等待一定时间后超时。
-
Commit超时或者失败:当其中一个实例commit报错或超时,会返回disconnect请求给客户端,此时会向两个实例发送disconnect断开连接。
以上是TDSQL分布式数据库的基本架构介绍以及分布式分片和分布式事务特性,TDSQL数据库在金融行业落地实践,比如微众银行、平安银行的信用卡业务、农行信用卡核心业务等核心业务系统,基于应用的单元化架构和分布式数据库的特性支撑核心业务系统,保障业务的可用性和性能。但目前受限于企业版本的使用范围,个人不能部署环境体验,尤其是赤兔管理系统,在国产化分布式数据库的运维管理这一块是业界标杆。
参考资料:
-
https://cloud.tencent.com/privatecloud/document/
-
https://blog.51cto.com/u_15721050/6004609
-
TDSQL数据库架构原理