如何在1-5-10的应急响应要求下,通过故障自愈和根因定位提升分布式系统的监控和应急能力?
原文标题:从1-5-10角度聊下分布式系统的监控应急
原文作者:牧羊人的方向
冷月清谈:
为了实现故障节点的自愈,首先需要消除系统中的单点,包括应用、基础设施、数据库和性能等方面的单点。同时,要确保系统具备可切换能力,并进行定期验证。此外,对于无状态节点,故障节点自动隔离也是一种有效的自愈方式。
在故障根因定位方面,文章指出,分布式系统容易出现告警风暴,因此需要对告警进行分级、压缩和归集。同时,全链路关联分析可以帮助快速定位异常节点。更进一步,排障树可以将不同层级的指标数据关联起来,通过智能算法定位故障源。
怜星夜思:
2、文章中提到的“告警风暴”问题,大家有什么好的处理经验?除了分级、压缩和归集,还有哪些方法可以有效减少告警风暴对运维人员的干扰?
3、文章提到了全链路关联分析和排障树,想问问大家在实际应用中,这些工具或方法的落地情况如何?有没有遇到什么挑战或坑?
原文内容
在日常生产运维中,在1-5-10快速应急响应的要求之下,如何快速发现问题并应急响应恢复业务,以提高业务连续性和系统的可用性。本文将讨论在1-5-10应急要求的背景下,在监控和应急上能做哪些,将围绕故障节点的自愈和根因定位两个方面进行展开。
1、1-5-10应急响应要求下的监控应急
-
MTTR(Mean Time To Resolution):是指从发现故障到最终解决故障所需的平均时间。MTTR越短,表示系统恢复的速度越快;
-
MTTA(Mean Time To Acknowledge):是指从系统产生故障到相关人员开始注意到故障并采取行动的平均时间。MTTA越短,表示系统的监控和警报系统越有效;
-
MTTF(Mean Time To Failure):是指系统无故障运行的平均时间长度。MTTF越长,表示系统越稳定,可靠性越高。

当然1-5-10的指标对监控系统和指标的完善、应急预案的可执行性、运维工具的自动化提出了更高的要求,也对一线运维人员带来了不小的压力和挑战。领导也说过,1-5-10是一个系统性工程,是运维人员的美好愿景,是未来几年需要努力实现的目标。个人理解1-5-10是建立在现有“变更-监控-应急”的完善的运维管控流程体系下、基于数据中心CMDB配置管理和全链路的监控体系才能得以实现的。各类配置数据是血,监控体系是络,建立好应用和基础设施节点之间全局的拓扑关系,才能让整个监控体系立体化。这也是一个值得深入讨论的话题,就不发散了。
本文接下去将讨论在1-5-10应急要求的背景下,在监控和应急上能做哪些,主要围绕故障节点的自愈和根因定位进行展开。
在实际生产运维过程中,多数时候系统出现故障以来系统自身的高可用或者简单的切流量能够做到故障自愈或者业务快速恢复,基本不需要人工应急干预。但有时候系统出现问题时候,简单的应急三板斧“重启、限流和杀连接”已经不能解决问题,可能故障的定位就需要花上半个小时,而此时又不是简单的应急三板斧能解决问题的。
-
应用单点:应用系统本身并不是双活或者多活架构,当需要进行站点级别的故障进行流量切换时,不具备自动化切换的条件;还有一种是应用系统是基础管控组件或者权限验证组件,本身是集中式的管控出入口,当这个点存在故障时,所有的校验都会受到影响。比如2023年11月份的阿里云和最近4月份的腾讯云故障,本质上也是因为应用单点引起的。
-
基础设施层单点:现在大多数重要业务系统的基础架构都是保证高可用的,网络交换机、负载均衡设备、防火墙、存储设备等出现异常时候都能自动切换到备节点,甚至在机房布局上也是站点级或者机房级别的高可用。对于重要业务系统,要极力避免在基础架构层存在单点的情况,因为一旦出现问题将是全局性的影响。
-
数据库层单点:数据库层在物理节点部署上基本是保证高可用的,但是当数据库逻辑数据上发生了变化,比如误删表、配置数据误更新,对上层应用来说无法通过切流量,或者简单的切主备节点来恢复,也就是名义上的单点。当然,也可以采取一些方案比如延迟库等解决这一类问题,其中涉及到运维成本和变更流程上的复杂性,那又是另外一个话题了。
-
性能单点:其实这一点很容易被忽略,在系统正常运行的时候,资源使用基本保持稳定,但是当故障切换,比如双中心的流量变成单中心的、多个负载设备变成单个负载,此时硬件层面能否承载这么大的业务流量,比如CPU、内存等资源负载或者网络传输的流量等。所以有个基本的原则是硬件层面平时资源使用率要保持在50%以下,是有必要的
因此,排查整个系统群集中是否存在单点是故障节点自愈的前提,系统在架构设计上的高可用也是可切换的必要条件之一。
-
应用流量切换:当应用侧单个中心响应时间、成功率等监控指标出现异常时,由自动化平台自动判断应急切流,以快速恢复业务。这种场景下适用于单个站点整体出现异常时,如果所有站点出现异常,仅仅应用切流是无法解决的。
-
数据库节点自动切换:在分布式数据库架构下,当单个数据库节点出现异常时,由分布式数据库检测并做出自动切换的动作。整个检测和切换的过程基本在1分钟内完成,能够达到快速恢复业务的要求。
-
基础设施层自动切换:诸如网络设备、存储设备等基础设施,在出现故障时候也能做到自动切换,并且对业务影响在秒级以内,基本实现业务无感。
但是仅仅依靠系统架构自身的检测机制来实现自动切换并不是万能的,自动切换有一套严格的标准和处理逻辑,像节点宕机、网络异常这样常见的场景数据库本身能够快速的做出判断并触发切换。而针对磁盘IO慢或者数据库访问慢等系统出现缓慢异常的半死不活的状态,是最难判断的,等发现异常的时候已经是几分钟之后,此时就需要其它监控指标进行辅助判断,并人工介入切换流程。而在应用设计上应该留有一些buffer空间,比如连接池的冗余配置,以保证应急响应的时间。
另外系统自动化代理或者节点当时的状态是否满足切换条件,都是可切换的先决条件。所以会有例行的业务连续性切换演练、系统和数据库可切换状态定时检查等可切换验证的手段。有时候开玩笑说这就是“薛定谔的切换状态”,只有在进行切换的那一时刻才知道能否进行切换,不过这点高可用机制还是能够保证的,不然都无法建设高可用了。
-
对于应用节点出现异常,由服务注册和发现中心主动将故障节点踢出应用集群,以避免流量分发到故障节点;
-
对于分布式数据库层的计算节点出现故障时,数据库驱动层或负载均衡侧将故障节点隔离,流量不会分发到故障节点,优先保障业务;
-
在硬件层面如网络交换机、负载均衡设备或者磁盘等,也能将故障点剔除系统,以实现故障隔离的目的。
不过在故障自动隔离的过程中会有业务影响,也是不可避免的。
在分布式应用系统架构下,节点多并且网元架构复杂,单个节点的异常对整个系统群集都有影响,表现在各个渠道上的监控指标上。如下图是简单的应用系统架构图,当数据节点主节点故障时,从应用层到数据库层会触发多级告警。
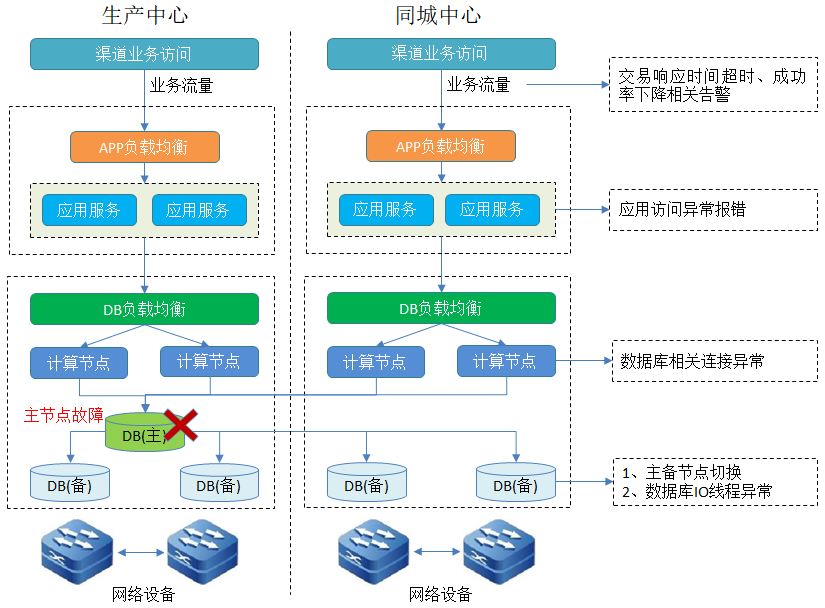
-
从直观上判断告警风暴出现多是由于系统层级的全局影响导致的,一般是节点宕机或者核心网络异常;在分布式多分片架构下通过交易成功率能判断影响范围是单个节点异常还是全局影响。
-
告警分级策略的必要性,对不同故障场景和节点产生的告警进行重要和一般等告警分级策略,比如访问主节点异常为重要级别,而由此导致的链路异常或者备机线程异常等都是次生影响,基于此能够更准确的定位到故障源。
-
告警压缩和归集能力,监控中心应具备告警源的归集,将同一告警源导致的告警进行压缩归并,以减少告警风暴。
当然,如果是站点级网络异常导致的问题,告警风暴可能会有成千上万条,为故障的快速定位又增加了难度。
其实从分布式数据库的系统视角,已经有了整个数据库集群的拓扑和元数据信息,应具备当某个节点异常时,直接将这个节点的影响按照故障等级抛出,快速的聚焦到某一个节点。然后按照节点类型采取节点隔离或切换的方式实现故障自愈,以快速的恢复业务。
在现有的监控体系下应用层、数据库层和服务器层都配置了丰富的性能或状态类的监控指标。大多数情况下,当系统中某个节点出现异常时,不同层级的监控指标会有体现,或是故障节点导致的表象,或是由故障节点直接引起的。这些指标数据之间是独立的,但是又存在某种关联,需要某种机制将其串联起来,排障树的最初目的就是这样,将各个层级的指标数据关联起来,并基于智能算法定位出故障源。
但是一些由于数据库产品缺陷或应用设计上缺陷导致的问题,即使定位到故障源还需要深入分析故障的原因,包括抓包分析、测试环境复现等方法,在应急恢复的时候采用回退版本、修改配置等非常规的应急处置来解决。
以上是在1-5-10应急响应和恢复的运维要求下,基于故障节点自愈和故障根因两个方面进行的一些思考。限于个人理解上的不足,或有不当之处。
参考资料:
-
1-5-10快恢在数字化安全生产平台DPS中的设计与落地
-
浅谈云原生可观测,匠心独运维妙维效