本文介绍了用Python实现多分类支持向量机(SVM)的详细过程和代码示例,帮助读者全面理解该算法的应用。
原文标题:使用Python从零实现多分类SVM
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、如何选择支持向量机的核函数?
3、多分类支持向量机相比二分类有什么特别之处?
原文内容

来源:Deephub Imba本文约4500字,建议阅读7分钟本文将首先简要概述支持向量机及其训练和推理方程,然后将其转换为代码以开发支持向量机模型。
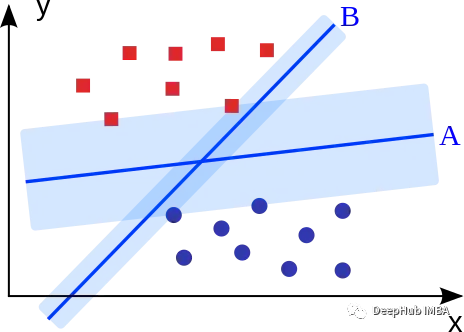
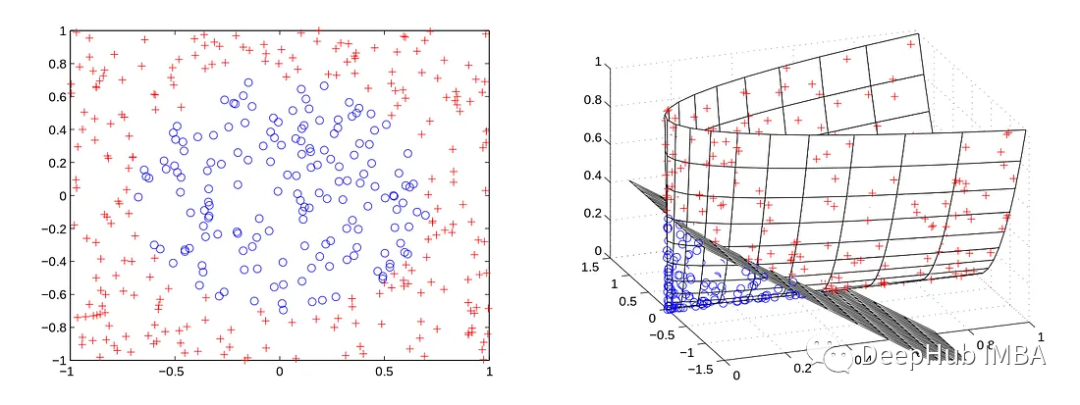
SVM概述

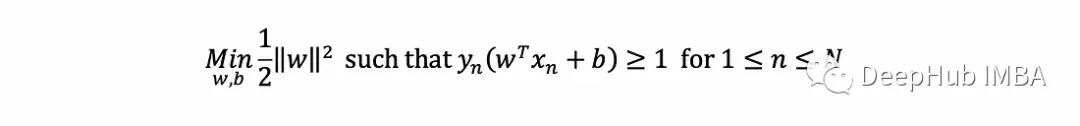
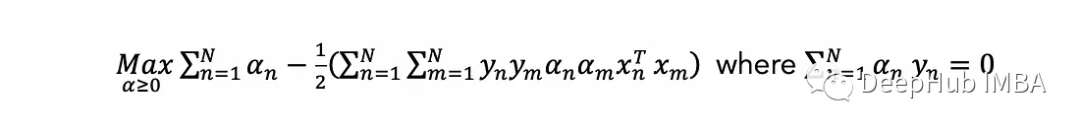
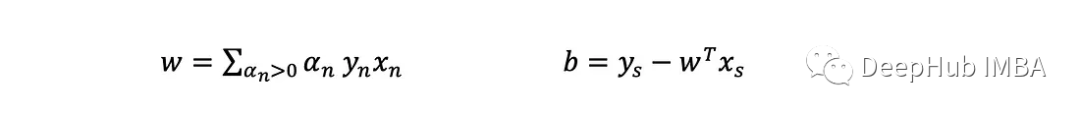
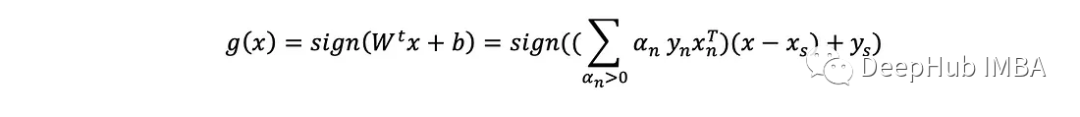
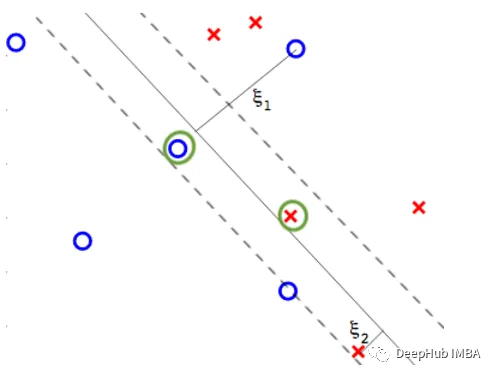
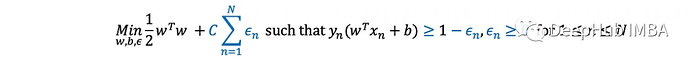
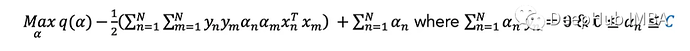
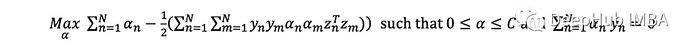
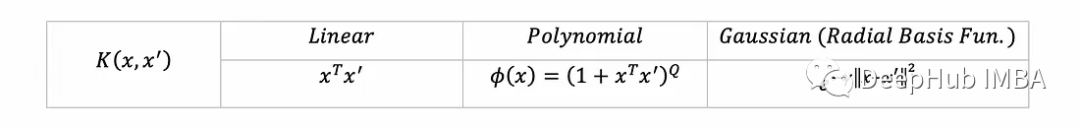
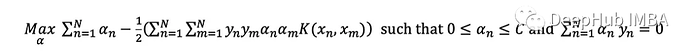
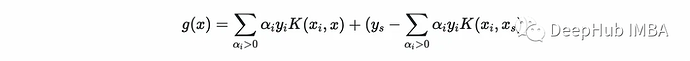
Python实现
对于实现,我们将使用下面这些库:
import numpy as np # for basic operations over arrays
from scipy.spatial import distance # to compute the Gaussian kernel
import cvxopt # to solve the dual opt. problem
import copy # to copy numpy arrays
class SVM: linear = lambda x, xࠤ , c=0: x @ xࠤ.T polynomial = lambda x, xࠤ , Q=5: (1 + x @ xࠤ.T)**Q rbf = lambda x, xࠤ, γ=10: np.exp(-γ*distance.cdist(x, xࠤ,'sqeuclidean')) kernel_funs = {'linear': linear, 'polynomial': polynomial, 'rbf': rbf}
class SVM: linear = lambda x, xࠤ , c=0: x @ xࠤ.T polynomial = lambda x, xࠤ , Q=5: (1 + x @ xࠤ.T)**Q rbf = lambda x, xࠤ, γ=10: np.exp(-γ*distance.cdist(x, xࠤ,'sqeuclidean')) kernel_funs = {'linear': linear, 'polynomial': polynomial, 'rbf': rbf}def init(self, kernel=‘rbf’, C=1, k=2):
set the hyperparameters
self.kernel_str = kernel
self.kernel = SVM.kernel_funs[kernel]
self.C = C # regularization parameter
self.k = k # kernel parametertraining data and support vectors (set later)
self.X, y = None, None
self.αs = Nonefor multi-class classification (set later)
self.multiclass = False
self.clfs =
SVMClass = lambda func: setattr(SVM, func.__name__, func) or func
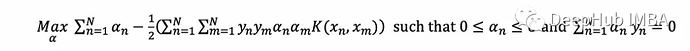
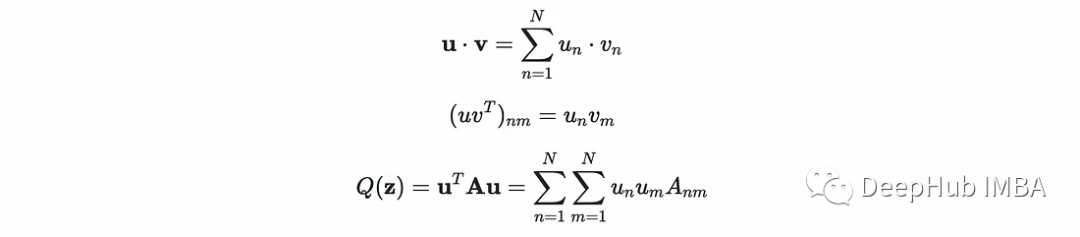
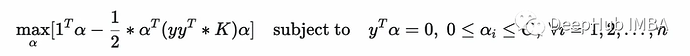


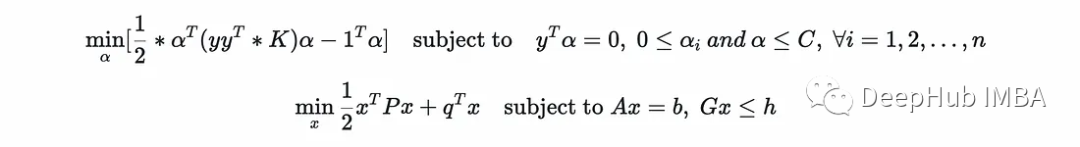

@SVMClass def fit(self, X, y, eval_train=False): # if more than two unique labels, call the multiclass version if len(np.unique(y)) > 2: self.multiclass = True return self.multi_fit(X, y, eval_train)if labels given in {0,1} change it to {-1,1}
if set(np.unique(y)) == {0, 1}: y[y == 0] = -1
ensure y is a Nx1 column vector (needed by CVXOPT)
self.y = y.reshape(-1, 1).astype(np.double) # Has to be a column vector
self.X = X
N = X.shape[0] # Number of pointscompute the kernel over all possible pairs of (x, x’) in the data
by Numpy’s vectorization this yields the matrix K
self.K = self.kernel(X, X, self.k)
Set up optimization parameters
For 1/2 x^T P x + q^T x
P = cvxopt.matrix(self.y @ self.y.T * self.K)
q = cvxopt.matrix(-np.ones((N, 1)))For Ax = b
A = cvxopt.matrix(self.y.T)
b = cvxopt.matrix(np.zeros(1))For Gx <= h
G = cvxopt.matrix(np.vstack((-np.identity(N),
np.identity(N))))
h = cvxopt.matrix(np.vstack((np.zeros((N,1)),
np.ones((N,1)) * self.C)))Solve
cvxopt.solvers.options[‘show_progress’] = False
sol = cvxopt.solvers.qp(P, q, G, h, A, b)
self.αs = np.array(sol[“x”]) # our solutiona Boolean array that flags points which are support vectors
self.is_sv = ((self.αs-1e-3 > 0)&(self.αs <= self.C)).squeeze()
an index of some margin support vector
self.margin_sv = np.argmax((0 < self.αs-1e-3)&(self.αs < self.C-1e-3))
if eval_train:
print(f"Finished training with accuracy{self.evaluate(X, y)}")
@SVMClass def predict(self, X_t): if self.multiclass: return self.multi_predict(X_t) # compute (xₛ, yₛ) xₛ, yₛ = self.X[self.margin_sv, np.newaxis], self.y[self.margin_sv] # find support vectors αs, y, X= self.αs[self.is_sv], self.y[self.is_sv], self.X[self.is_sv] # compute the second term b = yₛ - np.sum(αs * y * self.kernel(X, xₛ, self.k), axis=0) # compute the score score = np.sum(αs * y * self.kernel(X, X_t, self.k), axis=0) + b return np.sign(score).astype(int), score
@SVMClass def evaluate(self, X,y): outputs, _ = self.predict(X) accuracy = np.sum(outputs == y) / len(y) return round(accuracy, 2)
from sklearn.datasets import make_classification import numpy as npLoad the dataset
np.random.seed(1)
X, y = make_classification(n_samples=2500, n_features=5,
n_redundant=0, n_informative=5,
n_classes=2, class_sep=0.3)Test Implemented SVM
svm = SVM(kernel=‘rbf’, k=1)
svm.fit(X, y, eval_train=True)y_pred, _ = svm.predict(X)
print(f"Accuracy: {np.sum(y==y_pred)/y.shape[0]}") #0.9108Test with Scikit
from sklearn.svm import SVC
clf = SVC(kernel=‘rbf’, C=1, gamma=1)
clf.fit(X, y)
y_pred = clf.predict(X)
print(f"Accuracy: {sum(y==y_pred)/y.shape[0]}") #0.9108
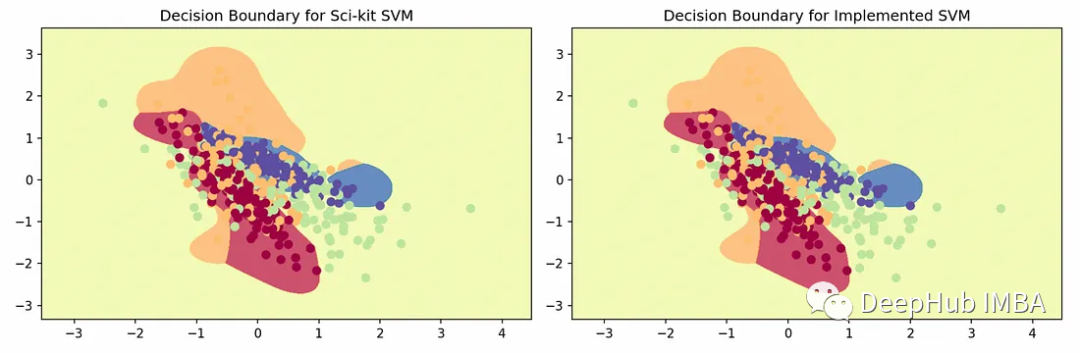
多分类SVM
@SVMClass def multi_fit(self, X, y, eval_train=False): self.k = len(np.unique(y)) # number of classes # for each pair of classes for i in range(self.k): # get the data for the pair Xs, Ys = X, copy.copy(y) # change the labels to -1 and 1 Ys[Ys!=i], Ys[Ys==i] = -1, +1 # fit the classifier clf = SVM(kernel=self.kernel_str, C=self.C, k=self.k) clf.fit(Xs, Ys) # save the classifier self.clfs.append(clf) if eval_train: print(f"Finished training with accuracy {self.evaluate(X, y)}")
@SVMClass def multi_predict(self, X): # get the predictions from all classifiers N = X.shape[0] preds = np.zeros((N, self.k)) for i, clf in enumerate(self.clfs): _, preds[:, i] = clf.predict(X)get the argmax and the corresponding score
return np.argmax(preds, axis=1), np.max(preds, axis=1)
from sklearn.datasets import make_classification import numpy as npLoad the dataset
np.random.seed(1)
X, y = make_classification(n_samples=500, n_features=2,
n_redundant=0, n_informative=2,
n_classes=4, n_clusters_per_class=1,
class_sep=0.3)Test SVM
svm = SVM(kernel=‘rbf’, k=4)
svm.fit(X, y, eval_train=True)y_pred = svm.predict(X)
print(f"Accuracy: {np.sum(y==y_pred)/y.shape[0]}") # 0.65Test with Scikit
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVCclf = OneVsRestClassifier(SVC(kernel=‘rbf’, C=1, gamma=4)).fit(X, y)
y_pred = clf.predict(X)
print(f"Accuracy: {sum(y==y_pred)/y.shape[0]}") # 0.65