本文探讨如何通过多样本生成与比较、余弦距离及BERTScore等方法,有效检测大语言模型的幻觉现象。
原文标题:如何避免LLM的“幻觉”(Hallucination)
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、你觉得使用LLM进行自我评估的准确性如何?
3、实时幻觉检测的应用场景有哪些?
原文内容

来源:DeepHub IMBA本文约3600字,建议阅读7分钟
聊天机器人的幻觉检测一直是人们讨论已久的质量问题。
余弦距离
output = "Evelyn Hartwell is a Canadian dancer, actor, and choreographer." output_embeddings= model.encode(output)
array([ 6.09108340e-03, -8.73148292e-02, -5.30637987e-02, -4.41815751e-03,
1.45469820e-02, 4.20340300e-02, 1.99541822e-02, -7.29453489e-02,
…
-4.08893749e-02, -5.41420840e-02, 2.05906332e-02, 9.94611382e-02,
-2.24501686e-03, 2.29083393e-02, 7.80007839e-02, -9.53456461e-02],
dtype=float32)
将LLM的每个输出生成嵌入,然后使用sentence_transformers中的pairwise_cos_sim函数计算cos相似度。将原始响应与每个新样本响应进行比较,然后求平均值。
from sentence_transformers.util import pairwise_cos_sim from sentence_transformers import SentenceTransformer
def get_cos_sim(output,sampled_passages):
model = SentenceTransformer(‘all-MiniLM-L6-v2’)
sentence_embeddings = model.encode(output).reshape(1, -1)
sample1_embeddings = model.encode(sampled_passages[0]).reshape(1, -1)
sample2_embeddings = model.encode(sampled_passages[1]).reshape(1, -1)
sample3_embeddings = model.encode(sampled_passages[2]).reshape(1, -1)
cos_sim_with_sample1 = pairwise_cos_sim(
sentence_embeddings, sample1_embeddings
)
cos_sim_with_sample2 = pairwise_cos_sim(
sentence_embeddings, sample2_embeddings
)
cos_sim_with_sample3 = pairwise_cos_sim(
sentence_embeddings, sample3_embeddings
)
cos_sim_mean = (cos_sim_with_sample1 + cos_sim_with_sample2 + cos_sim_with_sample3) / 3
cos_sim_mean = cos_sim_mean.item()
return round(cos_sim_mean,2)

cos_sim_score = get_cos_sim(output, [sample1,sample2,sample3])

BERTScore

from sentence_transformers.util import pairwise_cos_sim from sentence_transformers import SentenceTransformer
def get_cos_sim(output,sampled_passages):
model = SentenceTransformer(‘all-MiniLM-L6-v2’)
sentence_embeddings = model.encode(output).reshape(1, -1)
sample1_embeddings = model.encode(sampled_passages[0]).reshape(1, -1)
sample2_embeddings = model.encode(sampled_passages[1]).reshape(1, -1)
sample3_embeddings = model.encode(sampled_passages[2]).reshape(1, -1)
cos_sim_with_sample1 = pairwise_cos_sim(
sentence_embeddings, sample1_embeddings
)
cos_sim_with_sample2 = pairwise_cos_sim(
sentence_embeddings, sample2_embeddings
)
cos_sim_with_sample3 = pairwise_cos_sim(
sentence_embeddings, sample3_embeddings
)
cos_sim_mean = (cos_sim_with_sample1 + cos_sim_with_sample2 + cos_sim_with_sample3) / 3
cos_sim_mean = cos_sim_mean.item()
return round(cos_sim_mean,2)
selfcheck_bertscore没有将完整的原始输出作为参数传递,而是将其分成单独的句子。
['Evelyn Hartwell is an American author, speaker, and life coach.',
'She is best known for her book, The Miracle of You: How to Live an Extraordinary Life, which was published in 2007.',
'She is a motivational speaker and has been featured on TV, radio, and in many magazines.',
'She has authored several books, including How to Make an Impact and The Power of Choice.']
这一步很重要,因为selfcheck_bertscore.predict函数将每个句子的BERTScore计算为与样本中每个句子匹配的原始响应。它创建一个数组,其行数等于原始输出中的句子数,列数等于样本数。
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
用于计算候选句子和参考句子之间BERTScore的模型是RoBERTa large,共17层。最初的输出有4个句子,分别是r1 r2 r3和r4。第一个样本有两个句子:c1和c2。计算原始输出中的每个句子与第一个样本中的每个句子匹配的F1 BERTScore。然后我们对基线张量b =([0.8315,0.8315,0.8312])进行缩放。基线b是使用来自Common Crawl单语数据集的100万个随机配对句子来计算的。他们计算了每一对的BERTScore,并取其平均值。这代表了一个下界,因为随机对几乎没有语义重叠。

保留原始回复中每个句子的BERTScore,并从每个抽取的样本中选择最相似的句子。其逻辑是,如果一条信息出现在由同一提示生成的多个样本中,那么该信息很有可能是真实的。如果一个语句只出现在一个示例中,而没有出现在来自同一提示的任何其他示例中,则更有可能是伪造的。
所以我们计算最大相似度:
bertscore_array
array([[0.43343216, 0. , 0. ],
[0.12838356, 0. , 0. ],
[0.2571277 , 0. , 0. ],
[0.21805632, 0. , 0. ]])
对另外两个样本重复这个过程:
array([[0.43343216, 0.34562832, 0.65371764],
[0.12838356, 0.28202596, 0.2576825 ],
[0.2571277 , 0.48610589, 0.2253703 ],
[0.21805632, 0.34698656, 0.28309497]])
然后我们计算每行的平均值,给出原始回复中每个句子与每个后续样本之间的相似度得分。
array([0.47759271, 0.22269734, 0.32286796, 0.28271262])
每句话的幻觉得分是通过从上面的每个值中减去1得到的。


NLI

下面是一些前提-假设对及其标签的例子。

def get_self_check_nli(output, sampled_passages):
# spacy sentence tokenization
sentences = [sent.text.strip() for sent in nlp(output).sents]
selfcheck_nli = SelfCheckNLI(device=mps_device) # set device to 'cuda' if GPU is available
sent_scores_nli = selfcheck_nli.predict(
sentences = sentences, # list of sentences
sampled_passages = sampled_passages, # list of sampled passages
)
df = pd.DataFrame({
'Sentence Number': range(1, len(sent_scores_nli) + 1),
'Probability of Contradiction': sent_scores_nli
})
return df
在selfcheck_nli.predict函数,原始响应中的每个句子都与三个样本中的每个配对。
logits = model(**inputs).logits # neutral is already removed
probs = torch.softmax(logits, dim=-1)
prob_ = probs[0][1].item() # prob(contradiction)

现在我们对这四个句子中的每一个重复这个过程。

可以看到,模型输出的矛盾概率非常高。现在我们将其与实际输出进行比较。

这个模特做得很好!但是NLI检查时间有点太长了。

Prompt
较新的方法已经开始使用llm本身来评估生成的文本。而不是使用公式来计算分数,我们将输出与三个样本一起发送到gpt-3.5 turbo。该模型将决定原始输出相对于生成的其他三个样本的一致性。
def llm_evaluate(sentences,sampled_passages): prompt = f"""You will be provided with a text passage \ and your task is to rate the consistency of that text to \ that of the provided context. Your answer must be only \ a number between 0.0 and 1.0 rounded to the nearest two \ decimal places where 0.0 represents no consistency and \ 1.0 represents perfect consistency and similarity. \n\n \ Text passage: {sentences}. \n\n \ Context: {sampled_passages[0]} \n\n \ {sampled_passages[1]} \n\n \ {sampled_passages[2]}."""completion = client.chat.completions.create(
model=“gpt-3.5-turbo”,
messages=[
{“role”: “system”, “content”: “”},
{“role”: “user”, “content”: prompt}
]
)
return completion.choices[0].message.content
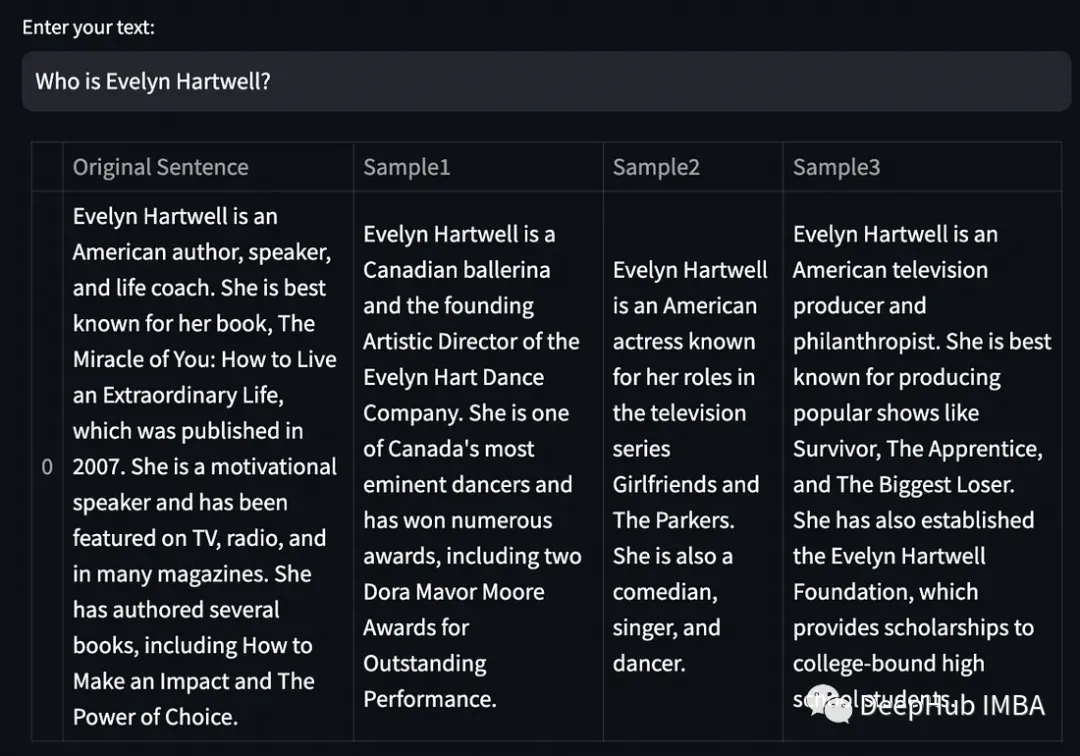
Evelyn Hartwell的自相似性得分为0。Nicolas Cage相关的输出得分为0.95。获得分数所需的时间也很低。

这似乎是案例的目前最佳解决方案,Prompt的性能明显优于所有其他方法,NLI是性能第二好的方法。

评估数据集是通过使用WikiBio数据集和GPT-3生成合成维基百科文章来创建的。为了避免模糊的概念,238篇文章的主题是从最长文章的前20%中随机抽取的。GPT-3被提示以维基百科风格为每个概念生成第一段。

实时幻觉检测
import streamlit as st import utils import pandas as pdStreamlit app layout
st.title(‘Anti-Hallucination Chatbot’)
Text input
user_input = st.text_input(“Enter your text:”)
if user_input:
prompt = user_input
output, sampled_passages = utils.get_output_and_samples(prompt)
LLM score
self_similarity_score = utils.llm_evaluate(output,sampled_passages)
Display the output
st.write(“LLM output:”)
if float(self_similarity_score) > 0.5:
st.write(output)
else:
st.write("I’m sorry, but I don’t have the specific information required to answer your question accurately. ")
我们看看结果。

总结
聊天机器人的幻觉检测一直是人们讨论已久的质量问题。
我们只是概述的了目前的研究成果:通过生成对同一提示的多个响应并比较它们的一致性来完成。
还有更多的工作要做,但与其依赖于人工评估或手工制定的规则,让模型自己捕捉不一致似乎是一个很好的方向。
本文引用:
BERTSCORE: EVALUATING TEXT GENERATION WITH BERT
https://arxiv.org/abs/1904.09675
SELFCHECKGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
https://arxiv.org/abs/2303.08896
A Broad-Coverage Challenge Corpus forSentence Understanding through Inference
https://aclanthology.org/N18-1101
作者:Iulia Brezeanu
编辑:黄继彦
