研究探讨CLIP模型在适应下游任务时的失配问题,提出因果引导的解耦与分类方法,实验结果显示其有效性。
原文标题:【NeurIPS2024】从因果角度重新思考视觉-语言模型适应中的失配问题
原文作者:数据派THU
冷月清谈:
本文探讨了视觉-语言模型(如CLIP)在适应下游任务时面临的失配问题,具体分析了任务失配和数据失配两个层面。虽然软提示调优在缓解任务失配方面表现良好,但数据失配仍是一个明显挑战。为深入解析数据失配的影响,研究者构建了结构化因果模型,发现任务无关的知识对预测结果产生负面影响,并妨碍真实图像与预测类别的关联建模。为了减少这种干扰,提出了一种因果引导的语义解耦与分类方法(CDC),通过解耦下游任务数据中的语义实现更精确的分类。此外,利用Dempster-Shafer证据理论评估不同语义产生的预测不确定性。实验结果表明CDC在多种设定下均表现出良好的有效性,推动了视觉-语言模型在特定任务中的应用。
怜星夜思:
1、如何看待CLIP模型在下游任务中存在的数据失配问题?
2、因果模型在解决失配问题方面有什么优势?
3、你认为除了CDC,还有什么方法可以解决失配问题?
2、因果模型在解决失配问题方面有什么优势?
3、你认为除了CDC,还有什么方法可以解决失配问题?
原文内容

来源:专知本文约1000字,建议阅读5分钟
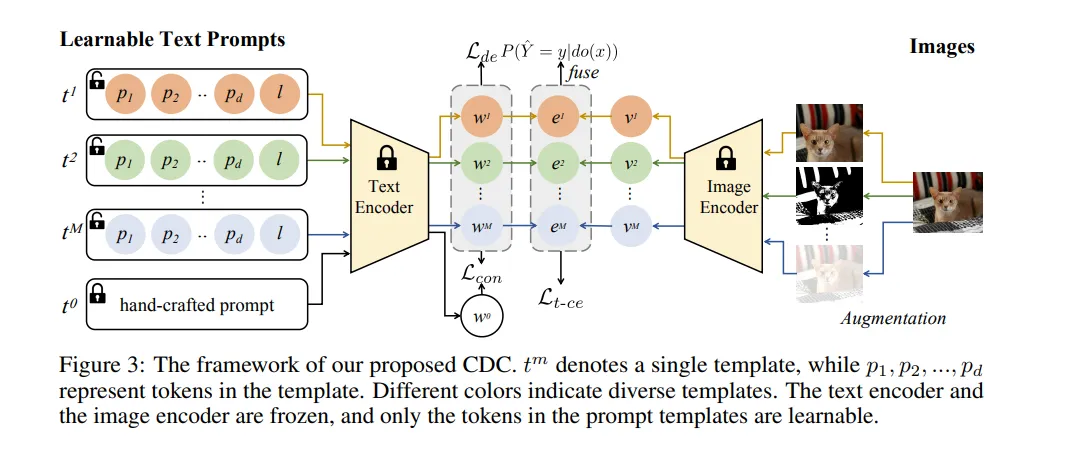
我们对下游任务数据中包含的语义进行解耦,并基于每个语义执行分类。

基础视觉-语言模型(如CLIP)在下游任务中展示了出色的泛化能力。然而,CLIP在适应特定任务时存在两个层次的失配问题,即任务失配和数据失配。虽然软提示调优在一定程度上缓解了任务失配,但数据失配仍然是一个挑战。为分析数据失配的影响,我们重新审视了CLIP的预训练和适应过程,并构建了一个结构化因果模型。我们发现,尽管期望精确捕捉下游任务的相关信息,但与任务无关的知识影响了预测结果,并阻碍了真实图像与预测类别之间关系的建模。由于任务无关的知识是不可观察的,我们利用前门调整并提出因果引导的语义解耦与分类方法(CDC)来减少任务无关知识的干扰。具体而言,我们对下游任务数据中包含的语义进行解耦,并基于每个语义执行分类。此外,我们采用Dempster-Shafer证据理论来评估由不同语义生成的每个预测的不确定性。在多种不同设置下进行的实验一致证明了CDC的有效性。