学习如何在R中实现LASSO回归算法,包含代码与示例。
原文标题:R语言实现LASSO回归——自己编写LASSO回归算法
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、在使用LASSO回归时,如何选择合适的lambda值?
3、除了LASSO,还有哪些回归方法适合高维数据分析?
原文内容

本文约500字,建议阅读5分钟
这篇文章中我们可以编写自己的代码来计算套索(lasso)回归。
相关视频
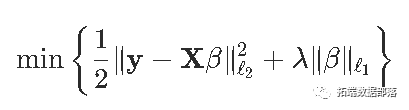
我们必须定义阈值函数
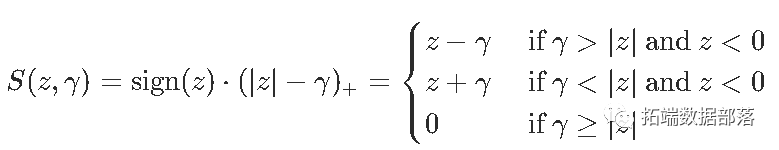
R函数是:
thresh = function(x,a){
sign(x) * pmax(abs(x)-a,0)
}
要解决我们的优化问题,设置
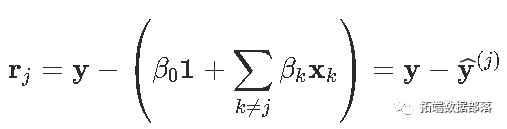
这样就可以等效地写出优化问题
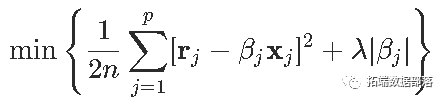
因此
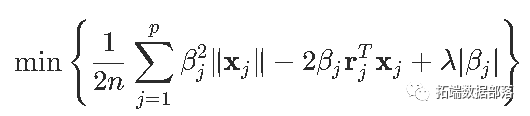
一个得到
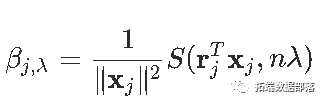
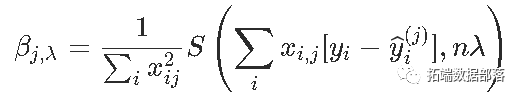
同样,如果有权重ω=(ωi),则按坐标更新将变为
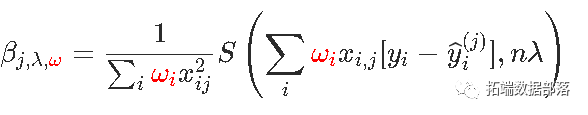
计算此分量下降的代码是:
lasso = function(X,y,beta,lambda,tol=1e-6,maxiter=1000){beta0 = sum(y-X%%beta /(length(y))
beta0list[1] = beta0
for (j in 1:maxiter){
for (k in 1:length beta)){
r = y - X[,-k]%%beta[-k] - beta0rep(1,length(y )
beta[k] = (1/sum(omegaX[,k]^2) *
threshog(t(omegar)%%X[,k ,length(y lambda)
}
beta0 = sum(y-X%%beta)/(length(y))
obj[j] = (1/2)(1/length(y))norm(omega(y - X%%beta -
beta0rep(1,length(y))),‘F’)^2 + lambdasum(abs(beta))
if (norm(rbind(beta0list[j],betalist[[j]]) -
rbind(beta0,beta),‘F’) ) { break }
例如,考虑以下(简单)数据集,其中包含三个协变量:
chicago = read.table("data.txt",header=TRUE,sep=";")
我们可以“标准化”
for(j in 1:3) X[,j] = (X[,j]-mean(X[,j]))/sd(X[,j])
y = (y-mean(y))/sd(y)
要初始化算法,使用OLS估算
lm(y~0+.,)$coef
例如
lasso(X,y,beta_init,lambda=.001) $obj [1] 0.001014426 0.001008009 0.001009558 0.001011094 0.001011119 0.001011119$beta
[,1]
X_1 0.0000000
X_2 0.3836087
X_3 -0.5026137
$intercept
[1] 2.060999e-16
我们可以通过循环获得标准的lasso图
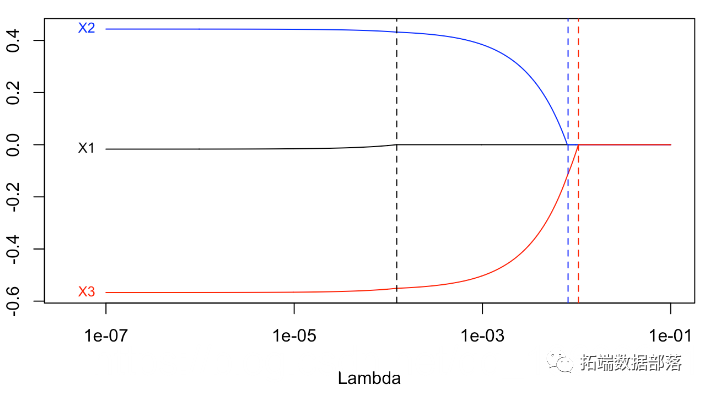
原文链接:http://tecdat.cn/?p=18840
编辑:于腾凯
校对:林亦霖
