阿里巴巴开源了Fluss项目,旨在提升Apache Flink在实时数据分析中的能力。
原文标题:阿里重磅开源 Fluss: Flink Unified Streaming Storage
原文作者:阿里云开发者
冷月清谈:
在11月29日举办的Flink Forward Asia 2024大会上,阿里巴巴开源了Fluss项目,旨在为Apache Flink提供实时流存储底座。Fluss的研发是为了应对传统工具在实时数据分析中的挑战,尤其是Kafka与Flink结合时遇到的限制造成的问题。Fluss项目融合了列存格式与实时更新能力,以支持高吞吐量、低延迟的流式数仓,具有实时读写、列式裁剪、流式更新等特性,能满足日益增长的企业对实时数据分析的需求。同时,阿里巴巴希望通过这一开源项目推动流领域的发展,预计将在2025年将其捐赠给Apache软件基金会,并诚邀开发者加入Fluss开源社区。
怜星夜思:
1、Fluss项目对于企业实时数据分析有哪些实际应用?
2、Fluss和传统的Kafka + Flink组合相比,最大的优势是什么?
3、你如何看待阿里巴巴对开源生态的推动?
2、Fluss和传统的Kafka + Flink组合相比,最大的优势是什么?
3、你如何看待阿里巴巴对开源生态的推动?
原文内容
在11月29日举办的 Flink Forward Asia 2024 大会主题演讲上,阿里巴巴正式开源了 Fluss 项目(https://github.com/alibaba/fluss)。阿里巴巴开源委员会副主席王峰先生,在现场进行了 Fluss 项目的开源,赢得了现场观众的热烈反响。

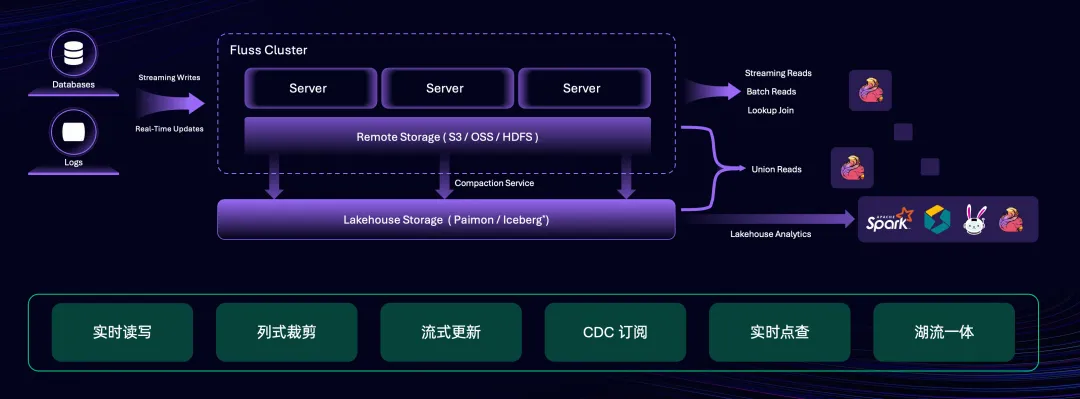
Fluss 项目是由阿里云智能 Flink 团队研发的一款面向流分析的下一代流存储,旨在解决流存储在分析方面长期存在的挑战。Fluss 的项目定位是为 Apache Flink 提供实时流存储底座,进一步提升 Flink 实时流计算的能力。因此,Fluss 的名字源自“FLink Unified Streaming Storage” 的首字母缩写。在项目名字背后,还有另一层有趣的含义。Flink 项目早期起源于德国,命名自德语单词“快速”。恰巧 Fluss 也是一个德语单词,读作“弗卢斯”,意为“河流”。Fluss 虽然诞生于中国,但其名称的德语背景不仅体现了对 Flink 项目起源的一种致敬,也象征着流数据如河流般不断流动、汇聚与分发的本质。

Fluss: 面向分析的实时流存储
在 Data + AI 驱动的新时代,企业对实时数据分析的需求日益增长。然而,传统上我们所依赖的工具和架构,在设计时并未将分析场景作为首要考量,这导致了企业在使用实时数据时面临诸多挑战。目前,业界常见的实时数仓架构是采用消息队列 Kafka 与流处理引擎 Flink 的组合。但是,Kafka 并非专门为分析而设计,因此在应用于流分析场景时存在一些显著的问题,比如不支持数据更新、缺乏高效的查询功能、数据难以复用、回溯历史数据困难、以及高昂的网络成本等。这些问题不仅使得 Kafka 与 Flink 的结合使用变得不够理想,也在一定程度上限制了 Flink 在更广泛应用场景中的发挥。
为了解决这些问题,我们研发了 Fluss 项目。Fluss 创新性地将列存格式和实时更新能力融合进了流存储中,并与 Flink 深度集成,帮助用户构建高吞吐量、低延迟、低成本的流式数仓。其具备如下核心特性:
-
实时读写:支持毫秒级的流式读写能力。
-
列式裁剪:以列存格式存储实时流数据,通过列裁剪可提升 10 倍读取性能并降低网络成本。
-
流式更新:支持大规模数据的实时流式更新。支持部分列更新,实现低成本宽表拼接。
-
CDC订阅:更新会生成完整的变更日志(CDC),通过 Flink 流式消费 CDC,可实现数仓全链路数据实时流动。
-
实时点查:支持高性能主键点查,可作为实时加工链路的维表关联。
-
湖流一体:无缝集成 Lakehouse,并为 Lakehouse 提供实时数据层。这不仅为 Lakehouse 分析带来了低延时的数据,更为流存储带来了强大的分析能力。
更多项目细节和特性介绍请访问项目官网:https://alibaba.github.io/fluss-docs
加入 Fluss 开源社区
过去,我们投入了大量精力来推进流技术开源生态,阿里巴巴目前是 Apache Flink 社区最大的推动者和贡献者,阿里巴巴今年正式将 Flink CDC 项目捐赠给了 Apache 基金会,由阿里巴巴开源和孵化的湖存储项目 Aapche Paimon 也在今年正式从 Apache 孵化器毕业成为顶级项目。现在,我们开源了 Fluss 项目,这是我们对推动流领域发展做出的又一个重大举措,我们也将保持过去打造开源精品的精神,为用户驱动下一代实时架构。
Fluss 目前已经在 GitHub 上以 Apache 2.0 协议正式开源。
项目地址为:https://github.com/alibaba/fluss
并且我们计划于 2025 年将其捐赠到 Apache 软件基金会。在此,我们诚挚地邀请各位加入 Fluss 开源社区,共同促进这一新兴项目的成长与发展。欢迎大家加入 Fluss 社区钉钉群:109135004351,欢迎大家一起探索,参与开发和贡献,并携手构建下一代的流存储技术。