AI生成图像污染数据集会影响在线持续学习效果,本文提出的ESRM方法可有效缓解此问题。#NeurIPS2024
原文标题:【NeurIPS2024】《应对在线持续学习中的合成数据污染》
原文作者:数据派THU
冷月清谈:
随着 AI 生成图像技术的进步,合成数据污染数据集的问题日益凸显。本文探讨了这种污染对在线持续学习 (CL) 的影响,发现污染数据集会显著降低现有在线 CL 方法的性能。为解决这个问题,研究者提出了一种名为“基于熵选择的真实-合成相似性最大化 (ESRM)”的新方法,旨在减轻合成图像污染带来的负面影响。实验结果表明,ESRM 方法,尤其是在污染程度较高的情况下,能有效缓解性能下降,提升在线持续学习模型的鲁棒性。
怜星夜思:
1、除了 ESRM,大家觉得还有哪些方法可以用来 mitigating 合成数据污染对在线持续学习的影响?
2、文章提到合成数据污染会影响模型性能,这具体会体现在哪些方面呢?比如准确率、泛化能力等等。
3、未来随着合成数据越来越多,如何区分真实数据和合成数据将成为一个很大的挑战。大家觉得除了技术手段外,还需要哪些方面的努力?
2、文章提到合成数据污染会影响模型性能,这具体会体现在哪些方面呢?比如准确率、泛化能力等等。
3、未来随着合成数据越来越多,如何区分真实数据和合成数据将成为一个很大的挑战。大家觉得除了技术手段外,还需要哪些方面的努力?
原文内容

来源:专知本文约1000字,建议阅读5分钟
我们的实验结果表明,受污染的数据集可能阻碍现有在线CL方法的训练效果。

近年来,生成高保真真实感图像的能力取得了显著进展,特别是随着基于扩散模型(Diffusion-based Models)的技术发展。然而,人工智能生成图像(AI-generated images)的普及可能对机器学习社区带来尚未明确识别的副作用。同时,深度学习在计算机视觉领域的成功依赖于从互联网收集的大规模数据集。随着大量合成数据被添加到互联网上,未来研究人员可能难以收集到不含人工智能生成内容的“干净”数据集。
已有研究表明,当训练数据集中包含合成图像污染时,模型的性能可能会显著下降。在本文中,我们探索了数据集污染对在线持续学习(Online Continual Learning, CL)研究的潜在影响。我们的实验结果表明,受污染的数据集可能阻碍现有在线CL方法的训练效果。
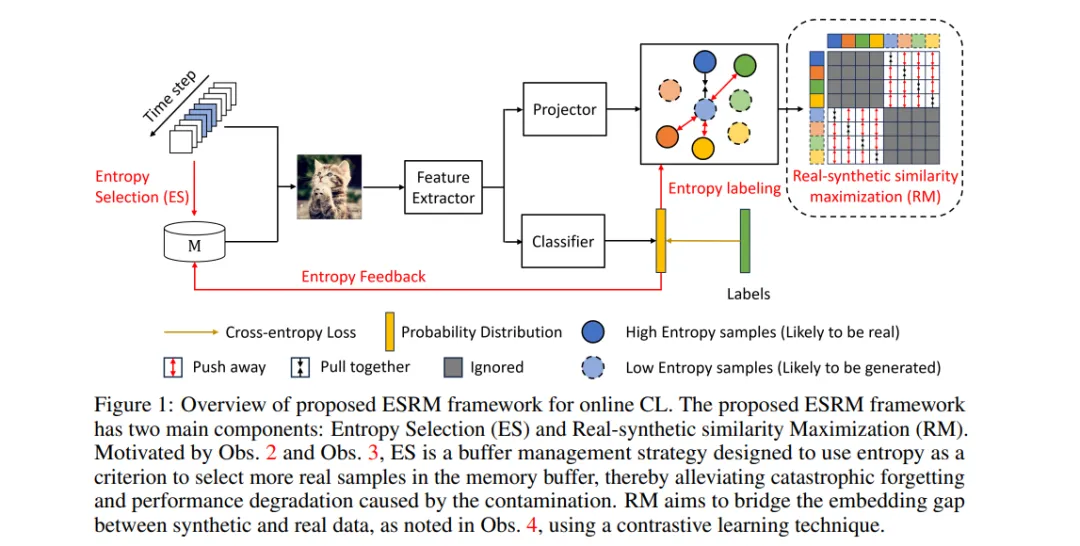
为缓解合成图像对在线持续学习模型性能的负面影响,我们提出了一种新的方法:基于熵选择的真实-合成相似性最大化(Entropy Selection with Real-Synthetic Similarity Maximization, ESRM)。该方法的核心目标是在训练过程中减轻由合成图像污染导致的性能下降问题。实验结果表明,特别是在污染程度较高的情况下,我们的方法显著缓解了性能下降。
为了保证可复现性,我们的工作源码已公开,地址为:https://github.com/maorong-wang/ESRM。