MISATO数据集结合量子特征与分子动力学,推动精确药物发现。
原文标题:结合量子特征、2万个分子动力学模拟,新蛋白-配体复合物ML数据集,登Nature子刊
原文作者:数据派THU
冷月清谈:
德国亥姆霍兹慕尼黑研究中心与慕尼黑工业大学的研究团队提出了MISATO数据集,结合量子力学特性和2万个蛋白质-配体复合物的分子动力学模拟,为药物发现提供了新的数据基础。该数据集旨在改善机器学习模型的训练效果,尤其在结构导向的药物发现领域。团队展示了该数据集在提高准确性方面的潜力,并通过提供示例AI基线模型,帮助研究人员更好地理解生物分子与配体的相互作用。虽然当前AI在药物发现中的应用仍面临诸多挑战,但MISATO的发布标志着向更高效、精确的药物研发迈出了重要一步。
怜星夜思:
1、MISATO数据集的出现会如何影响药物发现的速度和效率?
2、目前药物发现中AI的应用存在哪些局限性?
3、如何评价大型语言模型在科学研究中的应用前景?
2、目前药物发现中AI的应用存在哪些局限性?
3、如何评价大型语言模型在科学研究中的应用前景?
原文内容

来源:专知本文约1200字,建议阅读5分钟
该团队提供了机器学习(ML)基线模型的示例,证明通过使用该数据集可以提高准确性。

大型语言模型极大地增强了科学家理解生物学和化学的能力,但基于结构的药物发现、量子化学和结构生物学的可靠方法仍然很少。大型语言模型迫切需要精确的生物分子-配体相互作用数据集。
为了解决这个问题,德国亥姆霍兹慕尼黑研究中心结构生物学所和慕尼黑工业大学的研究人员,提出了 MISATO。这是一个数据集,它结合了小分子的量子力学(QM)特性,还有约 20,000 个实验蛋白质-配体复合物的相关分子动力学(MD)模拟,以及对实验数据的广泛验证。
从现有的实验结构出发,研究人员利用半经验量子力学系统地完善了这些结构。其中包括大量蛋白质-配体复合物在纯水中的分子动力学痕迹,累积时间超过 170μs。
该团队提供了机器学习(ML)基线模型的示例,证明通过使用该数据集可以提高准确性。为机器学习专家提供了一个简单的切入点,以实现下一代药物发现人工智能模型。
该研究以「MISATO: machine learning dataset of protein–ligand complexes for structure-based drug discovery」为题,于 2024 年 5 月 10 日发布在《Nature Computational Science》。

AI 预测技术近年在科学领域引发革命,如 AlphaFold 能精准预测蛋白质结构。尽管结构导向的药物发现仍是巨大挑战,AI 在此领域的应用尚浅。当前方法面临精度、计算成本及实验依赖度等难题,且多集中于简单解决方案与一维数据处理,忽视了三维蛋白-配体复合体的复杂性。
虽然存在多种数据库,但因数据量限制和热力学信息缺失,尚未有AI模型能显著推进药物发现,如同 AlphaFold 在蛋白结构预测领域的成就。此外,AI 模型还受限于忽视动态性、化学复杂性等问题,影响了其在生物分子分析和量子化学上的潜力。
在这里,德国亥姆霍兹慕尼黑研究中心结构生物学所和慕尼黑工业大学的研究人员,提出了一个基于实验蛋白质-配体结构的蛋白质-配体结构数据库,MISATO(Molecular Interactions Are Structurally Optimized)。
研究人员表明,该数据库有助于更好地训练与药物发现相关领域及其他领域的模型。这包括量子化学、普通结构生物学和生物信息学。
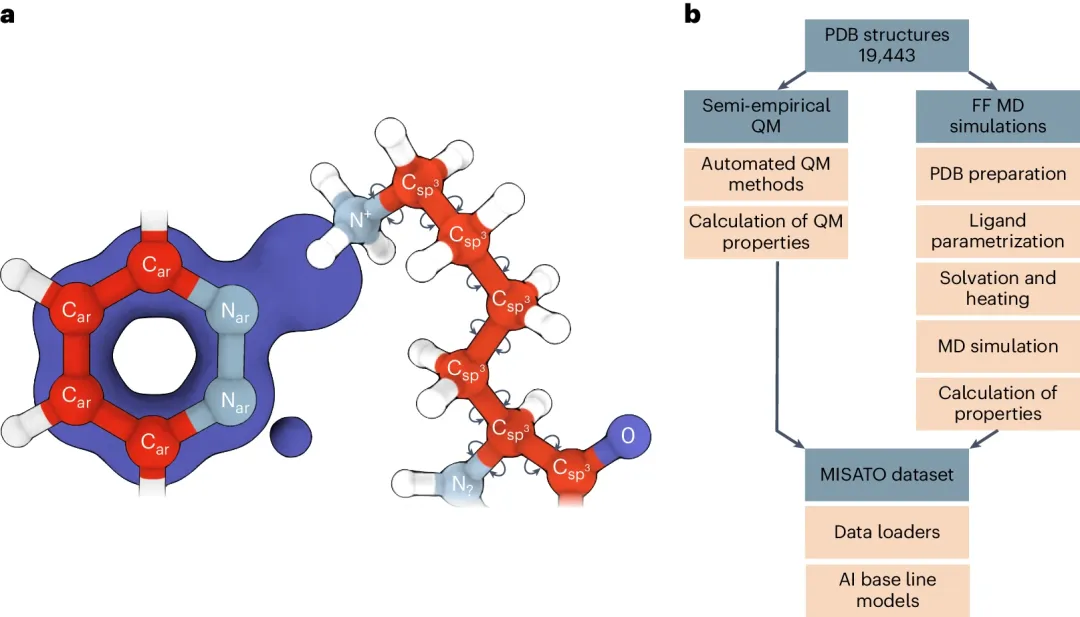
图示:MISATO 将 QM 数据与 MD 衍生的蛋白质配体动力学相结合。(来源:论文)
该团队提供了基于量子化学的结构管理和细化,包括配体几何形状的正则化。研究人员用缺失的动态和化学信息来扩充这个数据库,包括时间尺度上的 MD,允许检测某些系统的瞬态和神秘状态。后者对于成功的药物设计非常重要。
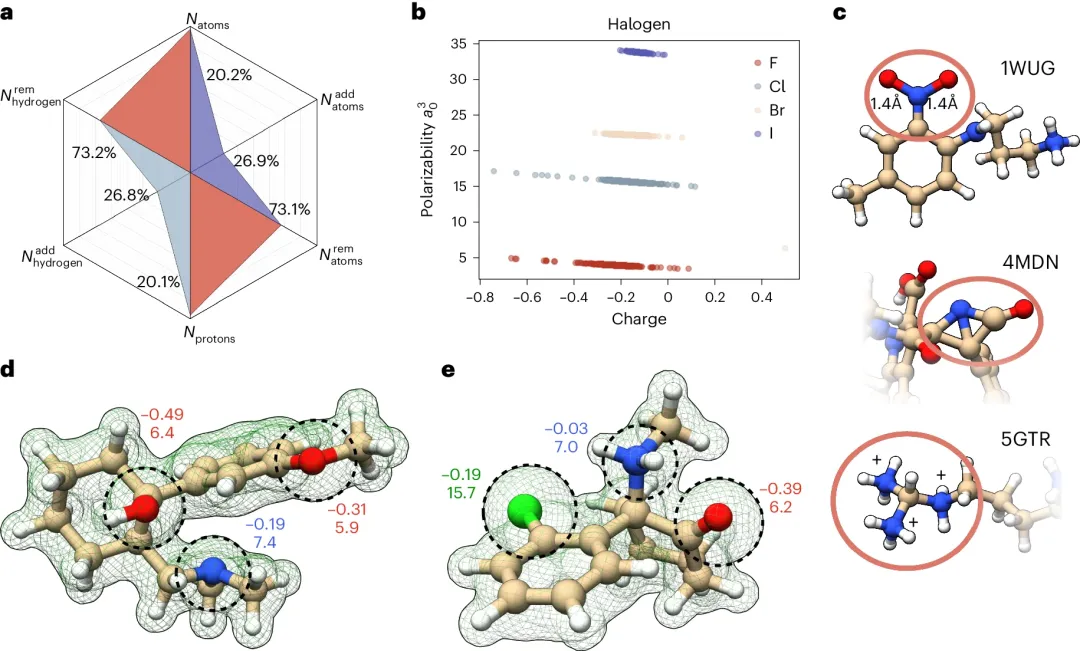
图示:根据量子化学协议对 PDBbind 数据库进行了优化。(来源:论文)
因此,研究人员用最大数量的物理参数补充实验数据。这减轻了人工智能模型隐式学习所有这些信息的负担,从而可以专注于主要学习任务。MISATO 数据库提供了一种用户友好的格式,可以直接导入到机器学习代码中。
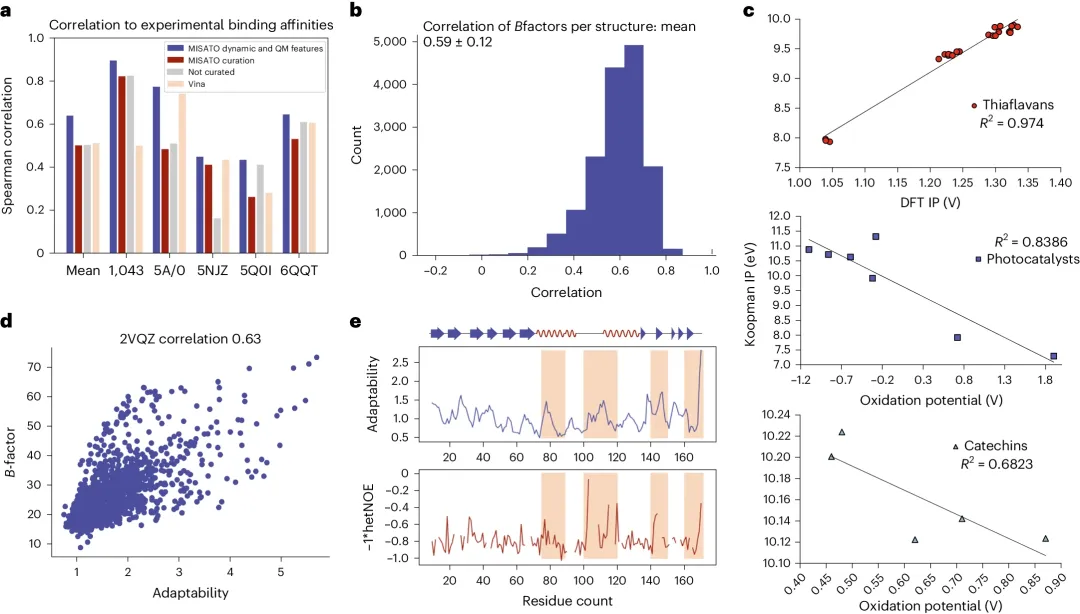
图示:QM、MD 和 AI 模型的实验验证。(来源:论文)
该团队还提供了各种预处理脚本来过滤和可视化数据集。而且,提供了示例 AI 基线模型,用于计算量子化学性质(化学硬度和电子亲和力)、结合亲和力计算以及预测蛋白质灵活性或诱导拟合特征,从而使数据可以被简化采用。并且,QM、MD 和 AI 模型在实验数据上得到了广泛的验证。
研究人员希望将 MISATO 转变为一个有益的社区项目,造福整个药物发现领域。
论文链接:https://www.nature.com/articles/s43588-024-00627-2
编辑:文婧
