本文详细解析了损失函数在机器学习中的作用,包括MSE和MAE等不同类型损失函数的应用场景。
原文标题:独家 | 机器学习中的损失函数解释
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、损失函数在机器学习算法的优化中有何具体作用?
3、在实际应用中,如何有效应对异常值对损失函数的影响?
原文内容

作者:Barr Moses翻译:欧阳锦
校对:潘玏妤
本文约7200字,建议阅读20分钟
通过这个综合指南我们探索损失函数在机器学习中的关键作用。了解损失函数和成本函数的区别,深入研究MSE和MAE等各种类型损失函数,并了解它们在ML任务中的应用。
机器学习为计算模型提供了基于数据进行预测、分类和决策的能力。作为一个研究领域,机器学习是人工智能领域的一个子集,它封装了构建具有模仿人类智能甚至在某些情况下超越人类智能的能力的计算模型所涉及的过程。
机器学习及相关算法和技术从根本上涉及设计、实现和训练算法,以识别数据中的模式并执行预测或分类。
机器学习算法通过不同的方法进行学习,但机器学习算法和模型的学习过程的一个基本组成部分是损失函数。损失函数是一个用于量化模型预测与实际目标值之间的误差幅度的数学过程。接下来,我们将详细探讨损失函数。
损失函数简介
损失函数是衡量机器学习模型性能和准确性的可测量方法。在这种情况下,损失函数充当模型或机器学习算法中学习过程的指南。
损失函数在机器学习模型的训练中的作用至关重要,包括以下内容:
-
性能测量:损失函数通过量化预测与实际结果之间的差异,提供了一个明确的指标来评估模型的性能。
-
改进方向:损失函数通过指导算法迭代调整参数(权重)来指导模型改进,以减少损失并改进预测。
-
平衡偏差和方差:有效的损失函数有助于平衡模型偏差(过度简化)和方差(过度拟合),这对于模型泛化到新数据至关重要。
-
影响模型行为:某些损失函数可能会影响模型的行为,例如对数据异常值更加稳健或优先处理特定类型的错误。
让我们在后面的部分中探讨特定损失函数的作用,并建立对损失函数的详细理解。
什么是损失函数?
损失函数,也称为误差函数(error function),是机器学习中的重要组成部分,它量化机器学习算法的预测输出与实际目标值之间的差异。例如,在基于历史数据预测汽车价格的回归问题中,损失函数基于训练数据集中的训练样本来评估神经网络预测。损失函数量化了网络预测的汽车价格与实际价格的差距或误差幅度。
所得值(损失,loss)反映了模型预测的准确性。在训练过程中,反向传播算法等学习算法利用损失函数相对于模型参数的梯度来调整这些参数并最小化损失,有效提高模型在数据集上的性能。
通常,术语“损失函数”(loss function)和“成本函数”(cost function)可以互换使用。尽管如此,这两个术语都有不同的定义:
如前所述,损失函数也称为误差函数,它量化了机器学习算法的单个预测与实际目标值相比的好坏程度。关键要点是,损失函数适用于单个训练示例,并且是整个模型学习过程的一部分,该过程提供模型学习算法更新权重和参数的信号。
成本函数,有时称为目标函数(objective function),是包含多个训练样本的整个训练集的损失函数的平均值。成本函数量化模型在整个训练数据集上的性能。
让我们更深入地研究损失函数是如何工作的。
![]()
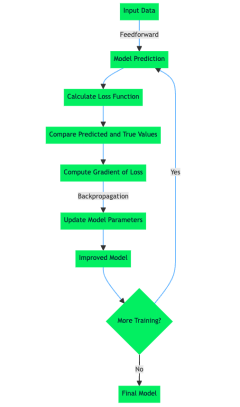
损失函数如何工作
尽管损失函数有不同类型,但从根本上来说,它们都是通过量化模式预测与数据集中实际目标值之间的差异来运行的。这种数值量化的官方术语是预测误差。机器学习模型中的学习算法和机制经过优化以最小化预测误差,因此这意味着在计算出由预测误差确定的损失函数值后,学习算法利用该信息来进行权重计算。在下一次训练过程中有效的参数更新会导致较低的预测误差。
在探索损失函数、机器学习算法和神经网络中的学习过程的主题时,会出现经验风险最小化(ERM)的主题。ERM 是一种选择机器学习算法最佳参数的方法,可最大限度地降低经验风险。在这种情况下,经验风险是训练数据集。
ERM 的风险最小化组件是内部学习算法最小化机器学习算法对已知数据集的预测误差的过程,结果是模型在未见过的数据集或数据样本的情况下具有预期的性能和准确性它可能具有与模型最初训练的数据集类似的静态数据分布。
![]()
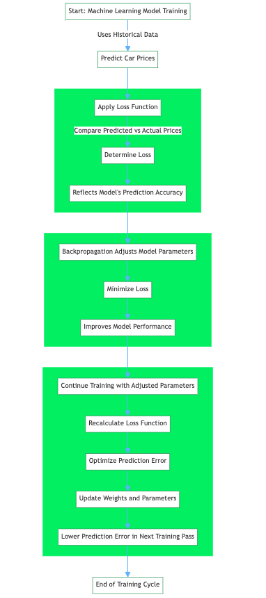
损失函数的类型
机器学习中的损失函数可以根据其适用的机器学习任务进行分类。大多数损失函数适用于回归和分类机器学习问题:该模型有望预测回归机器学习任务的连续输出值;相反,该模型有望为分类任务提供与数据集类别相对应的离散标签。
以下是标准损失函数及其对机器学习问题的分类。本文稍后将详细介绍大多数损失函数。
|
损失函数 |
分类任务的适用性 |
回归任务的适用性 |
|
Mean Square Error (MSE) / L2 Loss |
否 |
是 |
|
Mean Absolute Error (MAE) / L1 Loss |
否 |
是 |
|
Binary Cross-Entropy Loss / Log Loss |
是 |
否 |
|
Categorical Cross-Entropy Loss |
是 |
否 |
|
Hinge Loss |
是 |
否 |
|
Huber Loss / Smooth Mean Absolute Error |
否 |
是 |
|
Log Loss |
是 |
否 |
回归的损失函数
均方误差 (MSE) / L2损失
均方误差 (MSE) 或L2损失是一种损失函数,通过取预测值与目标值之间的平方差的平均值来量化机器学习算法预测与实际输出之间的误差大小。将预测值与实际目标值之间的差异进行平方会导致对与目标值的较大偏差分配更高的惩罚。误差平均值根据数据集或观察中的样本数量标准化总误差。
均方误差 (MSE) 或L2损失的数学方程为:
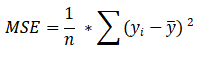

何时使用MSE
了解何时使用MSE对于机器学习模型开发至关重要。MSE是大多数回归任务中使用的标准损失函数,因为它指导模型进行优化以最小化预测值和目标值之间的平方差。
建议将MSE用于ML场景,因为它有利于学习过程,从而显着惩罚异常值的存在。然而,MSE的这些特征并不总是适合异常值是由数据噪声而非正信号引起的场景和用例。
利用MSE损失函数的一个示例场景是房地产价格预测,或更广泛地说,预测建模。预测房价涉及使用房间数量、位置、面积、距便利设施的距离和其他数字特征等特征。局部区域的房价呈正态分布,因此惩罚异常值的目标对于模型准确预测房价的能力至关重要。
房地产中的一个小百分比误差就可能相当于一大笔钱。例如,价值200,000美元的房子 5%的误差就是10,000美元,这是相当大的。因此,对误差进行平方(如MSE中所做的那样)有助于为较大的误差赋予更高的权重,从而使模型更加精确,具有更高价值的属性。
平均绝对误差 (MAE) / L1损失
平均绝对误差 (MAE),也称为L1损失,是回归任务中使用的损失函数,用于计算机器学习模型的预测值与实际目标值之间的平均绝对差。与均方误差 (MSE) 不同,MAE不会对差值进行平方,而是以相同的权重对待所有误差,无论其大小如何。
平均绝对误差 (MAE) 或L1损失的数学方程为:
![]()
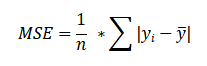

何时使用MAE
从上一部分中我们已经知道:MAE衡量预测值与实际值之间的平均绝对差。与MSE不同,MAE不会对差异进行平方,这使得它对异常值不太敏感。与均方误差 (MSE) 相比,平均绝对误差 (MAE) 本质上对异常值不太敏感,因为它为所有误差分配相同的权重,无论其大小如何。
这意味着,虽然异常值在平方时会产生不成比例的大误差,从而显着扭曲MSE,但它对MAE的影响要小得多。当使用MAE作为损失函数时,异常值对整体误差指标的影响很小。相比之下,MSE由于误差项的平方而放大了异常值的影响,从而更显着地影响模型的误差估计。
MAE是一种适用于我们不想太幅或根本不惩罚异常值场景的损失函数,例如,预测食品配送公司的配送时间。
UberEats、Deliveroo或DoorDash等配送服务公司可能会构建配送估算模型来提高客户满意度。送货服务送餐所需的时间受到天气、交通事故、道路施工等多种因素的影响。
处理这些因素对于估计交货时间至关重要。处理此问题的一种方法是将这些事件分类为异常值,但做出决定以确保它不会影响正在训练的模型。MAE是这种情况下合适的损失函数,因为它将处理由于道路施工或严重程度较低的罕见事件而导致的异常值数据点,从而减少异常值对误差指标和模型学习过程的影响。
MAE特别为所有数据点添加了统一的误差权重;在所描述的场景中,惩罚异常数据点可能会导致高估或低估交付时间。
Huber Loss / 平滑MAE
Huber Loss或平滑MAE是同一种损失函数,它采用了平均绝对误差和均方误差损失函数的有利特征,并将它们组合成单个损失函数。Huber Loss的混合性质使其对异常值不太敏感,就像MAE一样,但也会惩罚数据样本中的微小错误,类似于MSE。Huber Loss函数也用于回归机器学习任务。
Huber Loss的数学方程如下:
![]()
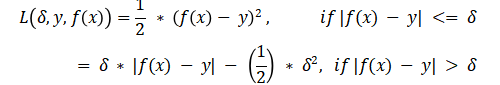

何时使用Huber Loss / 平滑平均绝对误差
Huber Loss函数有效地结合了两个组件,以不同的方式处理错误,这些组件之间的过渡点由阈值![]() 确定:
确定:

Huber Loss以两种模式运行,根据计算出的实际目标值与机器学习算法的预测之间的差异大小进行切换。Huber Loss中的关键术语是delta (![]() )。Delta是一个阈值,它决定了Huber Loss使用二次损失应用还是线性计算的数值边界。Huber Loss的二次分量表示了 MSE惩罚异常值的优势;在Huber Loss中,这适用于小于等
)。Delta是一个阈值,它决定了Huber Loss使用二次损失应用还是线性计算的数值边界。Huber Loss的二次分量表示了 MSE惩罚异常值的优势;在Huber Loss中,这适用于小于等![]()
![]() 的误差,这确保了模型的预测更准确。
的误差,这确保了模型的预测更准确。
假设计算出的误差,即实际值与预测值之间的差异,大于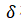 值。在这种情况下,Huber Loss使用类似于MAE的线性损失计算方式,这种方式对误差大小的敏感性较低,以确保训练模型不会对大误差过度惩罚,特别是当数据集包含异常值或不太可能出现的数据样本时。
值。在这种情况下,Huber Loss使用类似于MAE的线性损失计算方式,这种方式对误差大小的敏感性较低,以确保训练模型不会对大误差过度惩罚,特别是当数据集包含异常值或不太可能出现的数据样本时。
分类损失函数
二元交叉熵损失/对数损失
二元交叉熵损失 (BCE) 是分类模型的性能度量,它输出概率值通常在0到1之间的预测,该预测值对应于数据样本属于某个类或类别的可能性。在二元交叉熵损失的情况下,有两个不同的类别。但值得注意的是,交叉熵损失的一种变体分类交叉熵适用于多类分类场景。
要理解二元交叉熵损失(有时称为对数损失),讨论以下术语会很有帮助。
-
损失:这是机器学习算法的预测与实际目标值之间的裕度/差异的数学量化;
-
熵:熵的简单定义是它是系统内随机性或无序程度的计算;
-
交叉熵:这是信息论中常用的术语,它测量可用于识别观察结果的两个概率分布之间的差异;
-
二元:这是使用两种状态(0或1)的数字表达。这被扩展到二进制分类的定义,其中我们使用二进制表示法区分两个类(A和B),其中A类被分配0的数字表示,B类分配为1。
二元交叉熵损失(或对数损失)是一种量化指标,用来衡量机器学习算法的预测与实际目标预测之间的差异。这种差异是通过计算机器学习算法对总数据样本数所作预测概率的对数值的负和来计算的。BCE存在于逻辑回归问题的机器学习用例中,以及训练旨在预测数据样本属于某个类别的可能性并在内部利用sigmoid 激活函数的人工神经网络中。
二元交叉熵损失(也称为对数损失)的数学方程为:
![]()
![]()

何时使用二元交叉熵损失/对数损失
上面的等式特别适用于机器学习算法在两个类别之间进行分类的场景。这是一个二元分类场景。
正如等式中的负号所示:‘-’,BCE 通过确定两项的负值来计算损失,并且对于多个预测或数据样本,计算以下两项的负值的平均值:
1. 模型预测出现正类的概率的对数![]()
2. 1的对数减去负类的预测概率:![]()
二元交叉熵损失函数(BCE)会对不准确的预测进行惩罚,特别是对于与正类差异显著的预测,或者说,对于熵的量化值较高的预测。当BCE作为学习算法中的一个组成部分时,它鼓励模型在训练过程中细化其预测,即对适当类别的概率进行调整。
铰链损失Hinge Loss
Hinge Loss是一种在机器学习中用来训练分类器的损失函数,它旨在优化增加数据点与决策边界之间的间隔,因此主要用于最大间隔(maximum margin)分类。为了确保数据点与边界之间的最大间隔,铰链损失会对机器学习模型中被错误分类的预测进行惩罚,这些错误分类的预测是指落在间隔边界(margin boundary)错误一侧的预测,以及虽然被正确分类但与决策边界过近的预测。
铰链损失函数的这一特性确保机器学习模型能够以超过决策边界阈值的置信度将数据点准确分类到其目标值。这种机器算法学习方法增强了模型的泛化能力,使其能够有效地以高度确定性对数据点进行准确分类。
Hinge Loss的数学方程为:
![]()

选择正确的损失函数
选择适当的损失函数应用于机器学习算法至关重要,因为模型的性能在很大程度上取决于算法学习或调整其内部权重以适应数据集的能力。
机器学习模型或算法的性能由所使用的损失函数定义,主要是因为损失函数组件影响用于最小化模型的错误损失或成本函数值的学习算法。从本质上讲,损失函数会影响模型学习和调整其内部权重值以适应数据集中的模式的能力。
如果选择得当,损失函数使学习算法能够在训练阶段有效地收敛到最佳损失,并很好地推广到未见过的数据样本。适当选择的损失函数可以作为指导,引导学习算法走向准确性和可靠性,确保它捕获数据中的潜在模式,同时避免过度拟合或欠拟合。
选择损失函数时要考虑的因素
了解当前机器学习问题的类型有助于确定要使用的损失函数的类别。不同的损失函数适用于各种机器学习问题。
分类与回归
分类机器学习任务通常涉及将数据点分配给特定类别标签。对于此类机器学习任务,机器学习模型的输出通常是一组概率,用于确定数据点作为特定标签的可能性。
交叉熵损失函数通常用于分类任务。在机器学习回归任务中,目标是让机器学习模型根据一组输入生成预测,因此均方误差MSE或平均绝对误差MAE等损失函数更适合。
二元分类与多类分类
二元分类涉及将数据样本分类为两个不同的类别,而多类分类,顾名思义是涉及将数据样本分类为两个以上类别。对于仅涉及两个类别(二元分类)的机器学习分类问题,最好利用二元交叉熵损失函数。在超过两个类别作为预测目标的情况下,应使用分类交叉熵。
灵敏度
另一个需要考虑的因素是损失函数对异常值的敏感性。在某些情况下,需要确保在训练过程中对偏离数据集整体统计分布的异常值和数据样本进行惩罚;在这种情况下,均方误差MSE等损失函数是合适的。
虽然在某些情况下需要对异常值不太敏感,但在这些情况下,异常值可能“永远不会发生”或不太可能发生。为了这个目标,惩罚异常值可能会产生一个性能不佳的模型。平均绝对误差MAE等损失函数就适用于此类场景。为了两全其美,使用者也应该考虑 Huber Loss函数,该函数同时具有惩罚具有低误差值的异常值,并降低模型对具有大误差值异常值的敏感性的特点。
计算效率
计算资源是机器学习、商业和研究领域的商品。获得大型计算能力使从业者能够灵活地试验大型数据集并解决更复杂的机器学习问题。某些损失函数比其他损失函数的计算要求更高,特别是当数据集数量很大时。这使得损失函数的计算效率成为损失函数选择过程中需要考虑的因素。
|
考虑因素 |
描述 |
|
学习问题的类型 |
分类与回归; 二元分类与多类分类。 |
|
模型对异常值的敏感性 |
一些损失函数对异常值更敏感(例如MSE),而其他损失函数则更稳健(例如MAE)。 |
|
期望的模型行为 |
影响模型的行为方式,例如,SVM中的hinge loss侧重于最大化边界。 |
|
计算效率 |
一些损失函数的计算量更大,影响基于可用资源的选择。 |
|
收敛性 |
损失函数的平滑度和凸度会影响训练的难易程度和速度。 |
|
任务规模 |
对于大规模任务,可扩展且可有效优化的损失函数至关重要。 |
异常值和数据分布的影响
异常值是指超出数据集整体统计分布的数据样本;它们有时被称为异常或违规行为。异常值的处理方式决定了训练过的机器学习模型的性能和准确性。
如前所述,数据集中的异常值会影响损失函数中使用的误差值,具体取决于所使用的损失函数。异常值对损失函数的影响会传播到机器学习算法的学习过程的结果,这可能会导致机器学习算法或模型出现有意或无意的行为。
例如,均方误差MSE会惩罚导致大误差值/项的异常值;这意味着在训练过程中,模型权重会被调整以学习如何适应这些异常值。同样,如果这不是机器学习模型的预期行为,那么训练后创建的最终模型对于未见过的数据的泛化能力会很差。对于需要减轻异常值影响的场景,MAE、Huber Loss等函数更适用。
|
损失函数 |
分类任务的适用性 |
回归任务的适用性 |
对异常值的敏感性 |
|
Mean Square Error (MSE) |
否 |
是 |
高 |
|
Mean Absolute Error (MAE) |
否 |
是 |
低 |
|
Cross-Entropy Loss |
是 |
否 |
中 |
|
Hinge Loss |
是 |
否 |
低 |
|
Huber Loss |
否 |
是 |
中 |
|
Log Loss |
是 |
否 |
中 |
实现损失函数
实现常见损失函数的示例
MAE的Python实现
# Python implementation of Mean Absolute Error (MAE)
def mean_absolute_error(actual:list, predicted:list) -> float:
"""
Calculate the Mean Absolute Error between actual and predicted values
:param actual: list, actual values
:param predicted: list, predicted values
:return: float, the calculated MAE
"""
# Ensure the length of the two lists are the same
if len(actual) != len(predicted):
raise ValueError("The length of actual values and predicted values must be the same")
# Calculate the absolute differences
absolute_diffs = [abs(act - pred) for act, pred in zip(actual, predicted)]
# Calculate the mean of the absolute differences
mae = sum(absolute_diffs) / len(actual)
return mae
# Example usage:
# actual values
y_true = [3, -0.5, 2, 7]
# predicted values
y_pred = [2.5, 0.0, 2, 8]
# Calculate MAE
mae_value = mean_absolute_error(y_true, y_pred)
print(mae_value)
# 0.5
MSE的Python实现
# Python implementation of Mean Squared Error (MSE) / L2 Loss def mean_squared_error(actual:list, predicted:list) -> float: """ Calculate the Mean Squared Error between actual and predicted values
:param actual: list, actual values
:param predicted: list ,predicted values
:return: float, the calculated MSE
“”"
# Ensure the length of the two lists are the same
if len(actual) != len(predicted):
raise ValueError(“The length of actual values and predicted values must be the same”)
# Calculate the squared differences
# (yᵢ - ȳ)²
squared_diffs = [(act - pred) ** 2 for act, pred in zip(actual, predicted)]
# Calculate the mean of the squared differences
mse = sum(squared_diffs) / len(actual)
return mse
# Example usage:
# actual values
y_true = [1, 2, 3, 4, 5]
# predicted values
y_pred = [1.1, 2.2, 2.9, 4.1, 4.9]
# Calculate MSE
mse_value = mean_squared_error(y_true, y_pred)
print(mse_value)
# 0.015999999999999993
使用库来实现损失函数
虽然损失函数的自定义实现是可行的,并且TensorFlow和PyTorch等深度学习库支持在神经网络实现中使用定制损失函数,但Scikit-learn、TensorFlow和PyTorch等库提供了常用损失函数的内置实现。
这些预先集成的功能有助于轻松利用并抽象出实现这些损失函数所涉及的复杂性,从而简化机器学习模型的开发过程。
与纯Python实现相比,使用这些深度学习库具有以下优势:
-
使用方便
-
效率和优化
-
GPU和并行计算支持
-
开发者社区支持
使用 scikit-learn 库的平均绝对误差 (MAE)
from sklearn.metrics import mean_absolute_erroractual values
y_true = [3, -0.5, 2, 7]
predicted values
y_pred = [2.5, 0.0, 2, 8]
Calculate MAE using scikit-learn
mae_value = mean_absolute_error(y_true, y_pred)
print(mae_value)
#0.5
使用 scikit-learn 库的均方误差 (MSE)
from sklearn.metrics import mean_squared_erroractual values
y_true = [1, 2, 3, 4, 5]
predicted values
y_pred = [1.1, 2.2, 2.9, 4.1, 4.9]
Calculate MSE using scikit-learn
mse_value = mean_squared_error(y_true, y_pred)
print(mse_value)0.016
结论
综上所述,选择正确的损失函数对于有效的机器学习模型训练至关重要。本文重点介绍了关键损失函数、它们在机器学习算法中的作用以及它们对不同任务的适用性。从均方误差 (MSE) 到 Huber Loss,每个函数都有其独特的优势,无论是处理异常值还是平衡偏差和方差。
决定使用Scikit-learn、TensorFlow和PyTorch等库中的自定义或预构建损失函数取决于特定的项目需求、计算效率和用户专业知识。这些库易于使用、并且带有持续的社区支持和定期更新等特点。
尽管机器学习不断发展,损失函数的重要性仍然保持不变。未来的趋势可能会带来更专业的损失函数,但基本原则可能会持续存在。要更深入地了解机器学习及其应用,请探索 DataCamp的机器学习科学家与Python课程。
译者简介

翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
