本文回顾了大语言模型中的幻觉现象,探讨了其定义、评估和缓解策略。
原文标题:大语言模型LLM,幻觉现象综述和调研
原文作者:数据派THU
冷月清谈:
本文综合了一项关于大语言模型(LLMs)幻觉现象的调研,提出了幻觉的定义、评估基准及减轻策略,以提高LLMs在生成内容时的可靠性。幻觉现象被分类为输入幻觉、上下文幻觉和事实幻觉。对于每种幻觉,文中详细介绍了相应的评估基准测试,包括输入幻觉基准、上下文幻觉基准和事实幻觉基准。同时,提出了在预训练和微调期间减轻幻觉的方法,例如清洗语料库、引入诚实样本和使用人类反馈进行强化学习。推理期间的策略也被探讨,如使用解码策略、外部知识和不确定性管理都旨在减少生成的幻觉内容。此外,文章还展望了未来的研究方向,如多模态幻觉和模型编辑等,为相关领域的研究打下基础。
怜星夜思:
1、你认为幻觉现象会对大语言模型的实际应用造成哪些影响?
2、幻觉现象的根源是什么?是训练数据问题还是模型设计缺陷?
3、如何有效地减少大语言模型产生幻觉的频率?
2、幻觉现象的根源是什么?是训练数据问题还是模型设计缺陷?
3、如何有效地减少大语言模型产生幻觉的频率?
原文内容

来源:深度图学习与大模型LLM本文约3000字,建议阅读6分钟
本文介绍了一篇关于大语言模型LLM的调研综述。
1. 基本信息
论文题目:A Survey on Hallucination in Large Language Models
链接: https://arxiv.org/pdf/2309.01219.pdf
作者:Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, Shuming Shi
机构:Tencent AI Lab, Soochow University, Zhejiang University, Renmin University of China, Nanyang Technological University, Toyota Technological Institute at Chicago
发表日期:24 Sep 2023
摘要:大模型在各种下游任务取得了非常出色的性能,但是我们使用的过程中,不可否认,偶尔会产生下面的一些问题:
-
与用户输入不符(diverges from the user input)
-
与之前生成的内容相矛盾(contradicts previously generated context)
-
与一些事实不一致(misaligns with established world knowledge)
这种现象被称为“幻觉”。本文提出了LLMs幻觉现象的分类,分析了用于评估幻觉的基准测试,探讨了旨在减轻LLMs幻觉的现有方法,并讨论了未来研究的潜在方向。
下面的图片概括了本文的主要内容
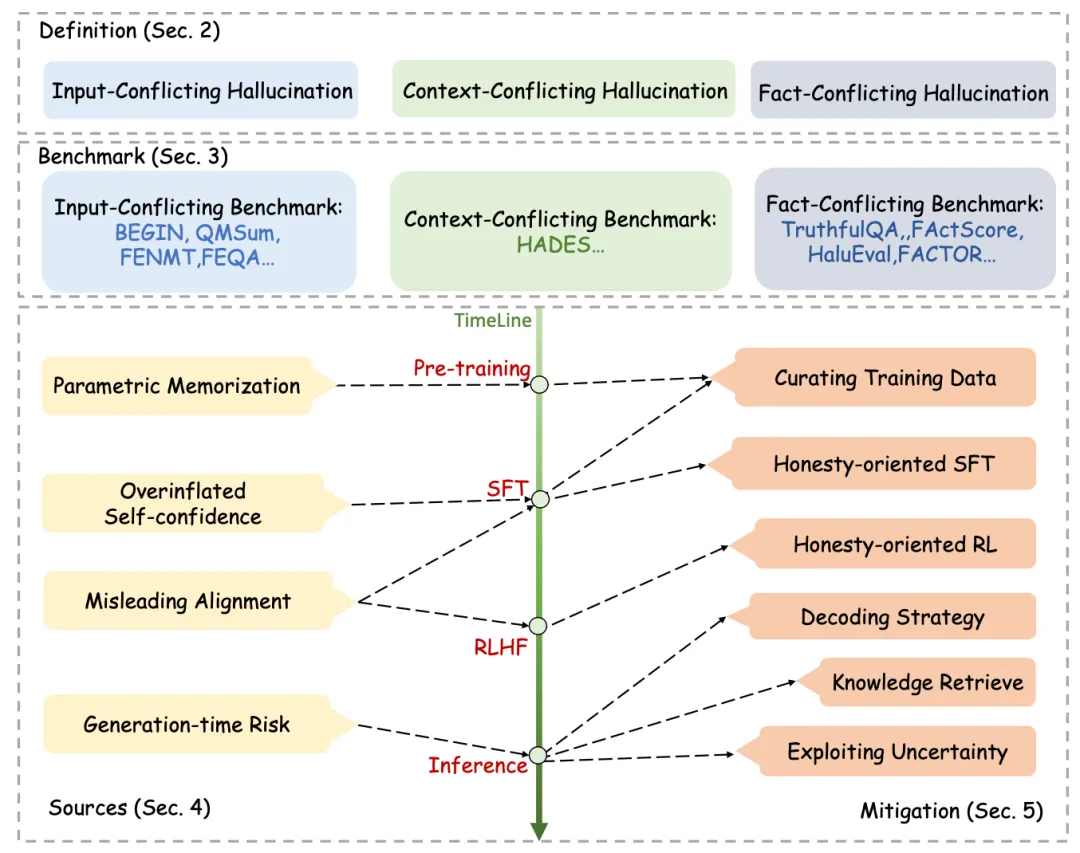
1. 幻觉的三个定义
1.1 输入幻觉(Input-Conflicting Hallucination):这种幻觉发生时,LLMs生成的内容与用户的输入不符。例如,一个模型可能生成与用户问题无关的答案。
1.2 上下文幻觉(Context-Conflicting Hallucination):这类幻觉指的是生成的内容与之前生成的上下文相矛盾。这可能发生在对话生成或相关需要维持一致性的任务中。
1.3 事实幻觉(Fact-Conflicting Hallucination):这种幻觉涉及到生成内容与已建立的世界知识不一致,如事实错误或错误的信息。
2. 三种Benchmark来评估LLM幻觉的问题
2.1 输入幻觉基准(Input-Conflicting Benchmark):这些基准测试旨在评估模型在面对可能引发输入冲突幻觉的任务时的表现,比如QMSum, FENMT, FEQA等。
2.2 上下文幻觉基准(Context-Conflicting Benchmark):如HADES等,这些基准测试用于评估模型在长篇生成或需要上下文一致性的情况下的表现。
2.3 事实幻觉基准(Fact-Conflicting Benchmark):例如TruthfulQA, FActScore, HaluEval, FACTOR等,这些测试用于检测模型在面对需要准确事实信息的任务时是否会产生事实错误。
3. 对应的解决方法
3.1 预训练期间策略(Pre-training):大型语言模型(LLMs)会从大量的训练数据中积累知识,并将其嵌入模型参数中。幻觉可能发生在模型缺乏相关知识或从训练数据中吸收了错误知识时。通过以下方法可以在预训练期间减轻幻觉:
-
清洗预训练语料库:筛选出那些不可靠或不可验证的数据,确保LLMs在训练期间接触到的信息是准确和可靠的。质量控制:使用高质量参考语料库进行相似性匹配来清洗数据,如GPT-3的预训练数据清理过程。
-
数据选择与过滤:自动选择可靠数据或过滤出噪声数据。例如,Llama 2模型在约两万亿token上进行了预训练,并有策略地从事实来源如维基百科中抽样数据。
-
事实性强化:在预训练阶段强调每个句子作为独立事实,通过在句子前添加主题前缀来提高模型对事实性的理解。
“预训练过程中幻觉的缓解主要集中在围绕预训练语料库。目前主要采用简单的启发式规则进行数据选择和过滤。”
3.2 监督式微调(SFT)期间的策略:监督式微调(SFT)是一种常见的做法,主要调整LLMs从预训练中获得的知识,并学习如何与用户互动。在SFT阶段可以采取以下措施:
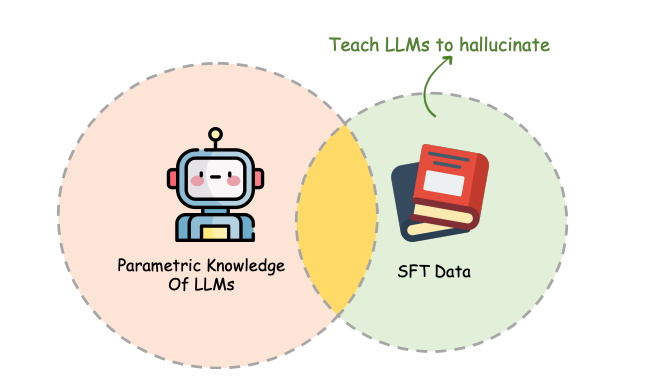
-
Honesty-oriented SFT:在SFT数据中引入诚实样本,这些样本会承认“我不知道”或表达无法回答某些问题的无能为力,从而教会LLMs在其知识范围之外时如何适当回应。
-
质量监控:手动或自动策划SFT数据,选择高质量的指令性数据,通过人类专家手动标注或设计特定规则来自动选择。
-
行为克隆风险管理:注意SFT过程中可能通过模仿专家行为而引入的幻觉,这可能导致模型学习到的是形式和风格而非实质内容。

3.3 基于人类反馈的强化学习(RLHF):RLHF是一种训练策略,通过人类反馈来强化和调整LLMs的行为。这种方法可以在LLMs推理阶段减少幻觉风险:
-
不确定性处理:教会模型如何处理不确定性问题,而不是盲目自信地生成答案。
-
知识边界识别:帮助模型识别其知识边界,避免在无法给出准确答案时生成幻觉内容。
-
适应性学习:使LLMs能够在面对超出其知识范围的问题时,学会如何拒绝回答或表明自己的不确定性。
“RLHF可能会表现出保守主义,在helpfulness和honesty之间存在imbalanced trade-off. 比如说,下图的回答就是一个例子:ChatGPT倾向于过度回避,避免提供它已经知道的答案。”

3.4 推理期间(inference time)的幻觉缓解策略
设计解码策略
-
解码策略:比如贪婪解码和beam search解码,它们决定了我们如何从模型生成的概率分布中选择输出token。
-
factual-nucleus sampling:Lee et al. (2022) 提出了一种新的解码算法,旨在通过结合top-p采样和贪婪解码的优势来更有效地平衡多样性和事实性。
“该方法易于部署,具有应用前景。然而,对于这种方法,大多数都需要访问token输出概率,而大量llm是闭源的,无法获得这样的信息”
依赖外部知识
-
链式验证框架(CoVE):Dhuliawala et al. (2023) 开发了基于独立验证问题的观察的解码框架,以改进长答案的事实性。
-
推理-时间干预(ITI):Li et al. (2023b) 引入了一种新的方法,基于LLMs具有与事实解释相关的潜在、可解释的子结构的假设,通过在每个注意力头上拟合二分类器来识别出与事实性相关的头集合,并在推理期间沿这些事实性相关的方向调整模型激活。
-
上下文感知解码(CAD):Shi et al. (2023b) 提出了一种直接的上下文感知解码策略,旨在仅考虑查询来改进生成的内容的事实性。
利用外部知识
-
知识获取:LLMs通过预训练和微调获取大量内部化知识。然而,不正确或过时的参数化知识可能导致幻觉。研究人员提议从可靠来源获取最新的、可验证的知识作为外部知识库的一种补充。
-
外部工具:除了仅从知识库检索信息之外,还可以使用外部工具向LLMs提供有价值的证据,以增强它们生成的内容的真实性。
利用不确定性
-
不确定性:作为一个有价值的指标,可以指导对回答的生成做出调整,以减少幻觉的产生。
这些方法展示了在模型的推理阶段可以实施的多种策略,以减少或缓解幻觉现象,从而提高LLMs的可靠性和实用性。
在第5.5节及其之后的部分,论文讨论了多种缓解大型语言模型(LLMs)幻觉的方法,并提出了一些研究展望。以下是每部分的详细内容:
除此之外,作者提到了其他的方法,比如说
多智能体互动 (Multi-agent Interaction)
-
通过多个LLMs(作为独立代理)的独立提案和协作辩论来减轻幻觉,这些代理会独立讨论并达成共识。
提示工程 (Prompt Engineering)
-
强调使用有效提示来缓解幻觉,提出链式思维提示来促使LLMs生成推理步骤并编排最终答案。
分析LLMs内部状态 (Analyzing LLMs’ Internal States)
-
提出了声明准确性预测层(SAPLMA),这是一个分类器,用于教会LLMs识别自己生成的可能是虚假的信息。
Human-in-the-loop
-
介绍了一个框架,利用LLMs对用户查询进行迭代解答,并通过人类参与来调整答案以减轻幻觉。
那么未来还有什么值得进行研究呢?
可靠的评估 (Reliable Evaluation)
-
讨论了评估LLMs中幻觉的现有基准的问题,并指出了需要解决的问题,如自动生成的评估与人类注释的一致性。
多语言幻觉 (Multi-lingual Hallucination)
-
强调了LLMs在低资源语言中处理幻觉的挑战,建议进行系统性后续工作和跨多种语言的调查。
多模态幻觉 (Multi-modal Hallucination)
-
探索了在多模态上下文中减轻LLMs幻觉的方法,包括将LLMs扩展到其他模态,如音频和视频。
模型编辑 (Model Editing)
-
讨论了直接修改LLMs参数以减少幻觉的方法。
攻击/防御诱发幻觉 (Attack/Defense for Inducing Hallucination)
-
强调了攻击和防御策略在缓解幻觉方面的重要性。
编辑:王菁
