华科大团队利用AI技术,提出一种新的基于扩散模型的甲骨文破译方法OBSD,显著提高了甲骨文识别准确率。
原文标题:入选ACL 2024!引入零样本学习,华中科大发布针对甲骨文破译优化的条件扩散模型
原文作者:数据派THU
冷月清谈:
研究人员使用了HUST-OBS和EVOBC数据集,并采用OCR技术作为评估标准。由于甲骨文与现代汉字结构差异巨大,直接应用扩散模型效果不佳。因此,研究引入了局部结构采样(LSS)概念,帮助模型学习甲骨文局部部首结构与现代汉字的映射关系。此外,还引入零样本学习策略,利用不同现代汉字书写风格提高模型对字符结构的理解能力。
实验结果表明,OBSD在单轮和多轮解密评估中均表现出色,识别准确率显著高于其他图像到图像的转换方法。消融研究也证明了LSS模块和零样本学习策略的有效性。该研究为甲骨文破译以及其他古文字识别提供了新的思路。
怜星夜思:
2、零样本学习策略在甲骨文破译中是如何应用的?它与传统的机器学习方法有什么不同?
3、除了文中提到的方法,还有哪些技术可以用于古文字的识别和破译?未来的研究方向有哪些?
原文内容

本文约4900字,建议阅读10+分钟
在大数据、云计算、人工智能等数字技术的助力下,甲骨文研究已经进入了一个全新时代。

华中科技大学白翔、刘禹良研究团队联合阿德莱德大学、安阳师范学院、华南理工大学,训练出了一种针对甲骨文破译优化的条件扩散模型 Oracle Bone Script Decipher (OBSD),为自然语言处理难以解决的古文字识别任务提供了一种新颖的方法。
文字是文明的标志,也是一个民族最显著的印记。甲骨文 (OBS) 作为我国已知最早且成系统的文字,承载着中华民族一脉相承的文化与文明。从 1899 年,一位学者在中药铺偶然发现带有甲骨文的龟甲开始,甲骨文的研究就成为了学术界的热点。
在甲骨文的所有研究中,识别与释读是最核心的问题。然而,在迄今已发现的 4,500 多个甲骨文单字中,仍然有约 3 千个单字未获识别,甲骨文研究也进入了一个难以突破的瓶颈期。
随着 AI 技术的兴起,利用现代技术理解这门古老的语言为研究人员的探索提供了一条全新思路。然而,过往的研究方法主要基于已被破译甲骨文的认识和理解,如何利用 AI 辅助破译具有非数字文本、样品损坏严重、语料库缺失等多重问题的未知单字,仍然是有待探索的全新领域。
针对于此,华中科技大学白翔、刘禹良研究团队联合阿德莱德大学、安阳师范学院、华南理工大学,利用基于图像的生成模型,训练出了一种针对甲骨文破译优化的条件扩散模型 Oracle Bone Script Decipher (OBSD),该模型利用甲骨文的不可见类别 (unseen categories) 作为条件输入,以生成对应的现代汉字图像,为自然语言处理难以解决的古文字识别任务提供了一种新颖的方法。
相关研究以「Deciphering Oracle Bone Language with Diffusion Models」为题,已被 ACL 2024 主会接收。
研究亮点:
* 通过全面的消融研究和基准测试,证明 OSBD 在解码方面的有效性

论文地址:
https://doi.org/10.48550/arXiv.2406.00684
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
数据集:采用甲骨文最大存储库,以 OCR 技术作为衡量标准
为了训练和评估所提出的 OSBD 模型,该研究选择了 HUST-OBS 数据集和 EVOBC 数据集,它们是甲骨文的最大存储库之一,包含 7,1698 张图片描绘的 1,590 个不同的字符。
考虑到破译未知的甲骨文通常需要更为全面的专业验证,该研究仅将已被破译的文字作为测试集,从而简化了整个评估过程。更重要的是,该研究还对测试集中选择过的字符类别专门在训练集中进行了排除,确保该模型被用来破解的是从未处理过的字符。该数据集按 9:1 的比例划分为训练集和测试集,为评估提供了可靠的框架。
另外,虽然 OSBD 模型是从图像生成的角度进行甲骨文破译,但传统的 SSIM 等图像生成度量指标并不适合这项任务。因此,该研究采用 OCR 技术作为对破译成功结果判定的更客观的衡量标准。具体来看,研究人员通过使用 ResNet-101 骨干网络的简单分类器定制 OBS-OCR 工具,专门针对包含 88,899 个现代汉字类别的大型数据集进行训练,以评估模型的输出。
结果表明, 定制 OCR 工具实现了 99.87% 的识别准确率,证明了破译结果的可靠性。同时,该研究还广泛引入了开源中文 OCR 工具 PaddleOCR 1,从而进行进一步的评估。这种双 OCR 方法为模型破译甲骨文的有效性提供了强大保障。
以条件扩散模型为基准,重构 OBSD 模型
这项研究将训练集表示为 S = {(si, ci) | si 是一个甲骨文实例,ci∈C},即将甲骨文实例与一组已知类别 C 中的现代汉字对应起来,并在现有匹配缺失的地方提出新的字符形式。为了实现这一点,该研究基于扩散模型将甲骨文字符图像 X 转换为其现代汉字等价物。
如下图所示,该模型分为两个阶段:

甲骨文译码的条件扩散模型
在前期阶段中 (Noising),研究人员通过向现代汉字图像 X0 引入噪声,利用可控的马尔可夫链过程,将其过渡到类似于纯噪声的状态,最终形成高斯分布 N (0, I)。
在去噪 (Denoising) 阶段中,研究人员使用 U-Net 架构训练模型 fθ 预测噪声 e 和恢复图像,并且利用 et ∼ N(0, I) 引入随机性,以增强模型生成结果的多样性,最终解码的结果是生成去噪图像 X0。
在此基础上,OBSD 模型集成了初步破译阶段(Initial Decipherment)和零样本学习阶段(Zero-shot Refinement),以提高解密精度,如下图所示。

OBSD 概述
首先,通过对甲骨文图像 X 进行条件扩散以逼近初始图像 X0,然后通过零样本学习方法对其进行改进,并且利用 Xref 作为参考来纠正和增强结构。受益于改进过程中对文字结构的洞察,最终生成了对标现代汉字的文字结果 XF。
引入 LSS 概念,增强模型在古代文字与现代汉字之间的连接能力
然而,在实际的应用案例中,这样训练的模型并不能准确生成所对应的现代汉字,而是基于大量随机片段构成了一些胡言乱语,如下图所示。

直接应用条件扩散模型导致破译失败
研究人员推测造成这个结果的原因是:扩散模型主要是为了生成自然图像而设计,但在甲骨文破译过程中,甲骨文图像与现代汉字之间的结构存在极大差异,这使得标准条件扩散模型无法准确重建目标现代汉字。

汉字「宗」的对比分析
为了解决这一挑战,该研究引入了局部结构采样 (LSS) 概念,帮助扩散模型学习如何将甲骨文的局部部首结构映射到相应的现代汉字之中,从而增强模型在古代文字与现代汉字之间的连接能力。研究还发现,尽管从古代汉字到现代汉字存在相当大的结构演变,但某些局部结构得到了保留。
为了使扩散模型能够学习局部结构的特征,LSS 模块采用滑动窗口方法将目标现代汉字图像 X0∈RHxWx3 和对应的甲骨文图像 X∈RHxWx3 分割成大小为 p×p 的 D 个小块,表示为 X(d) 和 Xt(D)∈Rp×p×3, D=1,2…D, p=64。在这里,Xt 表示在时间步长 t 上添加高斯噪声 ϵt 的现代文本图像。

OBSD 初始破译的总体流程
基于此方法,模型可通过学习甲骨文的局部结构和汉字结构的细小差别来迭代和优化补丁。该研究方法的独特之处在于,它在没有完成去噪的情况下,就在每个时间步长 t 上对相邻区域之间的重叠进行平均,以确保共享区域的均匀效果。同时,该研究通过在平滑采样过程中的区域性过渡,避免了边缘差异,保持了重建图像的视觉一致性。
引入零样本学习方法,增强模型对字符结构的理解能力
尽管使用局部结构采样生成现代汉字取得了一定进步,但最初的破译工作仍然会遇到结构变形和伪影等明显的障碍。

破译初期出现大量伪影和变形
这是由于使用的是多对一训练方法,即将多个甲骨文实例与一个现代汉字图像进行映射,导致在捕捉字符演化时出现混淆和不准确,并且由于现代汉字样本有限,导致出现了不完整的结构。

多对一和一对一训练范例的比较
为了克服这些挑战,该研究提出了一种零样本学习策略,通过使用不同的现代汉字书写风格来提高模型对结构的理解。在实际操作中,该研究在 20 种不同的现代汉字字体上,以一对一的方式训练了该模块,从而学习了不同现代汉字书写风格之间的结构变换,增强了模型对字符结构的理解能力。
如下图所示,该零样本学习方法基于一个通用字体风格转换框架,通过双编码器系统,使源字体图像 X0 的样式适应目标样式 Xref,同时保留内容完整性。风格编码器 Es 从 Xref 提取样式特征 es,而内容编码器 Ec 处理 Xo 和 Xref 以获得多尺度内容特征 Fo,并通过具有多尺度内容聚合 (MCA) 和参考结构的 Font U-Net 进行精炼。训练完成后,即可直接使用零样本学习模块对扩散模型生成的结果进行优化。
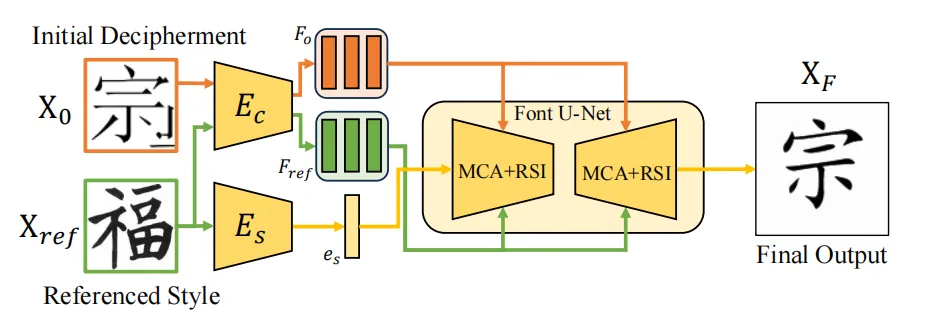
零样本学习策略概述
OSBD 表现评估:在多重评估标准下的识别准确率均为最高
为了定量评估 OSBD 的表现,该研究使用了单轮解密和多轮解密两种不同的评估标准。由于没有专门用于甲骨文破译的工具,该研究采用了一个比较框架,使领先的图像到图像的翻译方法适应于这项任务。
具体来看,这些方法包括 Pix2Pix, CycleGAN, DRIT ++ 等基于 GAN 的方法,以及 CDE, Palette, BBDM 等扩散模型。这种设定保证了 OBSD 方法能够在最新的图像转换背景下进行评估,并且确保了公平的一致性训练和测试条件。
在单轮解密评估中,OBSD 在破解甲骨文方面相较于修改后的图像到图像的转换方法具有显著优势,如下图所示。
OSBD 通过 OBS-OCR 和 PaddleOCR 实现的 top-1 准确率分别为 41.0% 和 30.0%,表现相较于其他方法更优。随着排名的提高,准确度有明显的改善趋势,在 top-500 准确率下,OSBD 达到了 64.5% 的 OBS-OCR 识别准确率。

单轮解密成功率比较
值得注意的是,所有基于 GAN 的方法(如 Pix2Pix、Palette、DRIT++ 和 CycleGAN)在这种情况下表现出的有效性最差,top-1 准确率为 0%。这可能是由于 GAN 本身难以捕捉用于破译甲骨文所需的复杂且微妙的映射关系。
在多轮解密评估中,OBS-OCR 在多次尝试中的成功率逐渐提高,指标从 41.0% 的成功率不断提升到 80.0%,如下图所示。

多轮解密成功率比较
PaddleOCR 指标的增长趋势也呈上升趋势,从 30.0% 开始最终达到了 58.5%。这些结果都验证了通过连续尝试可以实现增量改进。
为了进一步考察各个组件的影响,该研究还进行了消融研究,重点关注了 LSS 模块和零样本学习。结果表明,仅使用基本条件扩散模型对甲骨文进行解码存在局限性,具有显著较低的准确率。具体来说,在没有任何增强的情况下训练扩散模型会导致输出基本上毫无意义。

OBSD 的消融研究
通过引入 LSS 模块,OBS-OCR 的识别准确率提高到了 37.5%,PaddleOCR 提高到了 24%。通过将零样本学习模块与 LSS 配合使用,可进一步提高 OBS-OCR 和 PaddleOCR 的 Top-1 准确性,分别额外增加了 3.5% 和 6%。
最后,该研究还对各种图像到图像的转换模型进行了定性研究。

OBSD 与其他图像到图像翻译框架的比较
结果表明,通过 OBSD 方法输入甲骨文能够产生最准确的现代汉字破译,并且能够辨别甲骨文的复杂细节,这些结果不仅突出了 OSBD 的有效性,还突显了它作为甲骨文语言破译专家工具的潜力。
当甲骨文遇到人工智能,古老文字终焕新机
在古文字研究领域,尤其是甲骨文研究方面,华中科技大学一直以来都立于时代的最前沿,是国内最早建设自主甲骨文字库的和高校之一。随着人工智能技术的快速发展,文字和图像智能处理成为人工智能科研领域的热点之一,以白翔、刘禹良研究团队为代表的华中科技大学再次当仁不让的成为文字图像智能的拓荒者与引领者
白翔教授作为国家杰青、IAPR Fellow,现任华中科技大学软件学院院长、机器视觉与智能系统湖北省工程研究中心主任等职务。此前,白翔教授主导开发的 Monkey 多模态大模型就曾获大模型权威榜单 OpenCompass 开源版榜首,成果已被应用于武汉龙头软件企业的创新产品。
作为白翔团队核心骨干,刘禹良入选了第九届中国科协青年人才托举工程项目,聚焦文字图像智能,在文档智能分析、视觉与自然语言理解、多模态大模型等方面取得了一系列工作成果。
伴随着技术的发展逐渐成熟,为了在甲骨文研究方面取得更大突破,白翔与刘禹良教授与毅然选择了与国内甲骨文研究顶尖机构之一的安阳师范学院进行深入合作。2018 年,安阳师范学院甲骨文信息处理教育部重点实验室获批立项建设;2019 年,由实验室精心打造的集甲骨文文献库、著录库、字库三库合一的甲骨文大数据平台「殷契文渊」向全世界开放,这是世界上现有资料最齐全、最规范、最权威的甲骨文数据平台,它的开放标志着甲骨学研究进入智能化时代。
值得注意的是,本文的通讯作者之一的刘勇革正是安阳师范学院甲骨文信息处理教育部重点实验室主任。
为了更好的记录和传播甲骨文研究工作,该实验室于 2023 年重点做了两件大事:一方面,联合腾讯 SSV、中国社会科学院考古研究所安阳工作站、安阳市文物局,共同启动了「甲骨文全球数字化回归计划」,利用上亿像素的相机,实现了甲骨实物在数字空间的高保真还原和保护。另一方面,该实验室和腾讯公司联合推出的「了不起的甲骨文」小程序,让甲骨文进一步走近大众。
无独有偶,为了方便学者更加便捷找到甲骨缀合的信息,缩短研究前期资料收集阶段的时间,复旦大学出土文献与古文字研究中心的博士生杨熠、黄博、程名卉于 2023 年初共同联手打造了「缀玉联珠」甲骨缀合信息库,汇集了《甲骨文合集》出版以来,众多学者的甲骨缀合成果,共 6,700 多组,不仅成为了学界检索甲骨缀合主要成果的线上工具,也让不少「象牙塔」外的甲骨文爱好者有机会共同参与甲骨碎片的破案工作中,提供勘误和新的甲骨缀合信息。
由此可见,在大数据、云计算、人工智能等数字技术的助力下,甲骨文研究已经进入了一个全新时代。随着研究的不断深入,相信这项「冷门绝学」也终将在不远的将来被破解出更多密码,并且为破解其他古文字起到十分重要的借鉴意义。
