R语言GLM模型实战,涵盖泊松、伽马、逻辑和Beta回归,附带多个案例分析和代码实现。
原文标题:R语言非线性回归和广义线性模型:泊松、伽马、逻辑回归、Beta回归分析机动车事故、小鼠感染、蛤蜊数据、补剂钠摄入数据|数据分享
原文作者:数据派THU
冷月清谈:
首先,文章以火车与机动车碰撞数据为例,讲解了泊松回归的应用。数据显示,碰撞次数的方差随预测变量变化,且服从泊松分布。文章对比了线性模型和泊松回归模型的拟合效果,并使用分位数残差评估了泊松回归模型的假设。
其次,文章以蛤蜊数据为例,探讨了Gamma回归的应用。数据中蛤蜊的无灰干质量与月份和长度呈非线性关系。文章使用Gamma回归模型拟合数据,并通过残差分析评估了模型的拟合效果。此外,文章还比较了Gamma回归和正态误差模型的适用性。
接下来,文章以小鼠感染隐孢子虫的案例讲解了逻辑回归的应用。由于感染率介于0和1之间,文章使用二项逻辑回归模型进行拟合。文章介绍了二项分布的特点,并解释了logit链接函数的应用。
最后,文章以服用不同补充剂时锻炼后钠摄入比例的数据为例,介绍了Beta回归的应用。由于钠摄入比例也介于0和1之间,文章使用Beta回归模型进行拟合,并进行了模型评估和结果解读。
怜星夜思:
2、文章用蛤蜊数据演示了Gamma回归,并提到Gamma回归的方差随均值的平方成比例地扩展。这种特性在实际应用中有什么意义?
3、文章最后提到的Beta回归,它和逻辑回归都有处理0-1之间数据的特点,那么在实际应用中该如何选择使用哪种模型?
原文内容

本文约2500字,建议阅读5分钟本文为你介绍如何使用广义线性模型(GLM)。
全文链接:https://tecdat.cn/?p=33781
我们使用广义线性模型(Generalized Linear Models,简称GLM)来研究客户的非正态数据,并探索非线性关系。
相关视频
GLM是一种灵活的统计模型,适用于各种数据类型和分布,包括二项分布、泊松分布和负二项分布等非正态分布。通过GLM,我们可以对非正态数据进行建模和预测,并且能够处理计数数据,如客户购买数量、网站点击次数等。GLM还允许引入自变量的非线性效应,从而更好地拟合与响应变量之间的复杂关系。这使得GLM成为处理非正态数据和非线性关系的强大工具。
泊松回归和伽马回归 - 探索联系
如果我们查看火车与机动车碰撞数据,我们会发现一个有趣的模式。
library(readr) ......train <- read_csv(“s_agresti.csv”)
train_plot <- ggplot(train,
…

仅仅通过观察,我们就可以看出方差随预测变量而变化。此外,我们处理的是计数数据,它具有自己的分布,即泊松分布。然而,如果我们坚持使用lm进行分析会怎样呢?
train_lm <-......odel(train_lm)

预测值和观测值之间不匹配。部分原因是这里的响应变量在残差中不是正态分布的,而是泊松分布,因为它是计数数据。
泊松回归
具有泊松误差的广义线性模型通常具有对数链接,尽管也可以具有恒等链接。例如,
pois_tib <- tibble(x = rep(0:40,2),
......
geom_col(position = position_dodge())

上面显示了两个泊松分布,一个均值为5,另一个均值为20。请注意它们的方差如何变化。
对数链接(例如ŷ=ea+bx̂=eβ+αx)是一个自然的拟合方法,因为它不能得到小于0的值。因此,在这种情况下,我们可以这样做:
train_glm <- glm(collisions ~ km_trtravel,
......
然后,我们可以重新评估模型的假设,包括过分离。请注意,下面的QQ图并没有什么实际意义,因为这不是正态分布。
check_model(train_glm)

那么...残差怎么办呢?鉴于残差不是正态分布的,使用qqnorm图几乎没有意义。拟合残差关系仍然可能看起来很奇怪。
使用广义线性模型的分位数残差
评估广义线性模型(以及许多其他模型形式)的一种方法是查看其分位数残差。因此,首先让我们使用DHARMa生成一些模拟残差。
res <- simulateResiduals(train_glm)
我们可以绘制这些图表,并进行非参数拟合检验。
plotQQunif(res)

很好,拟合效果不错。忽略异常值测试,因为在更详细的观察中我们发现没有异常值。
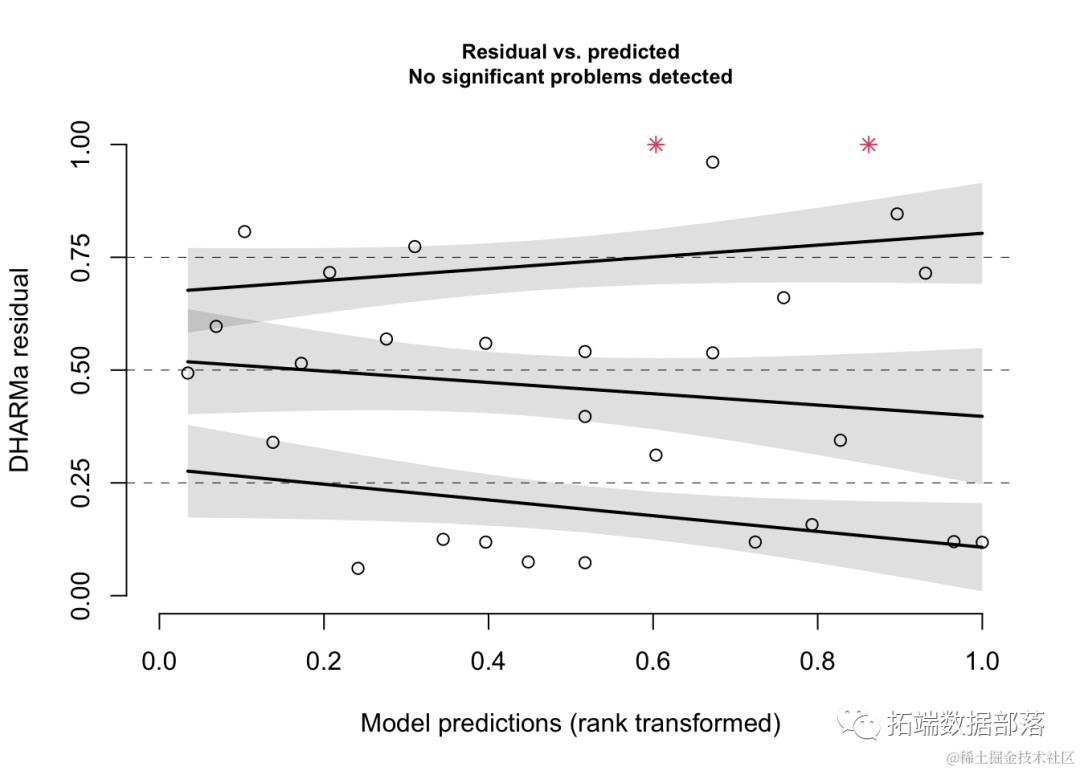
我们还可以查看预测与量化残差图。
plotResiduals(res)
check_overdispersion(train_glm) |> plot()
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'

查看glm结果
让我们来看看模型结果。
summary(train_glm)

注意,在这里我们看到了标准的glm输出,我们可以像处理任何对数变换一样解释系数。我们还有一个离散参数,描述了均值和方差之间的关系。对于泊松分布,它的值为1。
最后,我们可以绘图。
train_plot +
......"log")))
![]()

Gamma回归
然而,我们的数据通常不是离散的。考虑蛤蜊数据。
clams <- read_delim("ams.txt", delim = "\t") %>%
mutate(MONTH = factor(MONTH))
AFD(无灰干质量)与月份和长度有什么关系?显然这里存在非线性关系。
clam_plot <- ggplot(clams, ......
clam_plot

现在,看起来我们应该用对数变换的模型进行拟合,但是…
clam_lm <- lm(log(......

显然存在明显的问题。即使对AFD取对数后的qq图也不好,残差拟合图也不好。Gamma glm采用其逆函数作为其规范连接,但它们通常也可以使用对数连接。
clam_gamma <- glm(AFD ~ ...... data = clams) check_model(clam_gamma)

还有
clam_res <- simulateR......res)

ploals(clam_res)

好的,也许不是很好。但这主要是由于高值的稀疏性导致的,所以没关系。
我们可以使用predict进行绘图,在这里分别绘制每个月的图。
clam_plot +......
facet_wrap(~MONTH)
我们还可以查看其他属性。

summary(clam_gamma)

我们可以重新参数化伽马分布,使得均值=形状/速率。在这种情况下,我们使用该均值和形状参数化伽马分布。离散参数是1/形状。
但是,为了更容易理解,伽马的方差随均值的平方成比例地扩展。离散参数越大,方差扩展得越快。
最后,我们可以使用纳吉尔克计的伪R2来计算R2。
# fit
r2(clam_gamma)

这是正态的吗?
你可能会问为什么这里使用伽马分布而不是正态分布?我们可以用正态误差和对数链接进行glm拟合。
clam_glm_norm <- glm(AFD ......
data = clams)
一种判断的方法是寻找过离散。
norm_res <- simulateRe......orm_res)

plotuals(norm_res)
我们可以看到QQ图很好。而且predobs也不糟糕(特别是与上面相比)。这是一些很好的证据,表明这里可能只需要正态误差和对数链接。
逻辑回归
让我们来看看我们的小鼠感染隐孢子虫的例子。请注意,数据被限制在0和1之间。
mouse <- read_csv...... Porportion)) + geom_point()
mouse_plot

这是因为虽然N是每个样本的总小鼠数量,但是我们不能有超过N的感染!实际上,每只老鼠就像一次抛硬币。它是否被感染了。
二项分布
二项分布有两个参数,成功的概率和硬币投掷的次数。得到的分布始终介于0和1之间。考虑使用不同概率进行15次硬币投掷的情况。
bin_tibble <- tibble(outcome = rep(0:15, 2),......
geom_col(position = position_dodge())

我们也可以将x轴的范围调整为0到1,来表示比例。
或者,考虑相同的概率,但是不同次数的硬币投掷。
bin_tibble <- tibble(outcome = rep(0:15, 2),......
geom_col(position = position_dodge())

你可以看到两个参数都会影响分布的形状。
二项式逻辑回归
在二项逻辑回归中,我们主要是估计获得正面的概率。然后我们以权重的形式提供(而不是估计)试验次数。这里使用的典型链接函数是logit函数,因为它描述了一个在0和1之间饱和的逻辑函数。
在R中,我们可以使用两种形式来参数化二项逻辑回归 - 这两种形式是等价的,因为它们将结果扩展为成功次数和总试验次数。
mouse_glm_cbind <- glm(cbind(Y,......
data = mouse)
第二种方式使用权重来表示试验次数。
mouse_glm <- glm(Porport......
data = mouse)
这两个模型是相同的。
从这一点开始,工作流程与以往一样 - 假设检验、分析和可视化。
checl(mouse_glm)

binduals(mouse_glm, ......

res_bin <- sim......

plotRes_bin)

summary(moglm)

r2(mouse_glm)

注意,离散参数为1,就像泊松分布一样。
ggplot(mouse,
......
method.args = list(family = binomial))

Beta回归
最后,我们经常会遇到受限数据,但这些数据不是从二项式分布中抽取的 - 也就是说,并不存在独立的“硬币翻转”。
考虑以下关于服用不同补充剂时锻炼后钠摄入比例的分析,2300是推荐摄入量,所以我们将其标准化为这个值。
sodium <- read_csv("laake.csv")
ggplot(sodium,
......
geom_boxplot()

现在,让我们使用Beta回归来观察这个结果。
sodium_beta <- beta......
data = sodium
soditmb <- glmmTMB(Porport......
data = sodium)
chec......a_tmb)

plotQQunif(sodium_beta_tmb)

然后我们可以继续进行所有我们通常的测试和可视化。例如 -
emmeans(sodium_b......
confint(adjust = "none")

如果我们有一个连续的协变量,我们可以获得拟合值和误差,并将它们放入模型中。
