介绍文生视频DiT模型Latte的一键部署方法,助力影视动画等领域的应用。
原文标题:在线教程丨与 Sora 技术路线相似!全球首个开源文生视频 DiT 模型 Latte 一键部署
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、Latte的使用过程中,有哪些可能遇到的技术问题?
3、对于没有高端计算资源的用户,你有什么建议?
原文内容

本文约1700字,建议阅读5分钟
本文教你如何一键部署”开源 Sora“。

上海人工智能实验室开源了全球首个文生视频 DiT—— Latte,作为一款与 Sora 技术相似的自研模型,Latte 可以自由部署,应用于影视动画制作、游戏开发和广告设计等领域,对于想要探索文生视频技术的小伙伴来说,开源的 Latte 无疑为大家提供了可供实践的机会。
自 OpenAI 推出 Sora 以来,「文生视频」概念及相关应用备受瞩目。而伴随 Sora 的大热,其背后的关键技术,DiT (Diffusion Transformers) 也被「考古挖掘」了出来。

事实上,DiT 是一个文生图模型,该模型于两年前开源,其研发人员分别是 Peebles 和谢赛宁,其中 Peebles 也是 Sora 的项目领导者之一。
在 DiT 模型提出之前,Transformer 以其强大的特征提取和上下文理解能力,几乎在自然语言处理领域独霸一方。而 U-Net 则以其独特架构和优越的性能,在图像生成和扩散模型领域占据主导地位。DiT 最大的特点是把扩散模型里的 U-Net 架构换成了 Transformer 架构。有趣的是,这项工作成果在 2023 年曾被 CVPR 拒稿,理由是缺乏创新点。
与 U-Net 相比,Transformer 具有更好的拓展性,它能够学习全局依赖关系,通过自注意力机制 (Self-Attention Mechanism) 处理序列数据中的长距离依赖问题,在处理图像全局特征方面有很大的优势。此外,基于 Transformer 架构的 DiT 在计算效率和生成效果上也有明显的提升,进一步推动了图像生成的规模化应用。
然而,由于视频数据的高度结构化与复杂性,如何将 DiT 扩展到视频生成领域却是一个挑战。对此,来自上海人工智能实验室的研究团队在 2023 年底便开源了全球首个文生视频 DiT:Latte。作为一款与 Sora 技术相似的自研模型,Latte 可以自由部署,对于想要探索文生视频技术的小伙伴来说,开源的 Latte 无疑为大家提供了实践的机会。
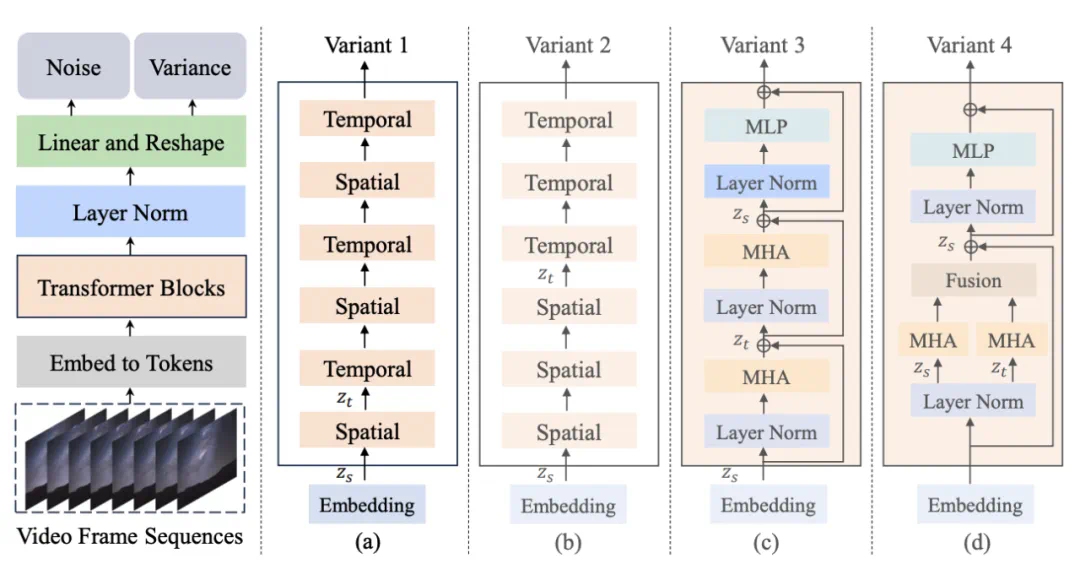
首先,Latte 通过预训练的变分自编码器 (VAE) 将输入视频编码为潜在空间中的特征,并从中提取出 Tokens 。接着,利用上述某种变体中对应的 Transformer 结构对这些 Tokens 进行编码和解码。在生成过程,模型会依据学习到的反向扩散过程,在潜在空间中逐步还原出低噪声的视频帧表示,并最终重构为连续、逼真的视频内容。
值得注意的是,Latte 的背后的研发团队上海人工智能实验室曾联合中央广播电视总台,共同推出了首部中国原创文生视频 AI 系列动画《千秋诗颂》,并在 CCTV-1 综合频道上播出。业内人士分析,随着国内首部 AI 动画的开播,我国文生视频应用的落地有望加速,未来可能会重新塑造影视行业的制作流程,推动影视动画制作、游戏开发和广告设计的革命性发展。
在此背景下,为了帮助更多创意工作者和文生视频爱好者紧跟技术潮流,HyperAI超神经上线了「Latte 全球首个开源文生视频 DiT」教程,该教程为大家搭建好了环境,无需再等待模型下载训练,点击克隆即可一键启动,输入文本即时生成视频!
小编用文本「a dog with sunglasses」生成了一个戴墨镜的小狗视频,还挺帅气的!

Demo 运行
1. 登录 hyper.ai,在「教程」页面,选择「Latte 全球首个开源文生视频 DiT」,点击「在线运行此教程」。
2. 页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
3. 点击右下角「下一步:选择算力」。
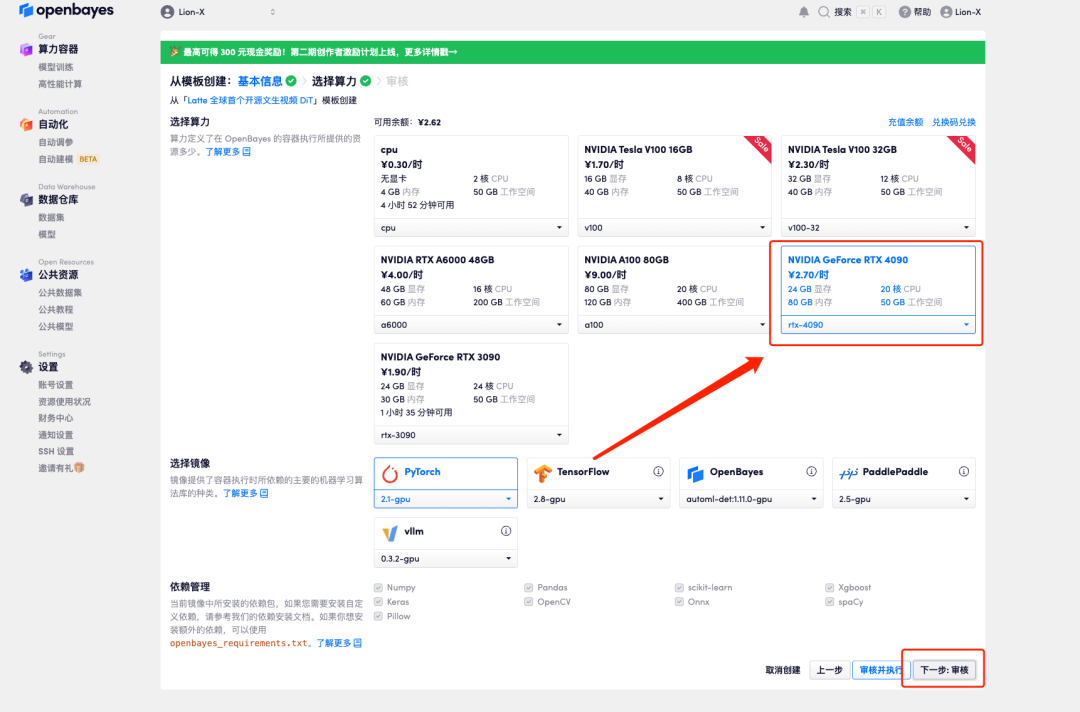
4. 跳转后,选择「NVIDIA GeForce RTX 4090」,点击「下一步:审核」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
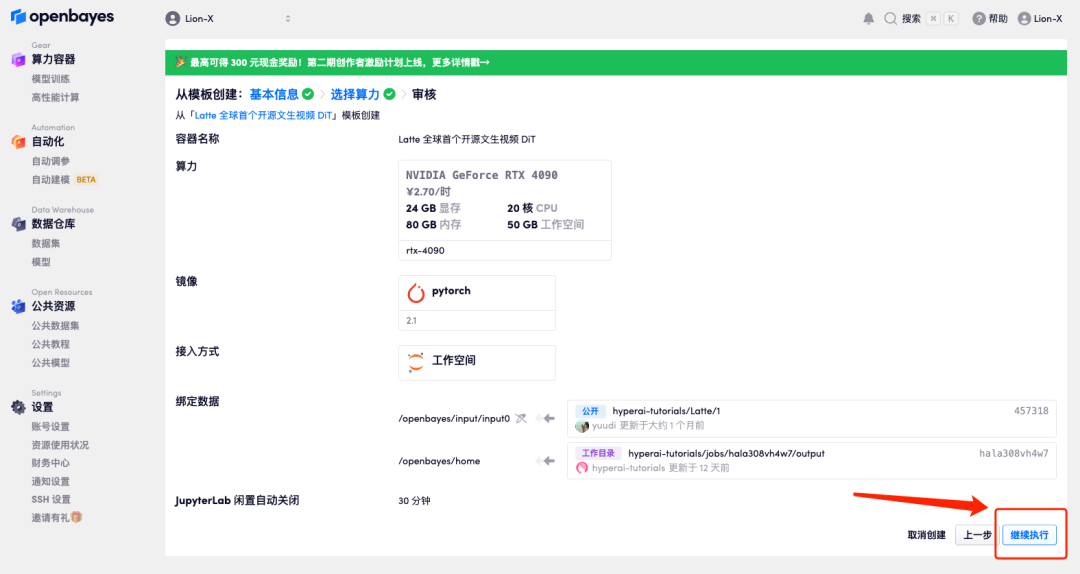
5. 点击「继续执行」,等待分配资源,首次克隆需等待 3-5 分钟左右的时间。当状态变为「运行中」后,点击「打开工作空间」。
若超过 10 分钟仍处于「正在分配资源」状态,可尝试停止并重启容器;若重启仍无法解决,请在官网联系平台客服。
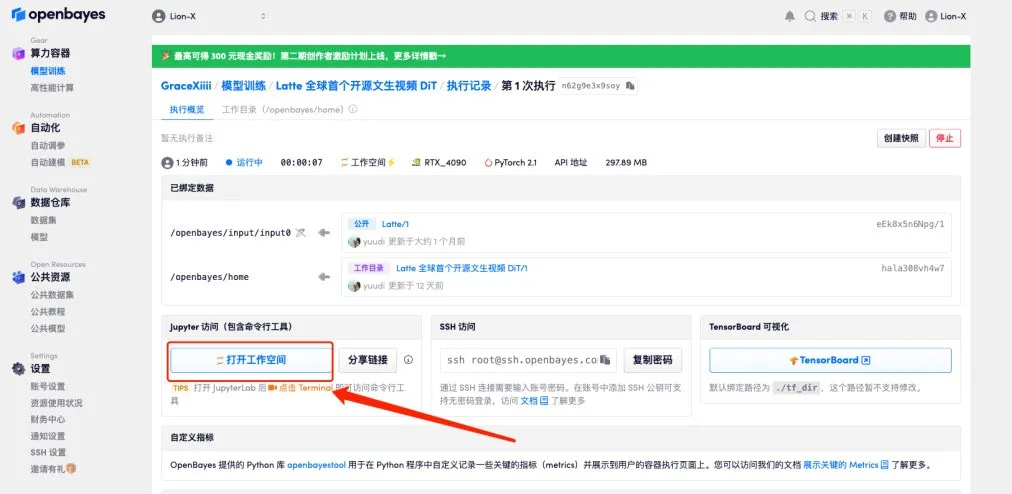
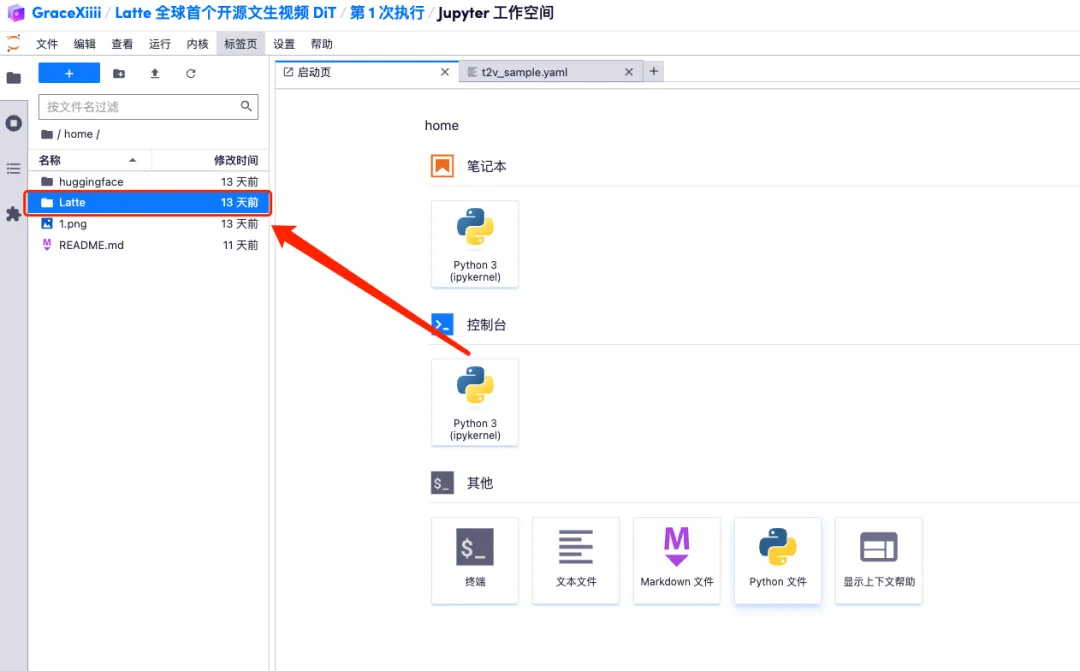
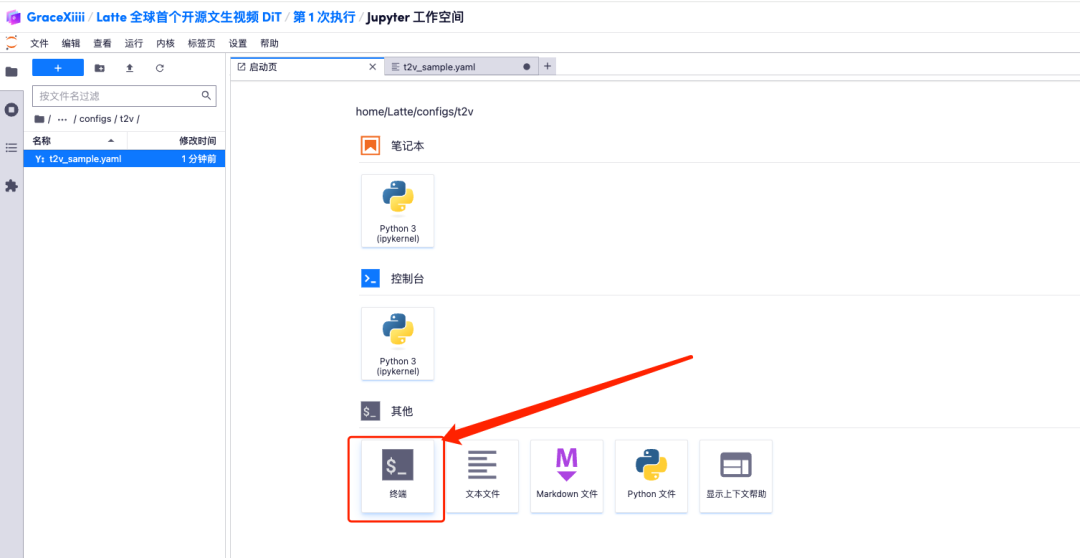
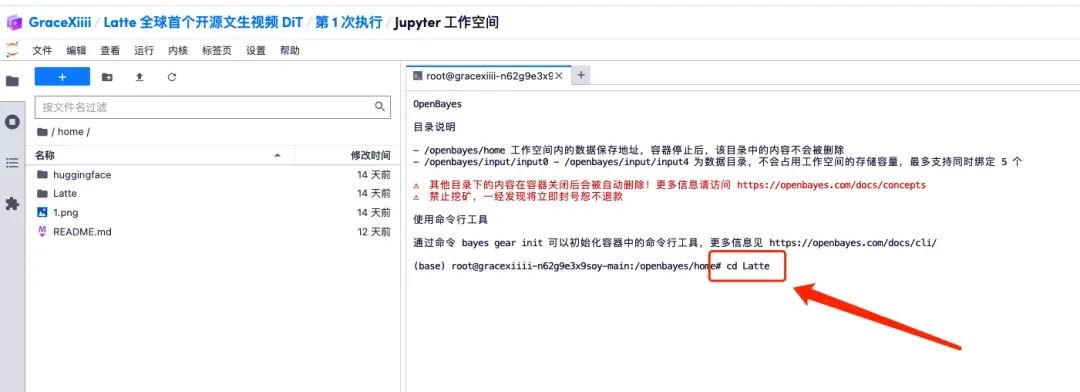
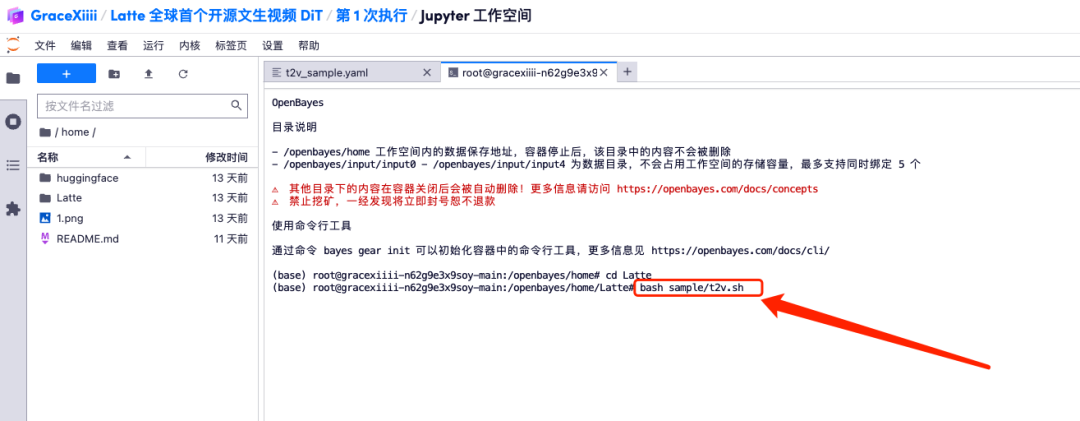
7. 保存后,新建一个终端页面,输入「cd Latte」并按下回车键后进入「Latte」目录。输入「bash sample/t2v.sh」即可生成高清视频。
效果展示
1.当进度条显示 100% 后,打开左侧菜单栏「Latte/sample_videos」,找到我们生成的视频,点击右键下载。请注意,MP4 视频无法直接观看,需要下载后才可观看。
2. 一个小狗戴墨镜的视频就生成啦!
目前,HyperAI超神经官网已上线了数百个精选的机器学习相关教程,并整理成 Jupyter Notebook 的形式。
编辑:于腾凯
校对:林亦霖
