清华团队研究发现,GPT-4V、谷歌Bard等商用多模态大模型存在安全漏洞,可被对抗攻击误导,引发对模型鲁棒性的担忧。
原文标题:清华团队攻破GPT-4V、谷歌Bard等模型,商用多模态大模型也脆弱?
原文作者:数据派THU
冷月清谈:
清华大学朱军教授团队最新研究揭示了包括GPT-4V、谷歌Bard和Bing Chat等在内的商用多模态大语言模型(MLLMs)在对抗攻击面前的脆弱性。研究团队利用两种攻击方法——图像特征攻击和文本描述攻击,成功误导了这些MLLMs,使其输出错误的图像描述。
图像特征攻击通过扰动图像特征,使模型无法正确识别图像内容。文本描述攻击则直接针对模型的文本生成过程,诱导模型产生错误的描述。
实验结果显示,针对GPT-4V的攻击成功率高达45%,Bard为22%,Bing Chat为26%。此外,研究还发现,对抗攻击可以绕过Bard内置的人脸检测和图像毒性检测等安全机制,进一步凸显了这些模型的安全风险。
该研究警示我们,尽管MLLMs在多模态任务中表现出色,但其安全性和鲁棒性仍需加强。目前,对抗训练等经典防御方法在大规模模型上的应用存在计算成本高昂的挑战,而基于图像预处理的防御方法或许是更可行的方向。未来,如何有效提升MLLMs的鲁棒性,仍是一个值得深入研究的开放问题。
图像特征攻击通过扰动图像特征,使模型无法正确识别图像内容。文本描述攻击则直接针对模型的文本生成过程,诱导模型产生错误的描述。
实验结果显示,针对GPT-4V的攻击成功率高达45%,Bard为22%,Bing Chat为26%。此外,研究还发现,对抗攻击可以绕过Bard内置的人脸检测和图像毒性检测等安全机制,进一步凸显了这些模型的安全风险。
该研究警示我们,尽管MLLMs在多模态任务中表现出色,但其安全性和鲁棒性仍需加强。目前,对抗训练等经典防御方法在大规模模型上的应用存在计算成本高昂的挑战,而基于图像预处理的防御方法或许是更可行的方向。未来,如何有效提升MLLMs的鲁棒性,仍是一个值得深入研究的开放问题。
怜星夜思:
1、除了文中提到的图像特征攻击和文本描述攻击,大家觉得还有什么其他潜在的攻击方式可能会对多模态大模型造成威胁?
2、文章提到对抗训练成本较高,难以应用于大规模模型。除了文中提到的图像预处理防御,大家还有什么其他的防御思路?
3、多模态大模型的安全性问题会对未来的AI应用带来哪些影响?
2、文章提到对抗训练成本较高,难以应用于大规模模型。除了文中提到的图像预处理防御,大家还有什么其他的防御思路?
3、多模态大模型的安全性问题会对未来的AI应用带来哪些影响?
原文内容

来源:机器之心本文约2600字,建议阅读5分钟
为了更好地理解商用 MLLMs 的漏洞,清华朱军教授领衔的人工智能基础理论创新团队围绕商用 MLLM 的对抗鲁棒性展开了研究。
GPT-4 近日开放了视觉模态(GPT-4V)。以 GPT-4V、谷歌 Bard 为代表的多模态大语言模型 (Multimodal Large Language Models, MLLMs) 将文本和视觉等模态相结合,在图像描述、视觉推理等各种多模态任务中展现出了优异的性能。然而,视觉模型长久以来存在对抗鲁棒性差的问题,而引入视觉模态的 MLLMs 在实际应用中仍然存在这一安全风险。最近一些针对开源 MLLMs 的研究已经证明了该漏洞的存在,但更具挑战性的非开源商用 MLLMs 的对抗鲁棒性还少有人探索。
为了更好地理解商用 MLLMs 的漏洞,清华朱军教授领衔的人工智能基础理论创新团队围绕商用 MLLM 的对抗鲁棒性展开了研究。尽管 GPT-4V、谷歌 Bard 等模型开放了多模态接口,但其内部模型结构和训练数据集仍然未知,且配备了复杂的防御机制。尽管如此,研究发现,通过攻击白盒图像编码器或 MLLMs,生成的对抗样本可以诱导黑盒的商用 MLLMs 输出错误的图像描述,针对 GPT-4V 的攻击成功率达到 45%,Bard 的攻击成功率达到 22%,Bing Chat 的攻击成功率达到 26%。同时,团队还发现,通过对抗攻击可以成功绕过 Bard 等模型对于人脸检测和图像毒性检测等防御机制,导致模型出现安全风险。

-
论文链接:
-
https://arxiv.org/abs/2309.11751
-
代码链接:
-
https://github.com/thu-ml/ares/tree/attack_bard

下图展示了针对 Bard 的攻击测试。当输入自然样本图片时,Bard 可以正确描述出图片中的主体(“a panda’s face(一个熊猫的脸)”);当输入对抗样本时,Bard 会将该图片的主体错分类为 “a woman’s face(一个女人的脸)”。

对抗攻击方法
MLLMs 通常使用视觉编码器提取图像特征,然后将图像特征通过对齐后输入大语言模型生成相应的文本描述。因此该研究团队提出了两种对抗攻击 MLLMs 的方法:图像特征攻击、文本描述攻击。图像特征攻击使对抗样本的特征偏离原始图像的特征,因为如果对抗样本可以成功破坏图像的特征表示,则生成的文本将不可避免地受到影响。另一方面,文本描述攻击直接针对整个流程进行攻击,使生成的描述与正确的描述不同。
图像特征攻击:令  表示自然样本,
表示自然样本, 表示替代图像编码器的集合,则图像特征攻击的目标函数可以表示为:
表示替代图像编码器的集合,则图像特征攻击的目标函数可以表示为:

其中,通过最大化对抗样本 x 和自然样本 的图像特征之间的距离进行优化,同时还确保 x 和 之间的  距离小于扰动规模
距离小于扰动规模 。
。
文本描述攻击:令  表示替代 MLLMs 的集合,其中
表示替代 MLLMs 的集合,其中  可以在给定图片 x ,文本提示 p 以及之前预测的词
可以在给定图片 x ,文本提示 p 以及之前预测的词 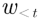 时,预测出下一个词
时,预测出下一个词 的概率分布,表示为
的概率分布,表示为  。因此,文本描述攻击可以表述为最大化预测目标句子
。因此,文本描述攻击可以表述为最大化预测目标句子  的对数似然:
的对数似然:

值得注意的是文本描述攻击是针对给定目标句子的有目标攻击,而不是最小化真实描述的对数似然的无目标攻击,这是因为存在对图像的多个正确描述。
攻击方法:为了解决上述对抗样本的优化问题,该研究团队采用了自研的目前迁移性最好的对抗攻击方法 Common Weakness Attack (CWA)[1]。
数据集:在 NIPS17 数据集 [2] 中随机选取 100 张图片作为自然样本。
替代模型:对于图像特征攻击选用的替代模型为 ViT-B/16、CLIP 和 BLIP-2 的图像编码器;对于文本描述攻击选用 BLIP-2、InstructBLIP 和 MiniGPT-4。
评价指标:测量攻击成功率来评估的鲁棒性。认为只有当图像中的主体被错误地预测时,攻击才成功,其他错误的细节,如幻觉,物体计数,颜色或背景,被认为是不成功的攻击。
下图分别展示了针对 GPT-4V、Bard、Bing Chat 上对抗样本攻击成功的示例。


图 3:攻击 Bard 示例,将大熊猫描述为女人的脸


下表中展示了上述方法针对不同商用模型的攻击成功率。可以看到,Bing Chat 存在很大的几率拒绝回答带有噪声的图像。整体上谷歌 Bard 的鲁棒性最好。

针对 Bard 防御机制的攻击
在该研究团队对 Bard 的评估中,发现 Bard 部署了(至少)两种防御机制,包括人脸检测和毒性检测。Bard 将直接拒绝包含人脸或有毒内容的图像(例如,暴力、血腥或色情图像)。这些防御机制被部署以保护人类隐私并避免滥用。然而,对抗攻击下的防御鲁棒性是未知的。因此,该研究团队针对这两种防御机制进行了评估。
人脸检测器攻击:为了使 Bard 的人脸检测器无法识别到对抗样本中的人脸并输出带有人脸信息的预测,研究者针对白盒人脸检测器进行攻击,降低模型对人脸图像的识别置信度。攻击方法仍然采用 CWA 方法,在 LFW 和 FFHQ 等数据集上进行实验。
下图为人脸对抗样本在 Bard 上攻击成功的示例。总体上对 Bard 人脸检测模块的对抗攻击成功率达到了 38%,即有 38% 的人脸图片无法被 Bard 检测到,并输出对应的描述。

毒性检测器攻击:为了防止提供对有毒图像的描述,Bard 采用毒性检测器来过滤掉此类图像。为了攻击它,需要选择某些白盒毒性检测器作为替代模型。该研究团队发现一些现有的毒性检测器是预训练视觉模型 CLIP 上进行微调得到的。针对这些替代模型的攻击,只需要扰动这些预训练模型的特征即可。因此,可以采用与图像特征攻击完全相同的目标函数。并使用相同的攻击方法 CWA。
该研究团队手动收集了一组 100 张含有暴力、血腥或色情内容的有毒图像,对 Bard 的毒性探测器的攻击成功率达到 36%。如下图所示,毒性检测器不能识别具有对抗性噪声的毒性图像。因此,Bard 为这些图像提供了不适当的描述。该实验强调了恶意攻击者利用 Bard 生成有害内容的不合适描述的可能性。

图 7:攻击 Bard 的毒性检测模型
讨论与总结
上述研究表明,通过使用最先进的基于迁移的攻击来优化图像特征或文本描述的目标,目前主流的商用多模态大模型也会被成功的欺骗误导。作为大型基础模型(例如,ChatGPT、Bard)已经越来越多地被人类用于各种任务,它们的安全问题成为公众关注的一个大问题。对抗攻击技术还可以破坏 LLM 的安全与对齐,带来更加严重的安全性问题。
此外,为保证大模型的安全性,需要针对性进行防御。经典的对抗训练方法由于计算成本较高,应用于大规模预训练模型较为困难。而基于图像预处理的防御更适合于大模型,可以通过即插即用的方式使用。一些最近的工作利用了先进的生成模型(例如,扩散模型)以净化对抗扰动(例如,似然最大化 [3]),这可以作为防御对抗样本的有效策略,但是总体来说如何提升大模型的鲁棒性和抗干扰能力,仍然是一个开放的问题,尚有很大的探索和提升空间。
相关文献:
[1] Huanran Chen, Yichi Zhang, Yinpeng Dong, and Jun Zhu. Rethinking model ensemble in transfer-based adversarial attacks. arXiv preprint arXiv:2303.09105, 2023.
[2] https://www.kaggle.com/competitions/nips-2017-non-targeted-adversarial-attack
[3] Huanran Chen, Yinpeng Dong, Zhengyi Wang, Xiao Yang, Chengqi Duan, Hang Su, and Jun Zhu. Robust classification via a single diffusion model. arXiv preprint arXiv:2305.15241, 2023.
编辑:文婧
