使用PyTorch构建VLM模型完全指南,深入解析核心组件、实现细节及训练技巧。
原文标题:使用Pytorch构建视觉语言模型(VLM)
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、除了文中提到的方法,还有哪些方法可以将图像特征投影到文本嵌入空间?它们各自有什么优缺点?
3、文章中提到了指令微调,能否详细解释一下指令微调的原理和作用?如何进行指令微调?
原文内容
来源:Deephub IMBA
本文约2200字,建议阅读5分钟
本文介绍了VLM的核心组件和实现细节,可以让你全面掌握这项前沿技术。

总体架构
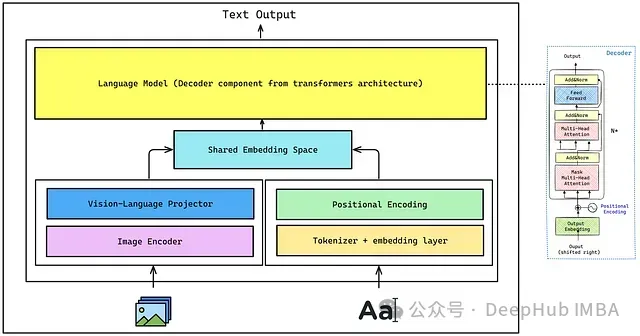
-
图像编码器(Image Encoder):用于从图像中提取视觉特征。本文将从 CLIP 中使用的原始视觉 Transformer。
-
视觉-语言投影器(Vision-Language Projector):由于图像嵌入的形状与解码器使用的文本嵌入不同,所以需要对图像编码器提取的图像特征进行投影,匹配文本嵌入空间,使图像特征成为解码器的视觉标记(visual tokens)。这可以通过单层或多层感知机(MLP)实现,本文将使用 MLP。
-
分词器和嵌入层(Tokenizer + Embedding Layer):分词器将输入文本转换为一系列标记 ID,这些标记经过嵌入层,每个标记 ID 被映射为一个密集向量。
-
位置编码(Positional Encoding):帮助模型理解标记之间的序列关系,对于理解上下文至关重要。
-
共享嵌入空间(Shared Embedding Space):将文本嵌入与来自位置编码的嵌入进行拼接(concatenate),然后传递给解码器。
-
解码器(Decoder-only Language Model):负责最终的文本生成。
-
通过编码器提取图像特征(图像嵌入)。
-
将这些嵌入投影以匹配文本的维度。
-
将投影后的特征与文本嵌入拼接。
-
将组合的表示输入解码器生成文本。
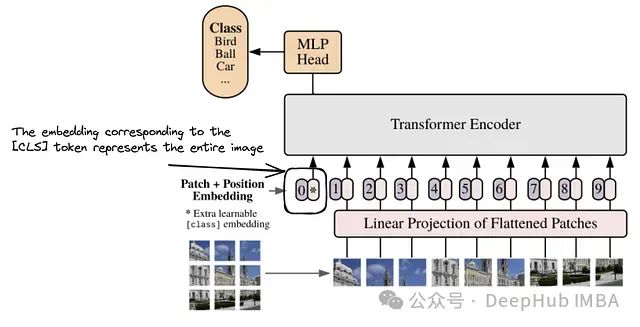
深度解析:图像编码器的实现
图像编码器:视觉 Transformer
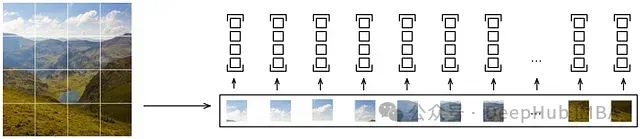
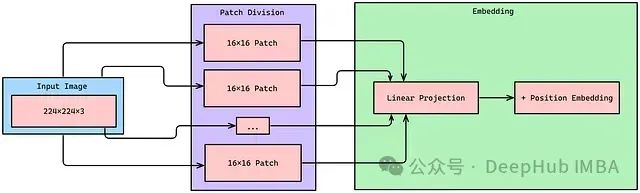
class PatchEmbeddings(nn.Module): def __init__(self, img_size=96, patch_size=16, hidden_dim=512): super().__init__() self.img_size = img_size self.patch_size = patch_size self.num_patches = (img_size // patch_size) ** 2无重叠卷积用于提取小块
self.conv = nn.Conv2d(
in_channels=3,
out_channels=hidden_dim,
kernel_size=patch_size,
stride=patch_size
)使用 Xavier/Glorot 初始化权重
nn.init.xavier_uniform_(self.conv.weight)
if self.conv.bias is not None:
nn.init.zeros_(self.conv.bias)
def forward(self, X):
“”"
参数:
X: 输入张量,形状为 [B, 3, H, W]
返回:
小块嵌入,形状为 [B, num_patches, hidden_dim]
“”"
if X.size(2) != self.img_size or X.size(3) != self.img_size:
raise ValueError(f"输入图像尺寸必须为 {self.img_size}x{self.img_size}")
X = self.conv(X) # [B, hidden_dim, H/patch_size, W/patch_size]
X = X.flatten(2) # [B, hidden_dim, num_patches]
X = X.transpose(1, 2) # [B, num_patches, hidden_dim]
return X
注意力机制
class Head(nn.Module): def __init__(self, n_embd, head_size, dropout=0.1, is_decoder=False): super().__init__() self.key = nn.Linear(n_embd, head_size, bias=False) self.query = nn.Linear(n_embd, head_size, bias=False) self.value = nn.Linear(n_embd, head_size, bias=False) self.dropout = nn.Dropout(dropout) self.is_decoder = is_decoderdef forward(self, x):
B, T, C = x.shape
k = self.key(x)
q = self.query(x)
v = self.value(x)wei = q @ k.transpose(-2, -1) * (C ** -0.5)
if self.is_decoder:
tril = torch.tril(torch.ones(T, T, dtype=torch.bool, device=x.device))
wei = wei.masked_fill(tril == 0, float(‘-inf’))
wei = F.softmax(wei, dim=-1)
wei = self.dropout(wei)
out = wei @ v
return out
视觉-语言投影器
class MultiModalProjector(nn.Module): def __init__(self, n_embd, image_embed_dim, dropout=0.1): super().__init__() self.net = nn.Sequential( nn.Linear(image_embed_dim, 4 * image_embed_dim), nn.GELU(), nn.Linear(4 * image_embed_dim, n_embd), nn.Dropout(dropout) )
def forward(self, x):
return self.net(x)
综合实现
class VisionLanguageModel(nn.Module): def __init__(self, n_embd, image_embed_dim, vocab_size, n_layer, img_size, patch_size, num_heads, num_blks, emb_dropout, blk_dropout): super().__init__() num_hiddens = image_embed_dim assert num_hiddens % num_heads == 0self.vision_encoder = ViT(
img_size, patch_size, num_hiddens, num_heads,
num_blks, emb_dropout, blk_dropout
)self.decoder = DecoderLanguageModel(
n_embd, image_embed_dim, vocab_size, num_heads,
n_layer, use_images=True
)def forward(self, img_array, idx, targets=None):
image_embeds = self.vision_encoder(img_array)if image_embeds.nelement() == 0 or image_embeds.shape[1] == 0:
raise ValueError(“ViT 模型输出为空张量”)
if targets is not None:
logits, loss = self.decoder(idx, image_embeds, targets)
return logits, loss
else:
logits = self.decoder(idx, image_embeds)
return logits
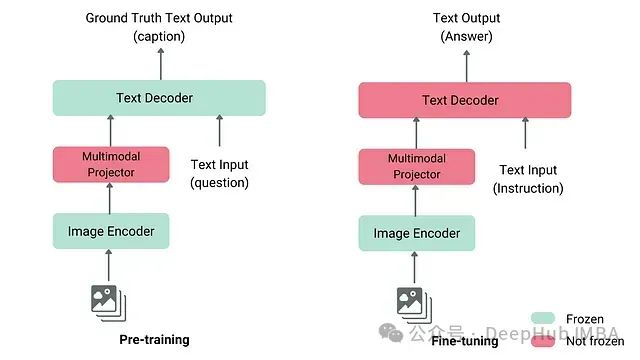
训练及注意事项
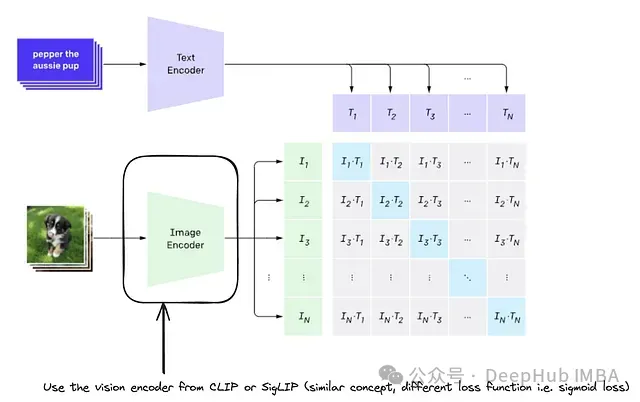
-
视觉编码器:来自 CLIP 或 SigLIP
-
语言解码器:来自 Llama 或 GPT 等模型
-
投影器模块:初始阶段仅训练此模块
-
阶段 1:在冻结的编码器和解码器下预训练,仅更新投影器
-
阶段 2:微调投影器和解码器以适应特定任务
-
可选阶段 3:通过指令微调提升任务性能
-
大规模的图像-文本对用于预训练
-
任务特定的数据用于微调
-
高质量的指令数据用于指令微调