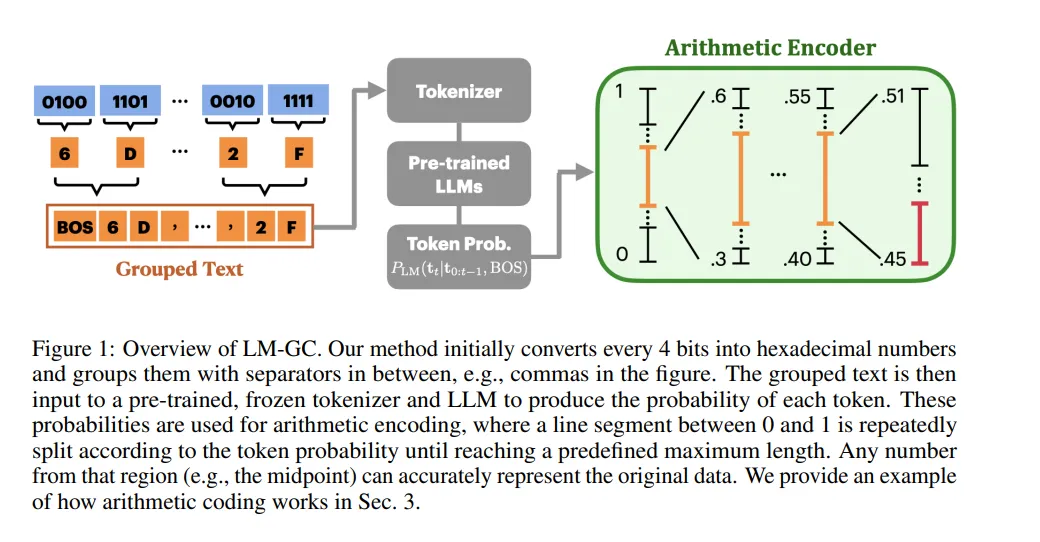
LM-GC方法结合大型语言模型与算术编码,有效提升无损梯度压缩的效率与兼容性。
原文标题:【NeurIPS2024】作为零样本无损梯度压缩器的语言模型:走向通用神经参数先验模型
原文作者:数据派THU
冷月清谈:
本文介绍了一种新方法LM-GC,将大型语言模型(LLMs)与算术编码相结合,旨在解决无损梯度压缩中的统计建模问题。在分布式学习中,梯度的高维结构及其复杂性使得有效建模充满挑战。本研究展示,LLMs能在零样本设置下作为梯度先验,实现普通梯度的文本化格式转换,并提高符号效率。实验表明,LM-GC在多个数据集上增强了压缩率10%-17.2%,超越现有方法,同时显示了与量化和稀疏化等有损压缩技术的兼容性,强调了LLMs在梯度处理中的潜力。
怜星夜思:
1、LLMs在其他领域的潜在应用有哪些?
2、如何提升梯度压缩的效率?
3、无损压缩在分布式学习中的重要性是否被低估?
2、如何提升梯度压缩的效率?
3、无损压缩在分布式学习中的重要性是否被低估?
原文内容

来源:专知本文为论文介绍,建议阅读5分钟
我们引入了一种新的方法 LM-GC,它将 LLMs 与算术编码结合。

尽管统计先验模型在各个领域得到了广泛应用,但对于神经网络梯度的此类模型长期以来却被忽视。其固有的挑战在于高维结构和复杂的相互依赖性,使得有效建模变得复杂。在本研究中,我们展示了大型语言模型(LLMs)在零样本设置中作为梯度先验的潜力。我们通过考虑无损梯度压缩这一分布式学习中的关键应用来检验这一特性,该应用高度依赖于精确的概率建模。为此,我们引入了一种新的方法 LM-GC,它将 LLMs 与算术编码结合。我们的方法将普通梯度转换为类似文本的格式,相比原始表示,令符效率提高了多达 38 倍。我们确保这种数据转换与普通梯度的结构以及 LLMs 通常识别的符号保持紧密一致。实验表明,LM-GC 超越了现有的最先进的无损压缩方法,在各种数据集和架构中压缩率提升了 10% 到 17.2%。此外,我们的方法与有损压缩技术(如量化和稀疏化)表现出良好的兼容性。这些研究结果突显了 LLMs 在有效处理梯度方面的巨大潜力。源码将在论文发表后发布。