Salesforce 推出时间序列预测基础模型 Moirai,引入多尺寸补丁、任意变量注意力和混合分布等创新技术,但实际预测案例中表现逊于 Chronos。
原文标题:Moirai:Salesforce的时间序列预测基础模型
原文作者:数据派THU
冷月清谈:
Moirai 的核心在于其大规模多样化的数据集,包含 270 亿个观测值,涵盖九个不同领域。模型引入了三个关键概念:
1. 多尺寸补丁投影层:将时间序列分割成不同大小的“补丁”,以便更好地捕捉局部语义信息,并提高注意力机制的效率。补丁大小根据数据频率调整,低频数据使用较小的补丁,高频数据使用较大的补丁。
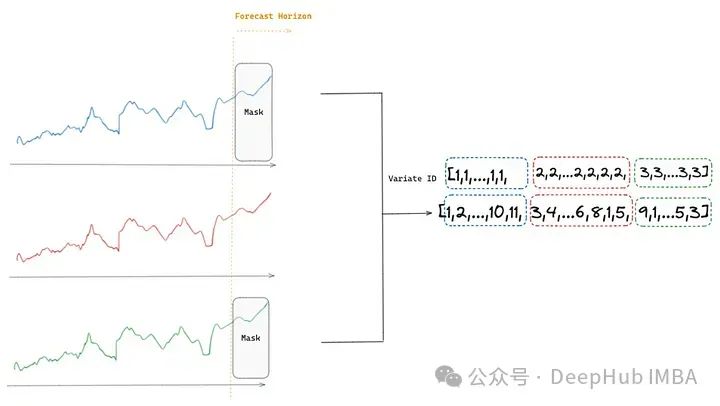
2. 任意变量注意力:允许 Moirai 处理多序列目标值和动态协变量的多变量时间序列场景。它通过将多个时间序列展平成一个值序列,并应用变量编码来区分不同变量。该机制实现了变量顺序的排列等变性和变量索引的排列不变性,确保模型对时间序列动态的理解一致性,并能够处理任意数量的变量及其排列。
3. 混合分布:Moirai 使用混合分布进行概率预测,以适应各种数据类型。它结合了学生 t 分布、负二项分布、对数正态分布和低方差正态分布,以更好地捕捉不同数据特征。
文章还将 Moirai 与 TimeGPT 和 Chronos 进行了比较,并通过澳大利亚旅游访客数量预测的案例研究,对比了 Moirai、Chronos 和 TiDE 的性能。结果显示,Moirai 的性能不及 Chronos,可能存在过拟合训练数据的问题。
怜星夜思:
2、Moirai、Chronos、TimeGPT 等时间序列预测基础模型的出现,预示着时间序列分析领域将迎来怎样的变革?
3、文章中提到 Moirai 在实际案例中的表现不如 Chronos,可能存在过拟合训练数据的问题。如何避免时间序列预测模型的过拟合?
原文内容

来源:DeepHub IMBA本文约5700字,建议阅读10分钟
在本文中,我们将探索用于时间序列预测的 Salesforce 新发布的基础模型 Moirai。
背景
Moirai
-
处理各种数据频率(小时、日、周等);
-
适应任何数量和类型的协变量,无论它们在未来是否已知;
-
使用灵活的分布生成概率预测,可适应多种情况。

-
使注意力机制能够通过观察一组时间序列而不是单个时间步来提取局部语义意义;
-
减少了输入到编码器的标记数量,从而减少了所需的内存,允许向模型提供更长的输入序列;
-
有了更长的序列,模型有更多的信息可供处理,能够提取更有意义的时间关系,可能产生更准确的预测。
年度和季度 → 补丁大小 8
月度 → 补丁大小 8, 16, 32
周和日 → 补丁大小 16, 32
小时 → 补丁大小 32, 64
分钟级 → 补丁大小 32, 64, 128
秒级 → 补丁大小 64, 128

-
旋转位置嵌入(RoPE)[8] 确保通过其编码方式实现排列等变性。它通过在嵌入空间中旋转标记的表征来编码位置信息。旋转角度与序列中每个标记的位置成比例。它在保持任何一对标记之间的相对距离的同时捕获了每个标记的绝对位置。
-
二进制注意力偏差允许模型实现不变性 —— 将变量视为无序的。模型通过根据元素是否属于同一变量(m=n)或不同变量(m≠n)应用不同的注意力偏差(可学习的标量)动态调整其焦点。这使得任意变量注意力机制能够处理任意数量的变量及其排列。

-
学生 t 分布是大多数时间序列的稳健选择,因为它能够处理离群值和具有较重尾部的数据。
-
负二项分布对于严格正的计数数据很有用,因为它不预测负值。
-
对数正态分布有效地预测右偏数据,如经济指标或自然现象。
-
低方差正态分布适用于紧密围绕平均值聚集的数据,适用于高置信度预测。

TimeGPT、Chronos、Moirai 比较

性能对比
%load_ext autoreload %autoreload 2 import torch import pandas as pd import numpy as np import utilsfrom datasets import load_dataset
from gluonts.dataset.pandas import PandasDataset
from huggingface_hub import hf_hub_downloadfrom uni2ts.model.moirai import MoiraiForecast
TIME_COL = “Date”
TARGET = “visits”
DYNAMIC_COV = [‘CPI’, ‘Inflation_Rate’, ‘GDP’]
SEAS_COV=[‘month_1’, ‘month_2’, ‘month_3’, ‘month_4’, ‘month_5’, ‘month_6’, ‘month_7’,‘month_8’, ‘month_9’, ‘month_10’, ‘month_11’, ‘month_12’]
FORECAST_HORIZON = 8 # months
FREQ = “M”
# load data and exogenous features df = pd.DataFrame(load_dataset("zaai-ai/time_series_datasets", data_files={'train': 'data.csv'})['train']).drop(columns=['Unnamed: 0']) df[TIME_COL] = pd.to_datetime(df[TIME_COL])one hot encode month
df[‘month’] = df[TIME_COL].dt.month
df = pd.get_dummies(df, columns=[‘month’], dtype=int)
print(f"Distinct number of time series: {len(df[‘unique_id’].unique())}")
df.head()
# 8 months to test train = df[df[TIME_COL] <= (max(df[TIME_COL])-pd.DateOffset(months=FORECAST_HORIZON))] test = df[df[TIME_COL] > (max(df[TIME_COL])-pd.DateOffset(months=FORECAST_HORIZON))]print(f"Months for training: {len(train[TIME_COL].unique())} from {min(train[TIME_COL]).date()} to {max(train[TIME_COL]).date()}“)
print(f"Months for testing: {len(test[TIME_COL].unique())} from {min(test[TIME_COL]).date()} to {max(test[TIME_COL]).date()}”)
#Months for training: 220 from 1998–01–01 to 2016–04–01
#Months for testing: 8 from 2016–05–01 to 2016–12–01
# create GluonTS dataset from pandas ds = PandasDataset.from_long_dataframe( pd.concat([train, test[["unique_id", TIME_COL]+DYNAMIC_COV+SEAS_COV]]).set_index(TIME_COL), # concatenaation with test dynamic covaraiates item_id="unique_id", feat_dynamic_real=DYNAMIC_COV+SEAS_COV, target=TARGET, freq=FREQ )
# Prepare pre-trained model by downloading model weights from huggingface hub model = MoiraiForecast.load_from_checkpoint( checkpoint_path=hf_hub_download( repo_id="Salesforce/moirai-R-large", filename="model.ckpt" ), prediction_length=FORECAST_HORIZON, context_length=24, patch_size='auto', num_samples=100, target_dim=1, feat_dynamic_real_dim=ds.num_feat_dynamic_real, past_feat_dynamic_real_dim=ds.num_past_feat_dynamic_real, map_location="cuda:0" if torch.cuda.is_available() else "cpu", )predictor = model.create_predictor(batch_size=32)
forecasts = predictor.predict(ds)convert forecast into pandas
forecast_df = utils.moirai_forecast_to_pandas(forecasts, test, FORECAST_HORIZON, TIME_COL)


总结
Unified Training of Universal Time Series Forecasting Transformers
https://arxiv.org/abs/2402.02592
其他引用
[1] Garza, A., & Mergenthaler-Canseco, M. (2023). TimeGPT-1. arXiv.2310.03589
[2] Rasul, K., Ashok, A., Williams, A. R., Ghonia, H., Bhagwatkar, R., Khorasani, A., Darvishi Bayazi, M. J., Adamopoulos, G., Riachi, R., Hassen, N., Biloš, M., Garg, S., Schneider, A., Chapados, N., Drouin, A., Zantedeschi, V., Nevmyvaka, Y., & Rish, I. (2024). Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting. arXiv. 2310.08278
[3] Das, A., Kong, W., Sen, R., & Zhou, Y. (2024). A decoder-only foundation model for time-series forecasting. arXiv. 2310.10688
[4] Ansari, A. F., Stella, L., Turkmen, C., Zhang, X., Mercado, P., Shen, H., Shchur, O., Rangapuram, S. S., Arango, S. P., Kapoor, S., Zschiegner, J., Maddix, D. C., Mahoney, M. W., Torkkola, K., Wilson, A. G., Bohlke-Schneider, M., & Wang, Y. (2024). Chronos: Learning the Language of Time Series. arXiv. 2403.07815
[5] Woo, G., Liu, C., Kumar, A., Xiong, C., Savarese, S., & Sahoo, D. (2024). Unified Training of Universal Time Series Forecasting Transformers. arXiv.2402.02592
[6] Palatucci, M., Pomerleau, D., Hinton, G. E., & Mitchell, T. M. (2009). Zero-shot Learning with Semantic Output Codes. In Y. Bengio, D. Schuurmans, J. Lafferty, C. Williams, & A. Culotta (Eds.), Advances in Neural Information Processing Systems (Vol. 22). Curran Associates, Inc.
[7] Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. arXiv:2211.14730, 2022.
[8] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, Yunfeng Liu. RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864, 2021.
[9] David Salinas, Valentin Flunkert, Jan Gasthaus. DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks. arXiv:1704.04110, 2017.
编辑:王菁
