回顾2023年国产数据库发展,探讨技术架构、选型策略、应用案例及未来趋势。
原文标题:2023年系列总结及国产数据库的一些感悟
原文作者:牧羊人的方向
冷月清谈:
金融行业对国产数据库的应用呈现出集中式和分布式并存的局面,分布式数据库应用呈增长趋势。OLTP类数据库仍占主导地位,但OLAP和HTAP类应用需求也在不断增加。非关系型数据库和开源数据库的应用也在加快探索和实践。
国产数据库的技术架构日趋成熟和标准化,行业内形成了一定的标准和规范,相关的白皮书和应用报告也为国产数据库的推广使用提供了参考。
在数据库选型方面,集中式和分布式数据库各有优势,国产分布式数据库通常集成了集中式的特性,例如多租户模式下的单分片部署,为技术转型提供了更多选择。除了传统的集中式和分布式架构外,存算分离架构也重新受到关注。
金融行业引进国产数据库的路线主要有两种:从核心系统改造试点逐步推广,或从外围系统试点试用再扩展。在选择数据库产品时,建议优先选择大厂产品,关注存量应用迁移的兼容性问题和迁移工具的平台化、在线迁移能力,并重视数据库运维平台建设。此外,应控制数据库产品的种类,避免增加技术债和运维成本,并谨慎评估数据库上云的风险,非重要业务系统可作为创新型试点。
行业内部的交流和信息共享对国产数据库的发展至关重要,一些行业大会和官方组织的活动提供了良好的交流平台。
怜星夜思:
2、文章提到了集中式和分布式数据库的选择,在实际应用中该如何选择合适的架构?
3、文章作者提到了贵阳银行核心系统改造案例,大家怎么看这个案例?
原文内容
2023年转瞬即过,回想起来这一年是一个稳中求进、稳中求变的过程。从上半年核心应用切换投产的热火朝天、心中忐忑到投产后的平稳运行,这过程中是国产分布式技术架构和国产分布式数据库的成熟稳定的基石支撑。投产后的一段时间对整个建设周期结合自己的认识做了些思考总结,也尝试参加分布式数据库大赛等和同业交流的机会,了解同业信创改造的情况。在国产化浪潮中,对新技术的涌现是乐观包容的态度,顺流而下,突破自我。本文将对国产化数据库的发展的一些体会,以及2023系列文章总结。
1、金融行业国产化数据库的推进
-
集中式分布式数据库应用占比较高,分布式数据库应用呈现增长趋势。金融业集中式数据库占比高达89%,其中银行80%、证券和保险行业占比均超90%。
-
OLTP类数据库应用占比较高,OLAP和HTAP类应用需求不断增加。
-
非关系型数据库在金融行业加快探索实践。
-
开源数据库在金融行业得到广泛使用。
在金融行业数字化浪潮和信创改造的背景下,金融行业国产化数据库在核心业务系统升级、以Oracle为代表的关系型数据库替换以及信创办公类管理系统的升级改造有序展开。金融行业国产数据库的发展也逐步进入深水区,从280+数据库厂商的群雄逐鹿到头部大厂的数据库产品在大中型金融机构的案例成熟落地,国产数据库产品的推广试用也逐渐收敛集中、技术架构逐渐成熟规范,形成了很多行业内的典型应用案例。以下是个人对国产化数据库发展的一些心得体会:
1)国产化数据库技术架构成熟和标准化
随着大中型金融机构时点国产数据库逐渐落地,在行业内已经形成的一定的标准和规范。以北京金融科技产业联盟为代表的官方组织联合金融机构和数据库厂商制定国产数据库转型的白皮书和应用报告,如《金融行业开放平台数据库转型白皮书》、《分布式数据库金融应用发展报告-2023》、《分布式数据库单元业务应用研究报告》、《GoldenDB分布式事务型数据库金融应用指南》等。这些白皮书和应用报告为国产数据库的推广使用形成一定的参考标准,包括技术架构选择、应用改造难点以及数据库迁移策略等方面。
2)集中式数据库和分布式数据库之辩
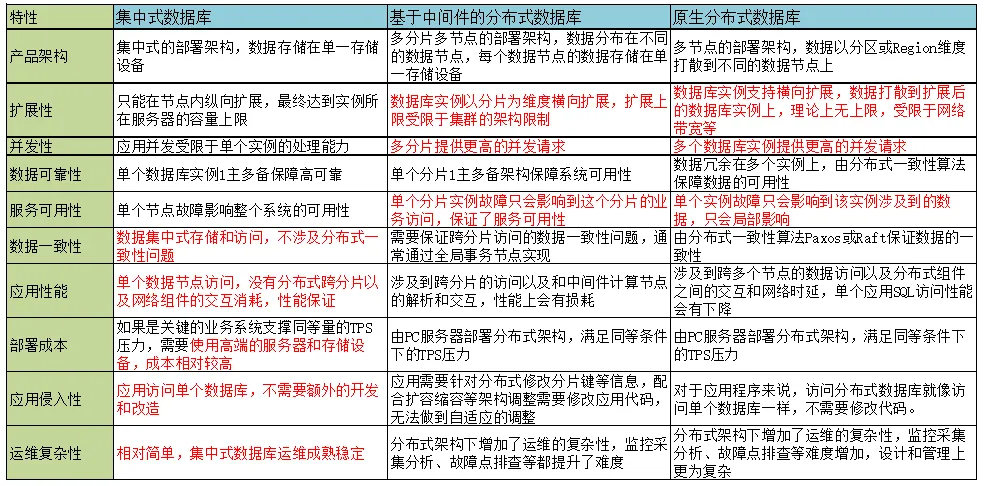

3)国产数据库试点推广范围和引进路线
对于金融行业来说,国产数据库的引进有几种路线策略:一种是由核心系统改造试点,再逐步向外围系统推广,这种路线应用改造成本高、周期长,但是和国产数据库有相互迭代共进的过程,在应用适配性改造和系统架构高可用测试、并网运行过程中能够及时的发现问题、提出优化需求以满足应用平稳切换投产的要求;另外一种是外围系统试点试用,结合信创服务器和操作系统,实现全栈信创的试点改造,项目建设周期不长、并且应用是平滑迁移,基本原有的应用使用特性如存储过程、函数等能够在迁移后的数据库上直接使用,对数据库的要求高,适用于已经在业内有典型使用场景后的开箱即用产品。
-
优先选择大厂的数据库产品,毕竟在行业内已经有成熟的落地案例,产品的成熟度和可用性也逐步完善。不排除有个别地方支持本土的信创产业,最后是有苦说不出,像贵阳银行核心就是典型的反面教材。
-
存量应用的迁移,各应用在使用习惯或历史包袱在迁移到新的数据库,存在兼容性问题,同时迁移工具能否平台化、在线迁移等,也是信创改造工作的成本考量。可以结合各数据库厂商自己的迁移工具或自研迁移工具,以满足存量应用的批量迁移改造。
-
数据库运维平台建设,原有的Oracle或DB2等集中式数据库的运维监控体系是否满足国产化数据库尤其是分布式数据库的监控目标,通常是要结合国产数据库的自身运维和监控能力和特性,对接现有的运维平台,满足监控、应急、变更、性能容量等一系列运维管理流程。
-
数据库产品的选择不是越多越好,基本上对同一类型的业务来说各数据库产品的能力同质化,比如数仓类、TP类和AP类,以及Oracle的替换、Mysql系或者PG系等。过多的数据库种类对开发运维人员来说反而增加了技术债,相应的运维管理成本也增加了。而且有些数据库厂商产品达不到Oracle的水平,收费却比Oracle贵,徒增国产化的成本。
-
数据库上云,非重要业务系统作为创新型试点使用,从架构可用性、性能角度看重要业务系统都是不建议使用。
4)行业内部的交流和信息共享

2、系列文章总结
2023年继续在分布式技术架构领域进行探索,另外增加了对自有的技术知识体系和经验的总结。全年共更新文章28篇,其中知识体系的总结整理6篇、分布式相关11篇、数据库相关4篇、容器云相关2篇、番外篇的5篇主要是ChatGPT相关的。
1、分布式核心系统运维的一点思考
在银行业数字化转型的浪潮中,银行核心系统的分布式转型也加快了进行,如何保障分布式核心系统的平稳运行、提升运维服务能力水平,对一线运维人员提出了挑战。本文将结合近3年参与分布式核心系统项目建设过程,对分布式核心系统的运维阐述自己的想法。
2、
在金融业数字化浪潮以及自主可控核心系统信创改造背景下,银行业头部的六大行积极开展分布式核心系统的升级改造工程,依据金融科技布局完成核心系统的信创改造。本文基于公开信息整理六大行的分布式核心系统改造现状以及落地进展。
国产信创服务器是近些年信创突破的重点,面对技术封锁和卡脖子限制,如何实现真正的芯片自主可控也是业界发力的方向。近期华为鲲鹏9000s系列芯片的发布让大家眼前一亮,似乎面对芯片的技术封锁打了一场漂亮的翻身仗。那么在服务器市场国产CPU发展如何,主流的信创服务器有哪些产品,性能表现如何,本文将简单介绍,并结合信创服务器的性能对比测试进行分析。
在分布式系统架构下,为了满足高并发和高扩展性的要求,负载均衡设备得以广泛的使用。结合应用连接池的配置,在实际使用过程中可能会出现负载不均的问题。本文简单介绍了负载均衡算法、Druid连接池配置以及连接池负载不均的问题分析及优化方法。
在应用系统业务连续性保障过程中,应用版本的投产部署是其中一个重要的因素。本文简要总结应用版本部署流程、版本生命周期管理以及其中的应用版本投产策略和数据库资源的投产注意点,并结合实际投产过程中潜在的问题进行总结。
GaussDB作为一款企业级的数据库产品,和开源数据库OpenGauss之间又是什么样的关系,刚开始接触的时候是一头雾水,因此本文简要对比下二者的区别,以加深了解。
任务调度是特定业务场景下的定时任务处理,在分布式架构下,分布式调度框架的设计显得尤为重要。本文简要介绍了两种常用的分布式调度框架Quartz和xxl-job的特性、基本架构和参数配置,以加深了解。
服务网关作为分布式系统对外服务的统一入口,设计功能上具有路由转发、熔断限流、安全认证以及监控等功能。本文简要介绍服务网关的基本概念,以及动态路由的实现方式,以加深了解。
面对分布式架构和微服务复杂的系统架构和网络超时服务器异常等带来的系统稳定性问题,分布式接口的幂等性设计显得尤为重要。本文简要介绍了几种分布式接口幂等性设计实现,包括Token去重机制、乐观锁机制、数据库主键和状态机实现等,以加深理解。
分布式系统架构下面对突增的高并发访问请求,如何实现限流以保护系统的可用性是需要关注的一个问题。分布式限流实现机制上有很多中,包括基于网关实现、基于中间件如Redis实现等,本文简要介绍限流的常用算法以及实现方案。
低代码开发平台近两年发展迅猛,并迅速渗透到各个细分领域。本文简要介绍低代码开发的概念以及特性,并结合低代码开发的应用场景介绍两个低代码开发平台。
DDD是一种软件设计思想和方法论,以领域为核心构建软件设计体系,将业务模型抽象成领域模型进行拆解和封装。本文简要介绍DDD的基本概念和常用的分层设计架构,并结合业务场景进行领域驱动设计的实战分析,以加深理解。
Git 是一款开源的分布式版本控制系统,具备分布式、轻量级分支、强大的协作能力以及适用于大小项目的版本管理。本文简要介绍Git工具的特性、Git中的对象以及分支管理,以加深了解。
Zabbix作为一个分布式开源监控软件,在传统的监控领域有着先天的优势,具备灵活的数据采集、自定义的告警策略、丰富的图表展示以及高可用性和扩展性。本文简要介绍Zabbix的特性、整体架构和工作流程,以及安装部署的过程,并结合实战进行监控配置。
在分布式系统架构下,服务组件之间的调用链路和访问关系愈发的复杂,同时很难评估单个服务组件故障对整个系统的影响。监控告警的不完善导致发现问题、定位问题难度增大,同时业务和技术迭代快,如何持续保障系统的稳定性和高可用性受到很大的挑战。为此,混沌工程的出现显得尤为重要,在可控范围或环境下,通过故障注入,来持续提升系统的稳定性和高可用能力,提高业务连续性。
随着分布式和微服务架构的发展,应用系统和服务组件之间的调用关系愈发复杂。如何精确的展示和快速定位服务单元之间的调用关系,实时观测应用系统整体链路情况,对应用系统的监控运维提出了挑战。本文简要介绍分布式应用链路跟踪的实现方式、OpenTracing规范以及对比不同全链路开源组件的实现。
在前文“分布式应用全链路跟踪实现”中介绍了分布式应用全链路跟踪的几种实现方法,本文将重点介绍基于Skywalking的全链路实现,包括Skywalking的整体架构和基本概念原理、Skywalking环境部署、SpringBoot和Python集成Skywalking监控实现等。
在日常运维工作中,MySQL数据库服务器出现SQL语句执行导致服务器CPU使用率突增,如何通过现有手段快速定位排查到哪个SQL语句,并采取应急措施。本文介绍基于传统的操作系统线程的CPU使用监控手段入手,利用操作系统线程ID和MySQL线程ID对应关系,逐步定位到异常SQL和事务。
最近使用MySQL 8.0.25版本时候遇到一个SQL问题,两张表做等值Join操作执行很慢,当对Join连接字段添加索引优化后,执行效率反而变得更差,其中的原因值得分析。因此本文介绍下MySQL中常见的Join算法,并对比使用不同Join算法时候的性能情况。
YashanDB数据库是全面自主设计研发,支持集中式、分布式和共享存储部署架构以及混合负载场景的超融合数据库。本文简要介绍了YashanDB的特性和部署架构,并部署1主1备的测试环境,验证数据库访问操作、主备切换高可用过程,以了解。
TDSQL数据库作为国产化数据库的代表,在金融行业等领域应用广泛,本文简要了解TDSQL分布式数据库的架构和核心组件、分布式特性,以了解。
云原生是什么,和容器技术、DevOps以及微服务之间又是什么关系。本文基于云原生技术与应用培训的知识点整理,加深理解。
随着容器技术和微服务等云原生基础技术的发展,单体应用的微服务化以及应用上云已经成为技术潮流。本文是对云原生提升培训的整理,主要介绍微服务的基本概念和架构、Service Mesh服务网格的基本概念,以及应用上云的评估策略等知识。
最近服务器环境部署了tcprtt网络时延监控,发现不同服务器不同节点之间的RTT时延表象非常奇怪,无法准确的判断服务器的网络情况。因此需要弄清楚什么是RTT,以及能否作为服务器网络性能的检测指标。
去年12月ChatGPT横空出世,在业界引起惊涛骇浪,最近又发布了GPT-4的进化版本,ChatGPT将对我们的工作生活有什么样的影响,又将如何应对?本文不讨论ChatGPT背后的具体模型算法和实现逻辑,只简单讨论ChatGPT对产业布局发展的潜在影响和机会。
元巳清明假未开,小园幽径独徘徊。春寒不定斑斑雨,宿酒难禁滟滟杯。无可奈何花落去,似曾相识燕归来。
国外ChatGPT火爆持续,前一段时间百度发布“文心一言”还没有全面放开测试,这不阿里“通义千问”又悄然而至,国内大模型AI产品渐渐浮出水面。早在2022年8月份时候清华大学的对话语言模型ChatGLM-6B就发布并开源,本文简要介绍ChatGLM-6B在本地环境的部署实践。
百度的AI模型“文心一言”使用体验的相关记录。
2023年又是一年蹉跎而过,在工作学习过程中也多了些收获和感悟。希望2024年能够继续守正创新、扬帆远航,顺祝元旦快乐。

往期推荐