本文综述了无标签数据集图文跨模态检索的研究进展和面临的挑战。
原文标题:实值无标签图文跨模态检索研究综述
原文作者:数据派THU
冷月清谈:
跨模态检索是根据一种模态的查询,从另一种模态中检索相关样本的技术。尽管现有研究已在这一领域获得了重要进展,依然存在一些关键问题亟待解决。本文分析了基于实值特征的图像文本跨模态检索方法的发展现状,采用基于时间复杂度的分类法将方法分为基于特征和基于分数两类,逐一探讨它们的研究现状及存在的问题。此外,通过引入主流数据集和评价指标,对这两类方法在公开数据集上的表现进行了比较分析。研究结果表明,跨模态检索虽然有了显著进步,但在技术层面上还有许多值得探索的方向和待解决的关键问题,这些问题将成为未来跨模态检索发展的重要切入点。
怜星夜思:
1、目前跨模态检索的关键问题有哪些?
2、未来跨模态检索技术有哪些可能的发展方向?
3、有无实例或应用场景能说明跨模态检索的价值?
2、未来跨模态检索技术有哪些可能的发展方向?
3、有无实例或应用场景能说明跨模态检索的价值?
原文内容

来源:专知本文约500字,建议阅读5分钟现有跨模态检索方法尽管已经取得了显著进展,但仍有一些关键问题亟待解决。

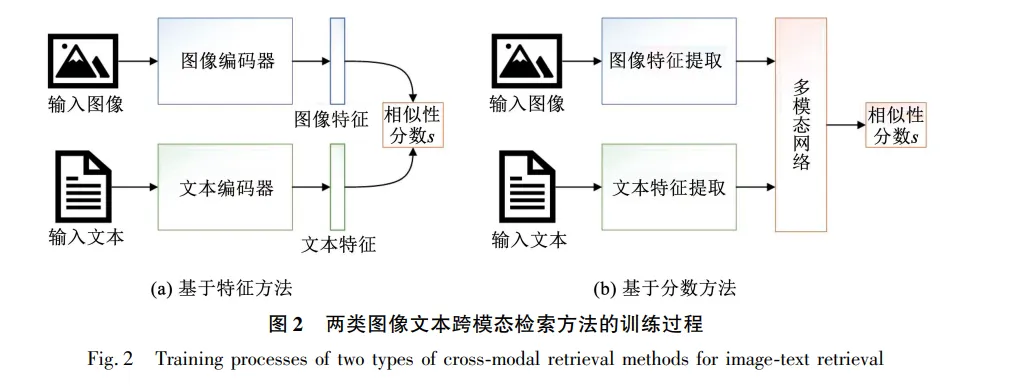
为研究面向无标签数据集基于实值特征的图像文本跨模态检索(以下简称跨模态检索)方法的发展现状和亟待解决的关键问题,对目前该领域的文献进行了分析与总结。跨模态检索是根据给定的一种模态查询,从另一种模态中检索出与查询相关的样本。首先,引入基于时间复杂度分类法,将现有跨模态检索方法分为基于特征方法和基于分数方法;其次,分别对以上两类方法的研究现状进行叙述,并针对两类方法现阶段存在的主要问题进行分析和讨论;然后,引入跨模态检索的两个主流数据集和常用评价指标,分别对两类方法在公开数据集上的性能进行比较与分析;最后,总结了跨模态检索领域亟待解决的关键问题。研究表明,现有跨模态检索方法尽管已经取得了显著进展,但仍有一些关键问题亟待解决,这些关键问题是未来跨模态检索领域的重要发展方向。