用宝可梦数据集可视化比较了四种SVM核函数及参数的影响,详解线性、RBF、多项式和Sigmoid核函数的特性与调参技巧。
原文标题:4种SVM主要核函数及相关参数的比较
原文作者:数据派THU
冷月清谈:
本文使用 Scikit-learn 库和宝可梦数据集,通过数据可视化解释和比较了四种核函数(线性、径向基函数 (RBF)、多项式和 Sigmoid)以及不同参数设置的影响。
首先对宝可梦数据集进行了探索性数据分析 (EDA),包括数据预处理、标准化和降维。然后,针对每个核函数,通过调整正则化参数 (C)、核系数 (γ) 和独立项 (coef0),绘制了 3D 散点图和预测概率等高线图。
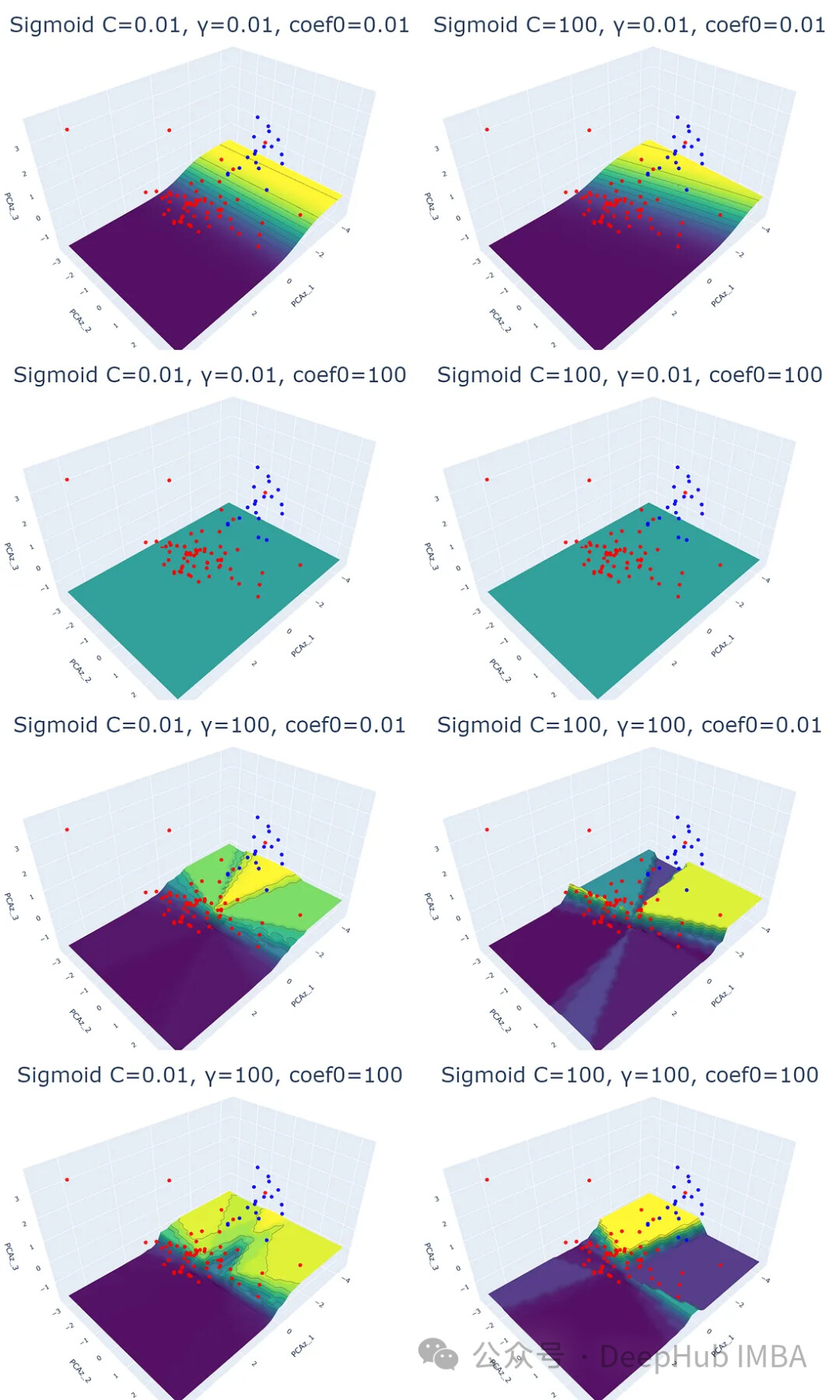
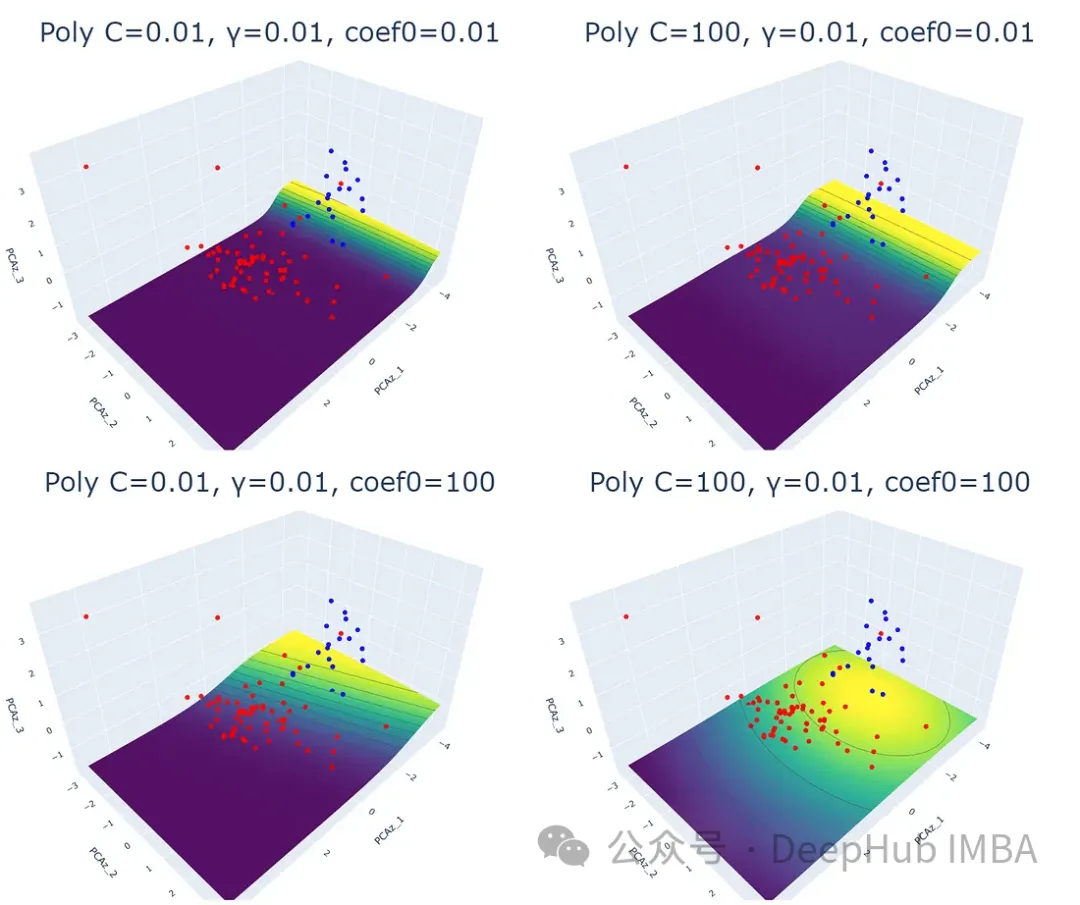
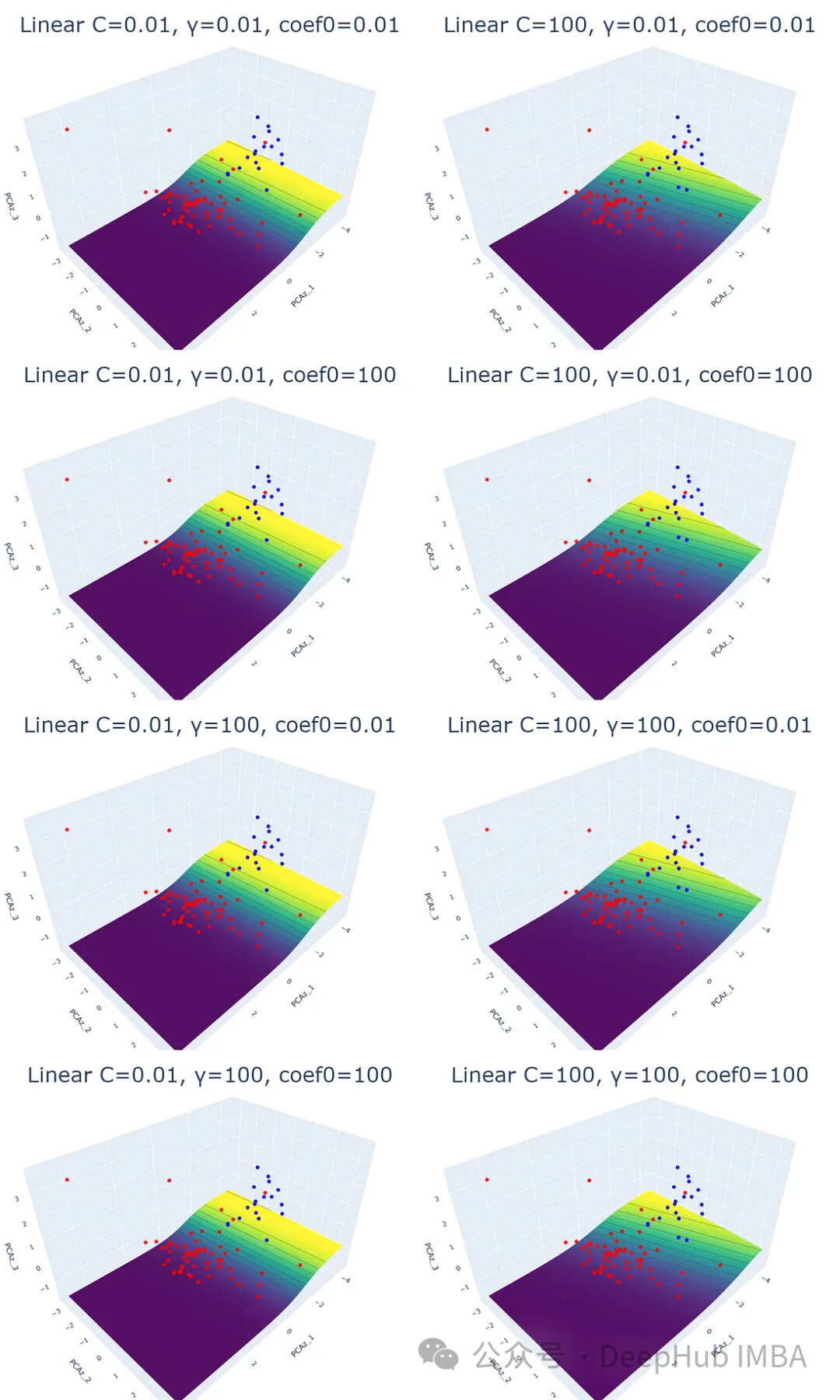
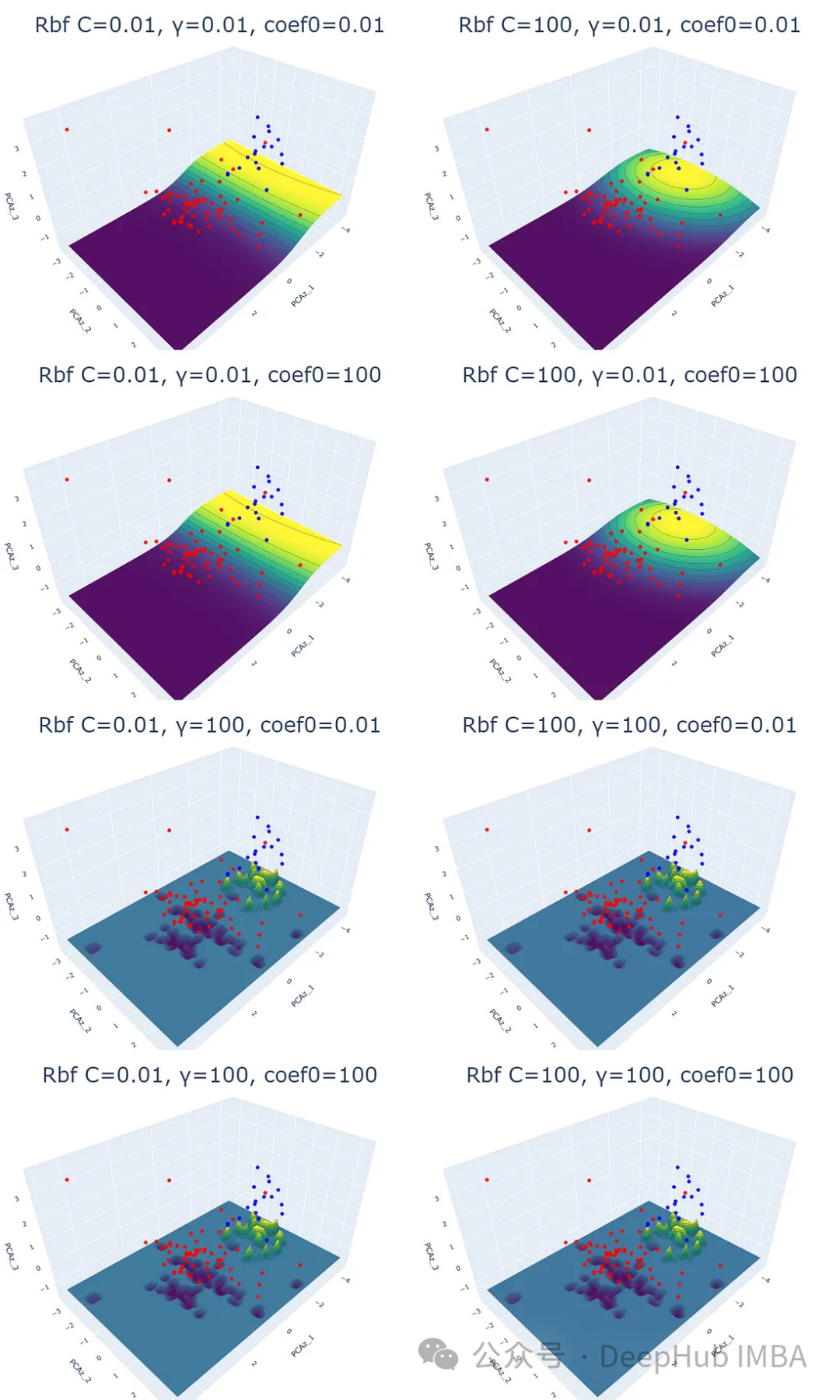
实验结果表明,线性核函数仅受正则化参数 C 的影响,C 值越大,超平面的裕度越小。RBF 核函数受 C 和 γ 的影响,γ 值越大,靠近超平面的数据点的影响越大。多项式核函数受 C、γ 和 coef0 的影响,coef0 值越高,预测概率等高线越弯曲。Sigmoid 核函数的结果较为复杂,难以解释,参数变化对结果的影响也缺乏规律性。
总而言之,选择合适的核函数和参数对 SVM 的性能至关重要,需要根据具体数据集进行调整。
怜星夜思:
2、除了文中提到的四种核函数,还有其他常用的核函数吗?它们各自适用于哪些场景?
3、文章中使用宝可梦数据集进行实验,如果换成其他数据集,比如图像数据或文本数据,结果会有哪些不同?
原文内容

来源:DeepHub IMBA本文约3500字,建议阅读8分钟
本文将用数据可视化的方法解释4种支持向量机核函数和参数的区别。

导入数据和库
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as snsdf = pd.read_csv(‘pokemons.csv’, index_col=0)
df.reset_index(drop=True, inplace=True)
df = df[df[‘rank’].isin([‘baby’, ‘legendary’])]
df.reset_index(drop=True, inplace=True)
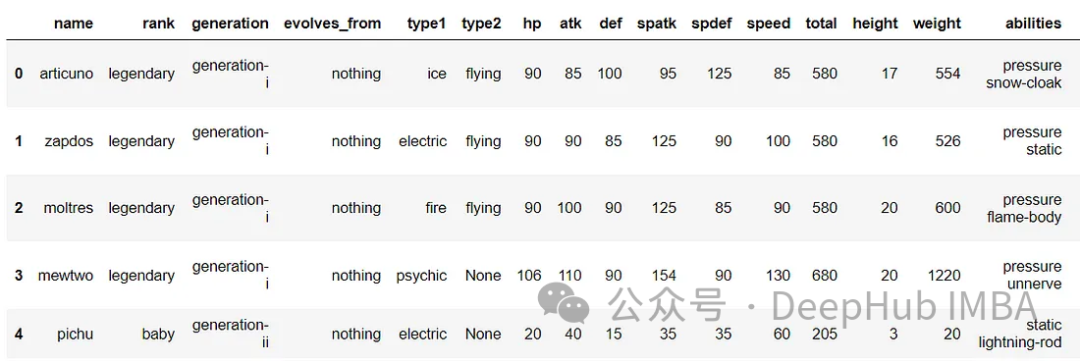
df.head()
EDA
select_col = ['hp','atk', 'def', 'spatk', 'spdef', 'speed', 'height']
df_s = df[select_col]
df_s.info()
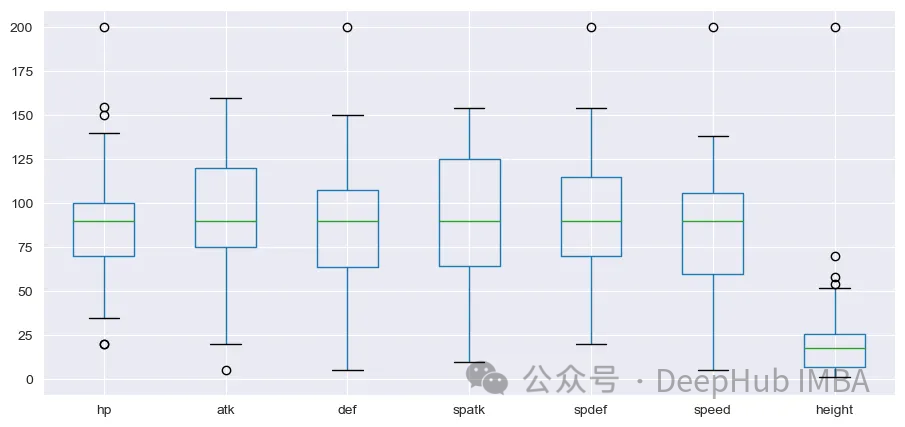
幸运的是,没有空值。接下来,让我们绘制Box和Whisker图,以查看这些变量的分布。
sns.set_style('darkgrid') df_s.iloc[:,].boxplot(figsize=(11,5))
plt.show()
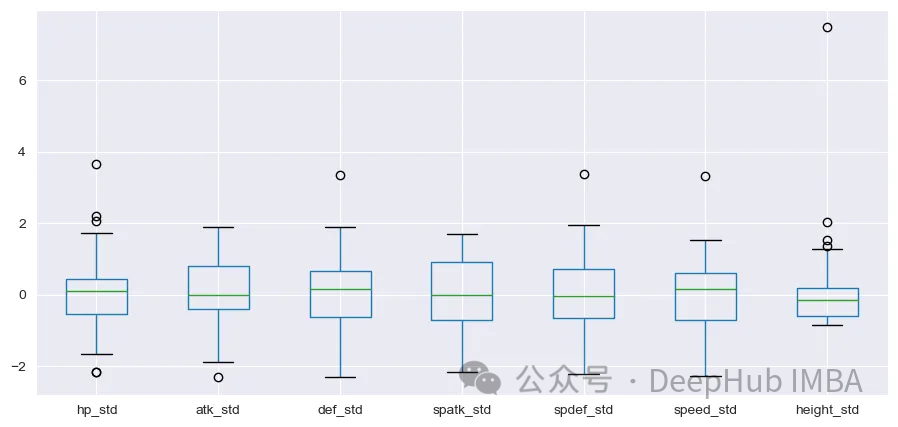
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() array_s = scaler.fit_transform(df_s)
df_scal = pd.DataFrame(array_s, columns=[i+‘_std’ for i in select_col])
df_scal.boxplot(figsize=(11,5))
plt.show()
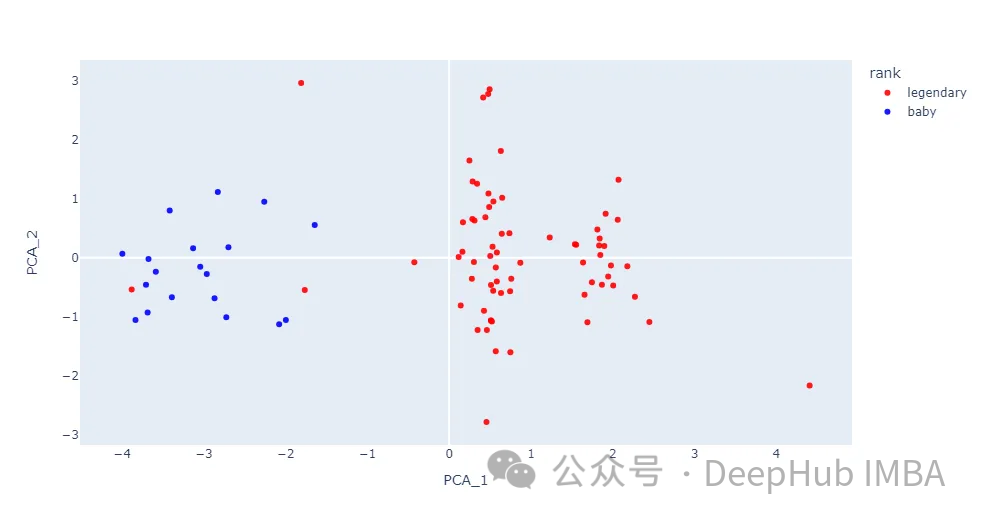
from sklearn.decomposition import PCA import plotly.express as px#encoding
dict_y = {‘baby’:1, ‘legendary’:2}
df[‘s_code’] = [dict_y.get(i) for i in df[‘rank’]]
df.head()pca = PCA(n_components=2)
pca_result = pca.fit_transform(array_s)
df_pca = pd.DataFrame(pca_result, columns=[‘PCA_1’,‘PCA_2’])df = pd.concat([df, df_pca], axis=1)
fig = px.scatter(df, x=‘PCA_1’, y=‘PCA_2’, hover_name=‘name’,
color=‘rank’, opacity=0.9,
color_discrete_sequence=[‘red’, ‘blue’])
fig.update_xaxes(showgrid=False)
fig.update_yaxes(showgrid=False)
fig.show()

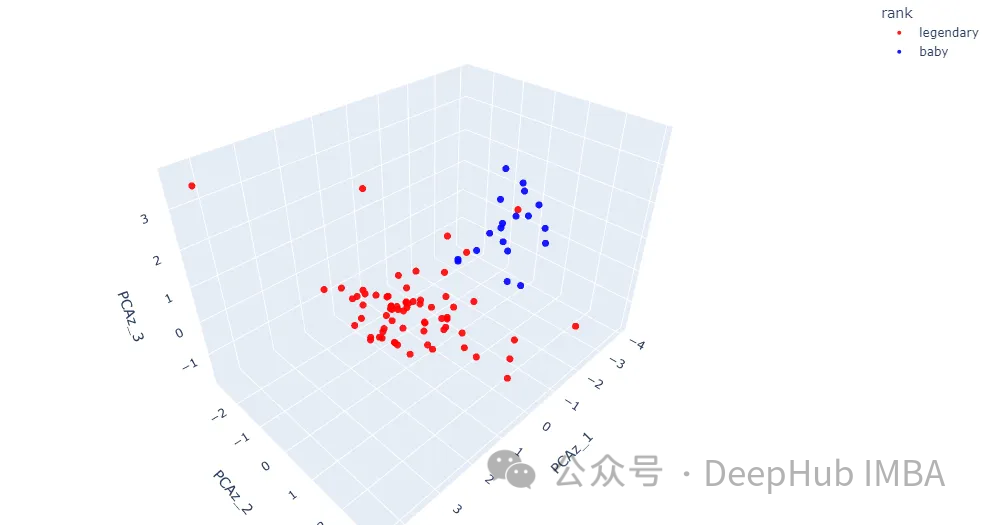
pcaz = PCA(n_components=3) pcaz_result = pcaz.fit_transform(array_s) df_pcaz = pd.DataFrame(pcaz_result, columns=['PCAz_1', 'PCAz_2', 'PCAz_3'])df = pd.concat([df, df_pcaz], axis=1)
fig = px.scatter_3d(df, x=‘PCAz_1’, y=‘PCAz_2’, z=‘PCAz_3’, hover_name=‘name’,
color=‘rank’, opacity=0.9,
color_discrete_sequence=[‘red’, ‘blue’])
fig.update_traces(marker=dict(size=4))
fig.update_layout(margin=dict(l=0, r=0, t=0, b=0))
fig.show()
核方法
Linear Poly RBF (Radial Basis Function) Sigmoid Precomputed
from sklearn import svm import plotly.graph_objects as goy = df[‘s_code’] # y values
h = 0.2 # step in meshgrid
x_min, x_max = df_pca.iloc[:, 0].min(), df_pca.iloc[:, 0].max()
y_min, y_max = df_pca.iloc[:, 1].min(), df_pca.iloc[:, 1].max()
xx, yy = np.meshgrid(np.arange(x_min-0.5, x_max+0.5, h), #create meshgrid
np.arange(y_min-0.5, y_max+0.5, h))def plot_svm(kernel, df_input, y, C, gamma, coef):
svc_model = svm.SVC(kernel=kernel, C=C, gamma=gamma, coef0=coef,
random_state=11, probability=True).fit(df_input, y)Z = svc_model.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 0]
Z = Z.reshape(xx.shape)fig = px.scatter_3d(df, x=‘PCAz_1’, y=‘PCAz_2’, z=‘PCAz_3’, #3D Scatter plot
hover_name=‘name’,
color=‘rank’, opacity=0.9,
color_discrete_sequence=[‘red’, ‘blue’])fig.update_traces(marker=dict(size=4))
fig.add_traces(go.Surface(x=xx, y=yy, # prediction probability contour plot
z=Z+round(df.PCAz_3.min(),3), # adjust the contour plot position
name=‘SVM Prediction’,
colorscale=‘viridis’, showscale=False,
contours = {“z”: {“show”: True, “start”: x_min, “end”: x_max,
“size”: 0.1}}))
title = kernel.capitalize() + ’ C=’ + str(i) + ‘, γ=’ + str(j) + ‘, coef0=’ + str(coef)
fig.update_layout(margin=dict(l=0, r=0, t=0, b=0), showlegend=False,
title={‘text’: title,
‘font’:dict(size=39),
‘y’:0.95,‘x’:0.5,‘xanchor’: ‘center’,‘yanchor’: ‘top’})
return fig.show()
from itertools import product C_list = [0.01, 100] gamma_list = [0.01, 100] coef_list = [0.01, 100] param = [(r) for r in product(C_list, gamma_list, coef_list)]print(param)
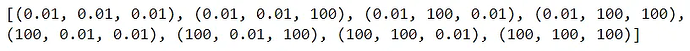
for i,j,k in param:
plot_svm('linear', df_pca, y, i, j, k)
for i,j,k in param: plot_svm('rbf', df_pca, y, i, j, k)
for i,j,k in param: plot_svm('poly', df_pca, y, i, j, k)
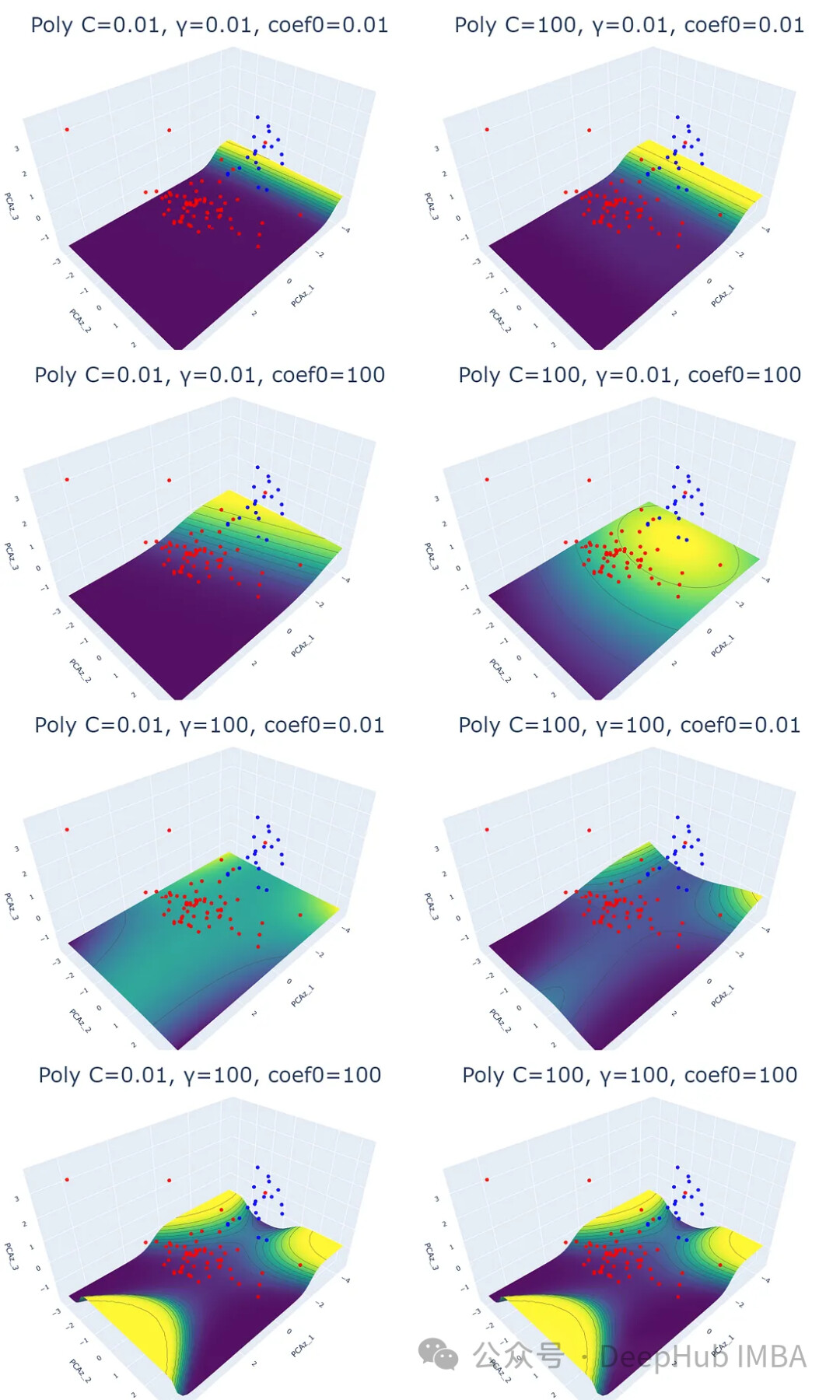
for i,j,k in param:
plot_svm('sigmoid', df_pca, y, i, j, k)