浙江大学提出的WISE方法,通过双重记忆机制和知识分片技术,有效解决大模型知识记忆的更新问题。
原文标题:NeurIPS 2024|解锁大模型知识记忆编辑的新路径,浙大用「WISE」对抗幻觉
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、除WISE方法外,还有哪些大模型知识编辑的备选方案?
3、未来大模型如何确保知识编辑的安全性?
原文内容

来源:人工智能前沿讲习本文约3600字,建议阅读10分钟
本文为长期模型知识编辑提供了一种新颖的解决思路,通过侧记忆设计和知识分片技术,在不牺牲模型性能的情况下,实现了知识的有效更新。
本文约3600字,建议阅读10分钟
本文为长期模型知识编辑提供了一种新颖的解决思路,通过侧记忆设计和知识分片技术,在不牺牲模型性能的情况下,实现了知识的有效更新。
本篇工作已被 NeurIPS(2024 Conference on Neural Information Processing Systems)会议接收,文章第一作者为浙江大学软件学院硕士生王鹏,师从张宁豫副教授。
在当前人工智能的迅猛发展中,大模型的知识记忆能力成为了提升智能系统理解和推理能力的关键。然而,与人类记忆相比,机器记忆缺乏灵活性和可控性,难以在动态环境中实现有效的知识更新与编辑。人类的大脑拥有高度适应性的记忆机制,能够根据外部环境变化及时进行信息的筛选、修正与增强。这种能力不仅使得我们能够精准地获取信息,还可以根据任务需求高效地调用相关知识。
相比之下,现有的大模型主要依赖固定的参数和数据来存储知识,一旦训练完成,修改和更新特定知识的代价极大,常常因知识谬误导致模型输出不准确或引发「幻觉」现象。因此,如何对大模型的知识记忆进行精确控制和编辑,成为当前研究的前沿热点。
本文借鉴认知科学和人类记忆的机制,探讨了大模型终身知识编辑问题,提出了一种基于双重记忆机制的大模型知识编辑方法 WISE,旨在持续更新大语言模型的世界知识和纠正其幻觉性输出。此工作结合参数化长期记忆和工作记忆,在保持语言模型通用能力的同时可成功对模型进行数千次连续编辑。

论文链接: https://arxiv.org/abs/2405.14768
代码链接: https://github.com/zjunlp/EasyEdit
1. 背景与挑战
随着大模型(LLMs)的广泛应用,持续更新其世界知识和纠正幻觉性输出成为一个关键问题。过去的方法在长期模型知识编辑中往往无法同时实现可靠性、泛化性和局部性,这被称为「不可实现三角」(如下图)。

2. 理论基础
2.1 终生模型知识编辑定义
终生模型知识编辑问题专注于对 LLMs 进行连续的、大量的编辑操作,目的是使模型的输出能够与人类预期保持一致,同时保留模型先前的知识与能力 (如图 2 所示)。具体来说,就是通过一系列时间序列上的编辑操作,逐步改进模型对特定查询的处理能力,这些编辑操作由一个不断变化的编辑数据集 来驱动 [3,16,17]。
图 2 终生模型编辑任务示意图
终生模型编辑的目标是实现以下三个关键特性:
其过程可以描述为:给定一个已经在 上预训练的模型 ,当模型需要纠正错误或注入新知识时会使用一个随时间变化的编辑数据集 来进行编辑操作。在第 T 个编辑步骤中, 模型知识编辑器(Model Editor, ME)接收第 T 个编辑样例和 T-1 步的的模型 , 并产生修正后的 LLM 模型 。遵循以下等式:

 是当前编辑步骤的输入,
是当前编辑步骤的输入,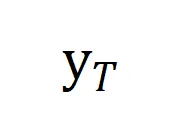 是期望输出;同时保留对过去编辑步骤中输入
是期望输出;同时保留对过去编辑步骤中输入 的记忆,并维持对不相关数据
的记忆,并维持对不相关数据 的处理能力。
的处理能力。
注意,使用终生模型知识编辑技术并非必须一直编辑大模型,如积累大量新数据后可通过全量微调继续更新大模型的知识。终生模型知识编辑技术适用于小数据持续知识更新和谬误修正。
2.2 语言模型中的知识记忆
在人类认知中,工作记忆为生物大脑提供了暂时保存信息的能力,以便以适应不断变化的环境的方式执行对话、推理和数学等任务。相似地,过去的文献 [8, 9, 10] 表明语言模型的记忆可分为长期(情节性的)记忆和工作记忆(短期):工作记忆可能存储在神经元的持续激活(推理时的 Activation)中,长期记忆可能存储在模型参数(Weight)中。
我们发现更新的知识驻留在记忆中的位置会影响编辑性能,现有方法可以大致分为两类:编辑长期记忆和编辑工作记忆。长期记忆是通过直接编辑模型参数来更新通用的参数化知识,这种方法会与之前的预训练知识产生冲突,导致局部性较差 (例如 FT-EWC [1]、ROME [2]);而工作记忆则是在推理时通过检索替换神经网络的激活/表征,不修改模型参数。尽管工作记忆方法在可靠性和局部性上表现优异,但其检索到的表征难以实现泛化,导致编辑的知识无法有效推广(例如 GRACE [3]、SERAC [4])。这些揭示了长期记忆和工作记忆对于终身模型编辑都有缺点。
此外,尽管有一些针对 LLM 架构的特殊记忆设计,如 MemorryLLM [6] 和 Memoria [7],它们改变了模型架构(大部分 Train from scratch)且不能直接应用于不同的 LLMs。
图 3 当前模型编辑方法的比较
这启发我们提出一个关键科学问题:如何设计适配大模型的知识记忆更新机制,以打破终生知识编辑中的不可能三角?
3. WISE 方法介绍

人类大脑的左右半球在不同任务中的分工给了我们灵感,这启发我们设计了 WISE,一个具备双参数记忆机制的框架。WISE 通过主记忆存储预训练知识,并引入侧记忆来专门存储编辑后的知识。侧记忆可以被视为一种中期记忆,它结合了长时记忆的泛化能力和基于检索的工作记忆的可靠性与局部性。我们仅在侧记忆中进行编辑,并训练一个路由器来决定在处理查询时应使用哪种记忆。
为了实现连续编辑,WISE 还设计了一种知识分片机制,将不同的编辑集合存储在独立的、正交的子空间中,最后将这些编辑合并为统一的侧记忆。主记忆存储模型在预训练阶段学到的知识:
1. 侧记忆(Wv’) 作为一个副本,记录模型在编辑后的更新信息。

2. 知识分片:将侧记忆划分成不同的随机子空间来存储编辑信息。具体来说,对于第 i 个编辑碎片,我们为其生成一个随机梯度掩码 Mi。这些掩码确保了每次编辑都仅在侧记忆的特定子空间中进行,从而实现了编辑的局部化和正交化。

3. 自适应 Gate:采用基于激活的门控策略来决定在给定查询时使用主记忆还是侧记忆。门控激活指示器的计算方式是比较侧记忆和主记忆的激活差异(如下列公式所示)。我们设计了基于边界的损失函数,确保编辑查询的激活指标比无关查询大,具体目标是:编辑查询的激活值应大于无关查询,且两者之间的差异超过设定的阈值 γ

4. 知识合并:通过 Ties-Merge [5] 技术将各个子空间的知识合并为一致的表征,实现参数的高效利用。
4. 实验结果
实验结果表明,直接修改模型权重会覆盖预训练的知识,导致新旧知识冲突,破坏局部性,影响模型对非编辑领域的保留。
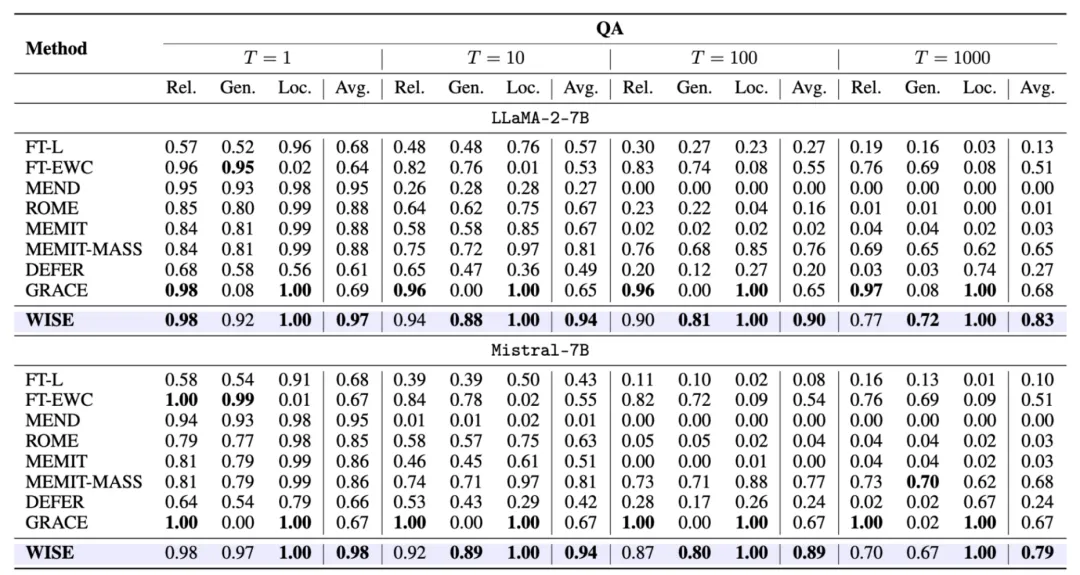
WISE 在多个任务(如问答、幻觉修正、分布外数据)上表现出色,尤其是在 LLaMA、GPT 等架构中,WISE 大幅超越现有编辑方法。通过评估可靠性、泛化性和局部性三项指标,WISE 在长期编辑中能够有效解决模型冲突问题,并展示了优异的稳定性和扩展性。
5. 实验分析
处理长序列持续编辑的潜力

WISE 在 3K 次编辑下表现出色,尤其是 WISE-Retrieve 通过高效的子空间组织和路由机制,能够在较少性能下降的情况下应对大量编辑。
路由激活可视化

WISE 通过激活指标准确区分编辑查询与非相关查询,确保编辑的局部性,并成功将相关查询路由到侧记忆,避免干扰预训练知识。
在 LLM 中的引入位置

应在 LLM 的中间到后期层引入侧记忆。这些层被认为能够更好地处理高级语言现象,并且通过残差连接保持了较低层次的语义信息,使得编辑操作能够更有效地影响模型的输出。
WISE 的额外开销

在编辑次数 3K 时,仅增加了 0.64% 的参数量和 4% 的 GPU 显存需求,且推理时间开销较小,具有较高的计算效率。
6. 总结与展望
本文为长期模型知识编辑提供了一种新颖的解决思路,通过侧记忆设计和知识分片技术,在不牺牲模型性能的情况下,实现了知识的有效更新。未来的研究可以进一步优化路由策略,提升侧记忆的检索效率;探索更好的记忆架构,以应对更加复杂的编辑场景。
当前阶段,针对事实和实例记忆等类型的知识编辑,通常采用以下几种方法:外部记忆更新(如 RAG、Memory 等 [12][13])、局部参数更新(如 ROME [2]、AlphaEdit [11])或全局参数更新(如微调或对齐)。而对于更抽象的知识类型,如安全性、人格或自我认知等,还可使用运行时干预(Steering [12][13])或慢思考方法(如借助 o1 思想进行错误修正)。
不断提升大模型的知识处理能力,进而实现通用人工智能(AGI),是学术界与工业界的共同目标。大模型知识编辑技术的突破,不仅能够促进大模型对新知识和新技能的快速、永久习得,还可以实现神经与符号知识之间的高效转换与处理。此外,当大模型出现致命错误或安全隐患时,基于知识编辑技术可以快速定位问题根源,并实现及时的干预和控制。这种技术对确保大模型的可信与安全至关重要。
此外,大模型的知识编辑技术不仅能有效优化模型的表现,还能促进对大模型知识机理的深入研究。通过对参数进行干预与分析,研究人员可以进一步解构并理解 「电子大脑」的运作原理。
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
