了解探索性数据分析(EDA)及其在数据科学中的重要性与常用图形。
原文标题:独家 | 80%的时间中,数据科学家使用的20%探索数据的图——您需要了解的探索性数据分析(EDA)
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、你使用EDA图表时有什么技巧?
3、面对复杂的数据集,你会优先使用哪些EDA图表?
原文内容

翻译:林立琨
校对:赵茹萱
本文约1300字,建议阅读5分钟
本文手把手带你了解探索性数据分析(EDA)。
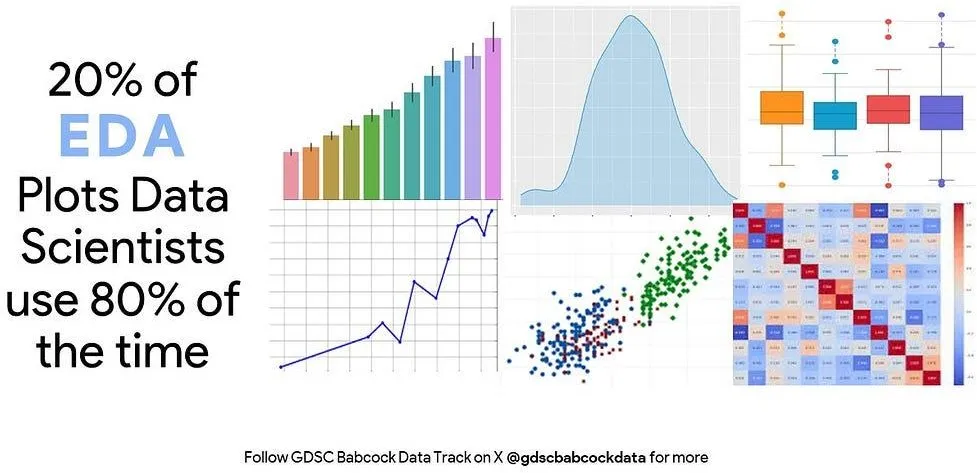
什么是 EDA?
据IBM的介绍,探索性数据分析(EDA)是数据科学家用来分析和研究数据集并总结其主要特征的一种方法,通常采用数据可视化技术。因此可以说,EDA 是通过创建可视化和摘要来研究和理解数据集的过程。
为什么需要 EDA?
EDA 在数据科学/机器学习工作流程中非常重要,真正的问题应该是 "没有 EDA 我们该怎么办!"医生在给病人开药或治疗之前,总是要做一些检查,问一大堆问题等等。数据科学家就像医生,只不过我们面对的不是病人,而是数据。EDA 是我们向数据提问的方式,目的是找出有关数据的一切信息,并了解数据为何如此(如识别趋势、模式、异常等)。而现在,好比药物和治疗,我们在尝试根据我们的数据决定最佳的模型和特征并在我们的数据上使用它们。因此,从 EDA 收集到的信息可以帮助我们做到这一点。这就是我们作为数据科学家需要 EDA 的主要原因。
请注意:
在本博文中,我们将使用
1. Seaborn 和 matplotlib 库
2. 来自 Seaborn 的 "Tips "数据集
现在,首先是数据科学家使用次数多的其中几个绘图。
1. 条形图/计数图
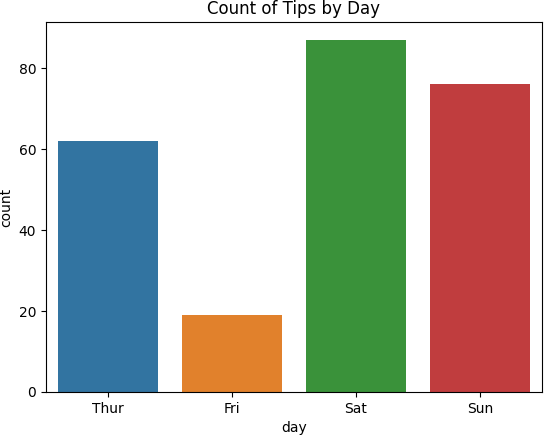
用于:
显示分类变量的分布。
可视化数据集中每个类别的频率或数量。
![]() 样例代码:
样例代码:
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset('tips')
sns.countplot(x='day', data=data)
plt.title('Count of Tips by Day')
plt.show()
2. 箱型图
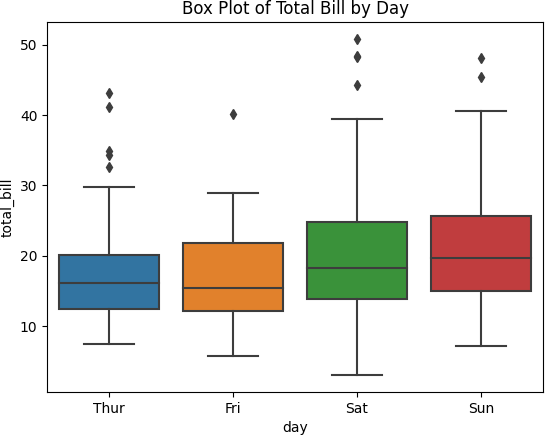
用于:
显示数据的平均值、中位数、分位数和异常值。
比较多个变量的分布。
识别数字变量的松散程度。
检测数据集中的潜在异常值。
样例代码:
import seaborn as sns import matplotlib.pyplot as plt
data = sns.load_dataset(‘tips’)
sns.boxplot(x=‘day’, y=‘total_bill’, data=data)
plt.title(‘Box Plot of Total Bill by Day’)
3. 密度图
先前提示:我们是数据科学家,我们使用密度图而不是直方图,因为我们讨厌猜测/决定最佳的组距。
![]()
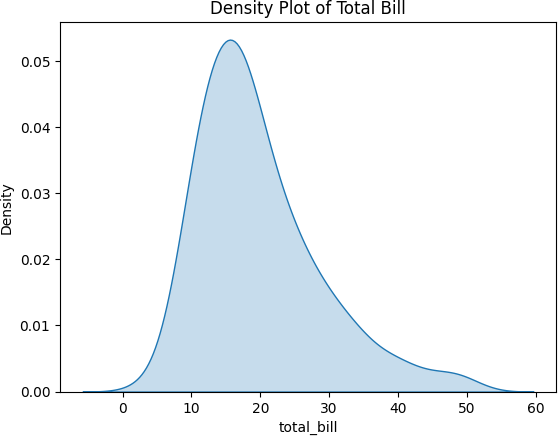
用于:
可视化连续变量的分布
识别数据中的峰值、谷值和整体模式。
了解分布的形状。
比较多个变量的分布。
样例代码:
import seaborn as sns import matplotlib.pyplot as plt
data = sns.load_dataset(‘tips’)
sns.kdeplot(data[‘total_bill’],
shade=True) plt.title(‘Total Bill 的密度图’)
plt.show()
4. 散点图
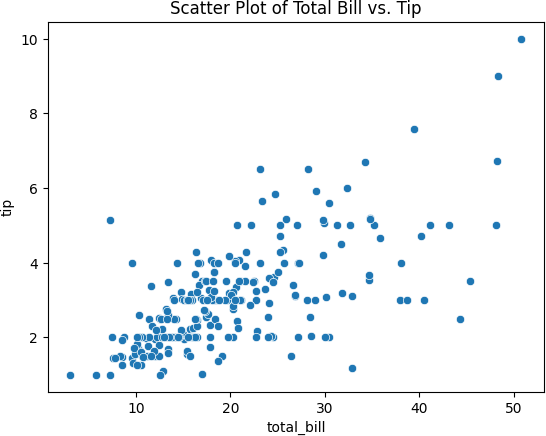
用于:
探索两个连续变量之间的关系。
识别数据中的模式、相关性或聚类。
样例代码:
import seaborn as sns import matplotlib.pyplot as plt
data = sns.load_dataset(‘tips’)
sns.scatterplot(x=‘total_bill’, y=‘tip’, data=data)
plt.title(‘Scatter Plot of Total Bill vs. Tip’)
5.折线图
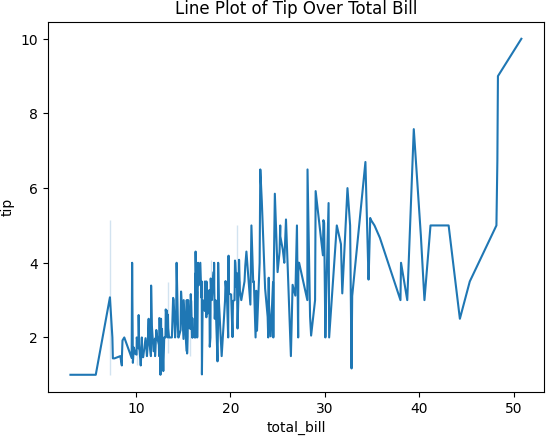
用于:
显示时间序列中的趋势或模式。
显示两个连续变量在一个连续区间内的关系。
比较变量在连续范围内的变化。
样例代码:
import seaborn as sns import matplotlib.pyplot as plt
data = sns.load_dataset(‘tips’)
sns.lineplot(x=‘total_bill’, y=‘tip’, data=data)
plt.title(‘Line Plot of Tip Over Total Bill’)
6. 热图
![]()
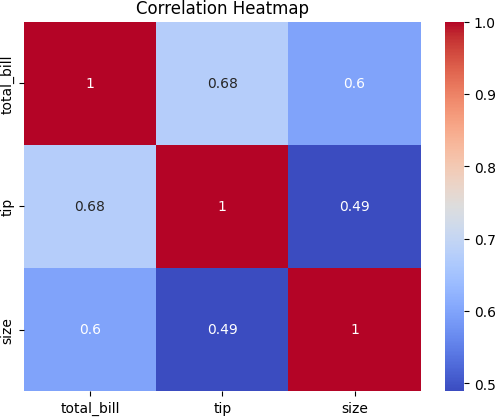
用于:
显示数值变量的相关矩阵。
识别大型数据集中的模式和关系。
样例代码:
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset('tips')
correlation_matrix = data.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Heatmap')
plt.show()
额外:组合图
听说过 "一石二鸟 "吗?
在 EDA 方面,我们也经常这样做,我们使用的图实际上是上述图的组合。
这样做是为了 "节省时间",但实事求是地说,像样的 EDA 值得付出大量的时间。
7. 分图
![]()
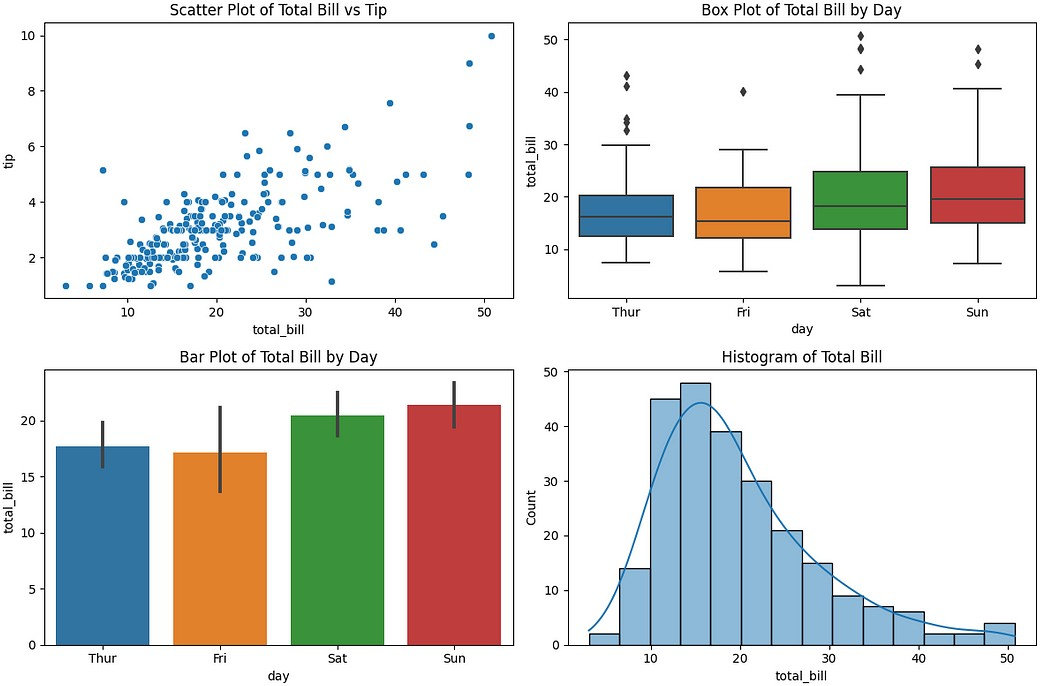
用于:在同一图表中并排比较多个绘图。
样例代码:
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset('tips')
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1) sns.scatterplot(x='total_bill', y='tip',
data=data) plt.title('Scatter Plot of Total Bill vs Tip')
sns.barplot(x='day', y='total_bill', data=data)
plt.title('Bar Plot of Total Bill by Day')
plt.subplot(2, 2, 4)
sns.histplot(data['total_bill'],kde=True)
plt.title('Histogram of Total Bill')
8. 成对图(并无官方翻译)
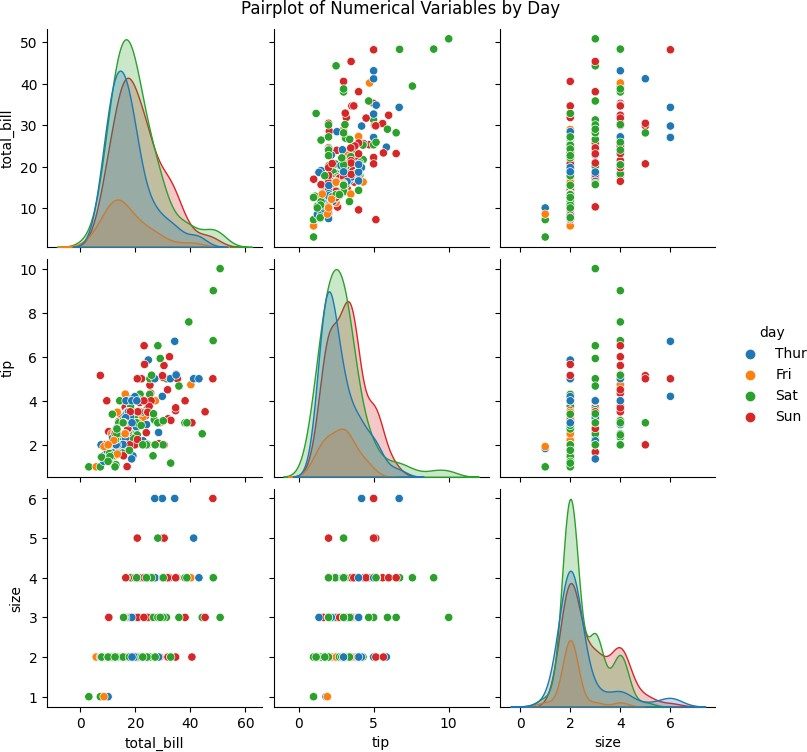
用于通过可视化成对变量来探索多个变量之间的相关性和趋势。
样例代码:
import seaborn as snsimport matplotlib.pyplot as plt data =
sns.load_dataset('tips')
sns.pairplot(data, hue='day')
plt.suptitle('Pairplot of Numerical Variables by Day', y=1.02)
plt.show()
9.小提琴图
结合了箱型图和核密度图的特点。
![]()
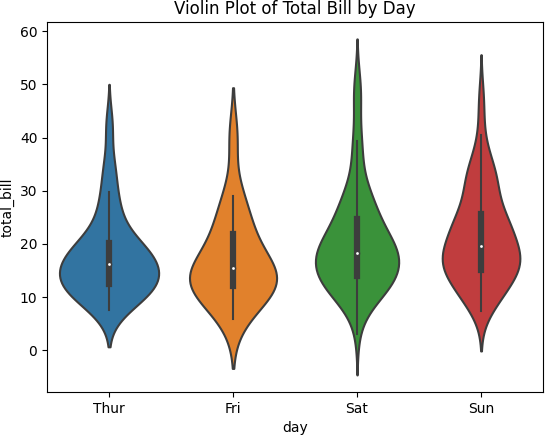
用于:可视化数值变量在不同类别中的分布。
样例代码:
import seaborn as sns import matplotlib.pyplot as plt
data = sns.load_dataset(‘tips’)
sns.violinplot(x=‘day’, y=‘total_bill’,
data=data) plt.title(‘Violin Plot of Total
Bill by Day’)
plt.show()
译者简介
作者简介
林立锟,香港城市大学计算数学本科,数据科学爱好者,对数学和计算机特别感兴趣,尤其是两者的结合部分特别感兴趣。兴趣是打羽毛球,以及琢磨一些奇奇怪怪的学习工具。希望能够通过自己的努力,将一些更优质的文章,更有价值的内容分享给读者,让大家在学习数据科学时能够更加顺利!
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
