本文探讨大模型优化技术,从Few-shot学习到自动化提示优化,提供实践指南。深入分析了现代工具在提升模型表现中的作用。
原文标题:原创 | 大模型扫盲系列——模型优化实践从OpenAI到个人专属-Prompt 工程优化技巧( 下)
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、在大模型优化中,Prompt工程和负样本的选择重要吗?
3、DSPy和Text-Grad有何不同,哪个更适合初学者使用?
原文内容

作者:金一鸣本文约5000字,建议阅读10分钟
本文介绍优化大模型效果的大利器,从而帮助读者在实战中高效地选择技术方案来优化模型效果。
1. Few-shot技巧
Few-shot学习是一种机器学习方法,在这种方法中,模型可以从少量的示例(例如1到几百个)中学习特定任务或概念。但在大模型Prompt领域,这种方式准确的应该理解为In-context Learning,这是一种特定的few-shot学习形式,通常指的是在模型推理过程中通过上下文示例来引导模型理解和解决任务。模型并不会对这些示例进行再训练或微调,而是直接在推理过程中使用它们。作用方式通常是在描述任务时提供一些高质量的例子来辅助说明这个任务工作方式,比如举一个one-shot的例子:
![]()

![]()

另外对于选择few-shot的数量,论文中也对比了例子数量对最后效果的影响,从图中可以看到zero-shot是最低的分数,当随着 K 不断增大时,我们发现 GPT-3 每个任务只需要不到 8 个示例,就能在整体 SuperGLUE 得分上胜过经过微调的 BERT-Large,后面例子越多甚至能超过微调的BERT++。下图分别是数据集上三种方式(zero-shot,one-shot,few-shot)的样例,可以直观的感受few-shot的使用方式。当然这里需要注意的是对于实践中的任务来说,大多数情况下不一定是例子给的越多越好,主要由任务的难度,模型的大小等因素综合决定,需要具体去实践得到比较好的效果,同时也要考虑例子的质量,包含例子与任务相关性,多样性,准确性等多个维度来使用few-shot。
![]()


![]()
![]()

所以选择的时候尽量选择正确,与任务相关性高或者高质量的示例来作为few shot正向效果的参考。
最近一篇新的文章(https://arxiv.org/pdf/2406.15708)也得到了few shot如何选择对优化重要性的结论,并且作者强调了用自动化提示词优化(Automatic prompt optimization,APO)方式对优化指令和例子的重要性:
即使对于功能强大的指令遵循模型,Exemplar selection (ES) 可能成为prompt优化中更重要的元素,说明了few shot对于优化效果的重要性比优化指令的重要性更高。当然文章说最好的效果是通过Instruction Optimization(IO) 和ES联合优化,可以展现出有益的协同作用。
![]()

2. 终极技巧:组合拳
实践中大多数情况下,最有效的方式还是对任务使用尽可能有效的多个prompt技巧。在微软发布的一篇领域大模型相关的文章(https://arxiv.org/pdf/2311.16452)中可以借鉴,他们选择医学领域作为一个测试,设计了一种非常新颖的Prompt技术,结合了领域数据,验证GPT-4在不微调的情况下也能超越领域专用大模型(如Med-PaLM2)。注意,也就是说这里是使用通用大模型+prompt技术挑战专用大模型在专业领域的效果。其中文章中就是利用多种prompt技巧,通过只用prompt方式就可以得到一个比较好的实践效果。
![]()
![]()

在微软的实践中,主要是为GPT-4准备医学相关的预训练数据。在用户提出领域问题之前,系统会先利用检索技术,从训练数据中找到与问题相似的问答结果。接着,系统生成few-shot示例,将这些示例嵌入用户输入的问题中,最后由模型基于这些上下文来进行回答。主要用到的核心策略有:
-
动态少样本选择(Dynamic few-shot)
-
自生成思维链(Self-generated chain of thought)
-
选项洗牌集成(Choice Shuffling Ensemble)
从下图实验结果中也能很明显看到每种策略在这个任务上带来的收益,对比一开始的zero-shot还是比较巨大的提升。
![]()

![]() 以上介绍的方法都是基本提示工程相关的理论技巧,在运用过程中,很头痛的一件事情就是需要反复调试,反复斟酌提示语句的有效性和准确性来达到最后效果的优化,对于程序员来说确实非常低效且费时,刚刚提到的APO就是一种很好的解决方式。自动化提示优化主要是通过系统化地改进和调整提示,减少人工干预,使得模型能够更好地理解任务要求并产生更优的输出。
以上介绍的方法都是基本提示工程相关的理论技巧,在运用过程中,很头痛的一件事情就是需要反复调试,反复斟酌提示语句的有效性和准确性来达到最后效果的优化,对于程序员来说确实非常低效且费时,刚刚提到的APO就是一种很好的解决方式。自动化提示优化主要是通过系统化地改进和调整提示,减少人工干预,使得模型能够更好地理解任务要求并产生更优的输出。
3. DSPy
从去年年底斯坦福的NLP团队发布了DSPY: COMPILING DECLARATIVE LANGUAGE MODEL CALLS INTO SELF-IMPROVING PIPELINES(https://arxiv.org/pdf/2310.03714)以来,很多Prompt Engineer就迎来了第一波春天,一直期盼着有一个成熟的框架可以通过自动优化prompt来解放人工的想法终于实现了。它的核心思想是将传统的硬编码提示模板转变为可编程、可编译的模块化方法,以实现更系统化和自动化的优化。
DSPy 主要流程是:首先,它将程序流(模块)与每个步骤的参数(LM 提示和权重)分开。其次,DSPy 引入了新的优化器,这些是由语言模型驱动的算法,可以在给定你想要最大化的指标的情况下,调整你的语言模型调用的提示或权重。这里给出一个很简单的数学问题的例子,通过这个例子来大致了解一下这个框架对任务粒度进行迭代的整个流程。
1. 明确任务并定义问题签名
首先需要明确要解决的问题。在本示例中,目标是创建一个系统,能够自动解答数学文字题。
示例输入/输出:
-
输入:“如果一个香蕉2元,买3个香蕉需要多少钱?”。
-
输出:“6元”。
定义问题签名:
-
需要定义一个签名(signature),它是一个自然语言的类型声明,描述了函数的输入和输出。
-
例如,对于数学问答任务,我们可以定义一个签名 "question -> answer"。
2. 定义模块和数据管道
-
DSPy提供了一系列的内置模块,如Predict、ChainOfThought等,可以直接使用这些模块,或者根据需要创建自定义模块。
-
对于数学问题,可能会选择使用ChainOfThought模块,它能够通过逐步推理来生成答案。
3. 编写DSPy程序
-
使用DSPy模块来构建一个处理文本的计算图。
-
例如,可以创建一个ChainOfThought实例,并将其用于问题和答案生成。

![]() 4、编译和优化:
4、编译和优化:
-
使用DSPy编译器和引导式优化器(BootstrapFewShot)来优化程序。
-
编译器将根据提供的训练数据和验证指标来自举式地生成和选择有用的示例。

![]()
5、评估和迭代:
-
使用验证集评估编译后的程序。对本次问题主要参考的指标就是问题回答的准确率,通过对生成回答的准确率进行多轮迭代。
-
如果结果不满意,可以进一步调整模块、增加训练数据或更改优化策略。
6、部署和使用:
-
一旦程序达到满意的性能,就可以部署为一个服务,用于回答这类任务。

![]() 如果想在实践中针对具体问题进行使用的话建议看一下官网的教程(https://dspy-docs.vercel.app/docs/category/quick-start)以及他们在github上官方的仓库(https://github.com/stanfordnlp/dspy)上面也提供了不同类型任务的例子,在实践中会比较有帮助。
如果想在实践中针对具体问题进行使用的话建议看一下官网的教程(https://dspy-docs.vercel.app/docs/category/quick-start)以及他们在github上官方的仓库(https://github.com/stanfordnlp/dspy)上面也提供了不同类型任务的例子,在实践中会比较有帮助。
4. Text-Grad
同样是斯坦福的团队,最近刚提出了以神经网络中梯度下降为借鉴的文本梯度下降(Textual Gradient Descent, TGD)方法来迭代提示词(https://arxiv.org/pdf/2406.07496),迭代过程中也有批计算,梯度,反向传播,测试集,验证集等概念。相比于比较黑盒的DSPy更容易上手,并且还能打印出每一步迭代prompt的建议结果。并且论文中作者提到一个对比实验,使用gpt-4o来改善gpt-3.5-turbo-0125的性能,以便在反向传播期间提供反馈。具体来说就是执行推理的前向模型是弱模型,但我们使用强模型来提供反馈并改进提示。同时对比DSPy和TextGrad进行迭代的效果,下图可以看出在一些数据集上效果也更好。TextGrad只是针对文本数据,核心思想是利用从语言模型(LLMs)获得的文本反馈(即文本梯度)来指导文本变量的更新。这些文本梯度描述了如何修改文本变量以改善整体目标函数(如提高预测准确性或增强文本的可读性)。
![]()
![]()
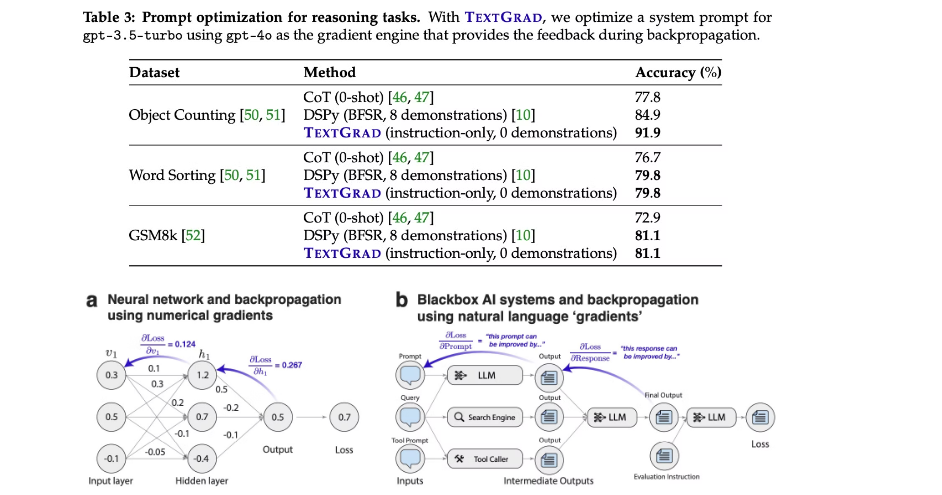
![]() 简单总结一下具体执行流程,整个迭代流程与神经网络迭代思路非常相似:
简单总结一下具体执行流程,整个迭代流程与神经网络迭代思路非常相似:
1. 计算图的定义与构建
-
计算图构建:将AI系统抽象为一个计算图,图中包含多个变量(如输入数据、提示、模型参数等)和函数(如模型运算、API调用等)。这些变量和函数共同构成了系统的运作流程。
-
变量角色:每个变量在计算图中都有其特定的角色描述,明确了它们在优化过程中所扮演的角色及其期望功能。这为后续的优化提供了指导方向。
2. Prompt作为计算图中的变量
-
Prompt定义:在计算图中,prompt被定义为一个变量,作为输入传递给大语言模型(LLM),用于生成相应的输出或预测结果。
-
初始化:通常,prompt从一个或多个初始值开始,这些初始值可以是简单的文本字符串,代表初始输入。
3. 前向传播过程
-
生成输出:在前向传播过程中,系统使用当前的prompt,通过LLM生成输出或预测结果。这一步模拟了实际中使用prompt进行任务时的过程。
-
损失计算:基于生成的输出,系统会计算损失函数。损失函数衡量了生成结果与期望目标之间的差距,体现了当前prompt的效果。
4. 损失函数评估
-
目标函数:损失函数用于评估输出相对于特定任务目标的表现(如提高问答系统的准确性或优化代码片段的执行效率等)。
-
反馈获取:损失函数的结果为prompt的优化提供了直接的反馈,帮助识别改进的方向。
5. 反向传播与文本梯度生成
-
文本梯度生成:通过LLM生成关于如何改进prompt的自然语言反馈,这些反馈类似于传统优化中的梯度,用于指导prompt的调整。
-
梯度聚合:来自不同维度(如输出质量、准确率等)的文本梯度被聚合,以形成全面的prompt改进建议。
6. 文本梯度下降(TGD)方法
-
优化算法:系统采用文本梯度下降算法,模拟传统梯度下降过程来更新prompt。不同的是,该算法适用于处理文本数据。
-
参数更新:基于文本梯度的反馈,调整prompt的内容,以期在后续迭代中提升生成效果。
7. 迭代优化流程
-
循环迭代:该优化过程是一个循环,每次迭代都会重复执行前向传播、损失评估、反向传播以及参数更新,直到达到停止条件(如最大迭代次数或性能提升不再显著)。
-
性能监控:在每次迭代之后,系统会监控prompt的性能表现,以评估优化效果。
8. 优化技术的应用
-
批处理优化:在同时处理多个prompt时,系统可以采用批处理优化技术,一次性更新多个实例,提升优化效率。
-
约束优化:在某些场景下,优化过程可能需要在特定的约束条件下进行,例如保持prompt的格式或风格。
-
动量方法:通过引入动量方法,优化过程可以加速,系统通过参考历史梯度信息来调整当前梯度的影响,从而提升收敛速度。
9. 最终评估与策略调整
-
性能评估:定期对优化后的prompt在实际任务中的表现进行评估,确保其达到了预期目标。
-
策略调整:根据评估结果,系统可能需要对优化策略进行调整,例如修改损失函数、优化算法的参数,或是改变文本梯度的生成方式,以进一步提升效果。
另外一个方面值得注意的是,这些框架在不同任务以及场景下具体的效果还是取决于任务的复杂程度,在实践场景中,并不能完全确保能比直接人工迭代的prompt效果要好,理论上来看,在复杂推理场景使用这些框架进行迭代是有比较好的效果,但是从效率和提示词优化方向角度看,这些框架无疑是给了一些启发。
Reference:
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
