大语言模型在软件开发中的应用面临多种挑战,尤其是可组合性和安全性问题。文章探讨开发者应如何应对这些局限。
原文标题:“为什么说大模型可能是软件开发的死胡同?”
原文作者:AI前线
冷月清谈:
怜星夜思:
2、开发者在使用LLM时还需注意哪些问题?
3、未来软件开发行业将如何适应新的AI技术?
原文内容

虽然“Does current AI represent a dead end?”这篇文章意在引发讨论,但其中的某些观点对软件开发人员来说特别具有相关性:
“当前的 AI 系统缺乏与其功能紧密相关的内部结构,无法作为组件进行开发或重用,也无法进行关注点分离或分阶段开发。”
本文仅讨论如何将大语言模型(LLM)作为产品解决方案的一部分,而非探讨如何在开发过程中使用 AI 工具(例如,Cursor 和 Zed AI 这样的 AI 编码工具)。尽管借助 LLM 进行特定的软件开发生命周期活动(SDLA)确实面临着一些挑战,但我们开发产品的方式与最终卖给客户的产品通常是有所区别的。因此,在下面的图表中,我们关注的是上面两个部分:
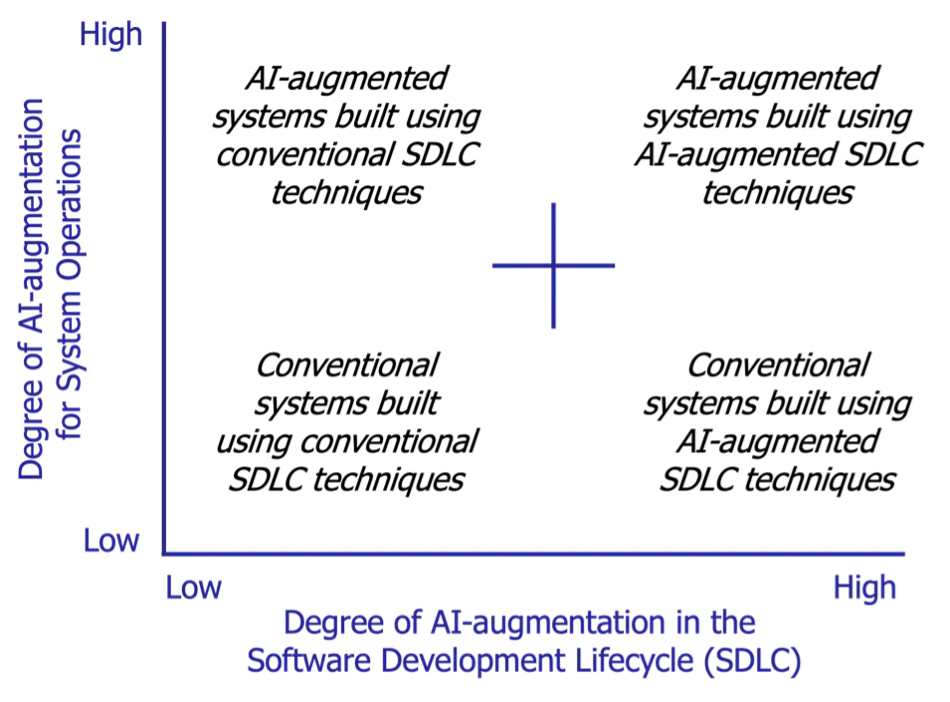
来自卡内基梅隆大学软件工程研究所的图片
当前 LLM 面临的问题在于它们像汽车一样被出售——用户需要为整个产品付费,而不能指望将它们作为可组合模块的一部分。汽车的不可分解性不是问题,因为驾驶是一项受到严格控制的活动。即便你能够像乐高积木一样将汽车组装起来,它也不会被允许上路。
这大概正是大型科技公司所期望的——他们希望卖给你一个完整的产品或服务,而不是一系列可以轻松被他人进行构建的可组合部件。保持 LLM 的神秘感有助于维持其高价值地位。
LLM 的运作模式违背了计算领域的一个基本原则,即任务应当可以被分解。
这违背了计算领域的一个基本原则,即任务应当可以被分解。一个高效的软件组件,无论是自行开发还是外部采购,都应由可进行单元测试的代码构成。这些组件必须能够与其他组件可靠地协同工作。
即便某个产品采用了 Oracle 数据库,我们依然能够明白在概念设计层面上是存在数据持久化的。在决定使用哪种类型的存储技术时,测试机制已经准备就绪了。同时,数据库技术在不断创新,但客户永远不会认为存储厂商在某种程度上控制了软件。
在学术界,可分解性的缺失往往与可解释性的缺失相伴而生。我们可以归纳出其他与 LLM 在交付软件中的商业问题相关的因素。
我们无法将 LLM 的行为与训练数据分离。
目前,我们无法将 LLM 的行为与训练数据分离。我们知道 LLM 是经过训练的,但训练过程通常是不公开的,而结果却被期望能够被“原封不动”地接受。这种对组件“腌制”的期望在烹饪中或许可行,但在软件组件开发中却并不适用。
安全和隐私问题成为关注点,因为我们缺乏可靠的途径或方法来防止 LLM 泄露某些敏感信息。我们无法从外部干预神经网络,向它解释哪些信息是私密的,哪些不应该被泄露。
法律所有权问题依然很棘手。我们可以证明冷计算的操作结果是可重复的,在输入相同的情况下会得出相同的答案。然而,由于 LLM 携带着无法摆脱的训练“包袱”,我们根本无法证明它们没有侵犯现有的知识产权——而实际上,它们很可能已经侵犯了。
那些致力于减少碳足迹的公司正朝着与 LLM 厂商相反的方向前进,而 LLM 厂商需要惊人的计算资源来获得递减的性能改进。
本文并不是要讨论如何使用 LLM 来辅助开发,也不是关于向终端用户提供 LLM 工具。我使用的文本编辑器内置了某些形式的 AI 功能,但这些操作没有任何保障。我们都知道这些通常是走过场的功能——某些必须出现在产品中的“噱头”,而并非核心组成部分。
我认为 LLM 作为服务被引入产品的前景不大,除非 LLM 本身就是产品。
鉴于前面提到的原因,我认为 LLM 作为服务被引入产品的前景不大,除非它本身就是产品。但即便如此,这对任何企业来说都是一个巨大的陷阱。当 Zoom 创始人 Eric Yuan 提出在 Zoom 中引入 AI 替身代替与会者参加会议的想法时,理所当然地遭到了嘲笑,他认为这种能力会在“技术栈的底层”自然而然地出现。将重大创新外包给了 LLM 厂商,实际上是将自己的产品路线图交给了另一家公司掌控。
那么,软件开发人员应该如何应对?我们都明白,一个组件应该有明确的职责,应该能够被替换,并且能够与其他组件一起被测试。如果是外部组件,也应当遵循相同的计算标准——而且我们应该能够依据这些标准来重新构建它们。
我们不应因追求短期的热度而轻易改变游戏规则。关键在于要设计一个能够为企业提供所需功能的流程,然后开发一个平台,以可持续的方式让开发人员进行构建。
作为开发人员,我们应当保持开放的态度,拥抱真正可解释、可测试的 AI。
作为开发人员,我们应当保持开放的态度,拥抱真正可解释、可测试的 AI。如果涉及训练过程,这个过程应当是可监控、可报告、可重复、可解释且可逆的。如果我们发现 LLM 认为某件事是真实的,而实际并非如此,那么必须能够通过一系列明确的步骤迅速进行修正。如果这样的描述没有意义,那么目前基于 LLM 的计算也同样没有意义。但理论上,我看不出为什么未来不能改变这一现状。
我担心的是,这种差异就像是科学与圣物信仰之间的对比。我们可以进行一系列不可行的实验(如果将圣物切成几块,这些碎片是否依然保持其神圣性?),但不应该期望这两个领域会有任何融合的可能性。
原文链接:
https://thenewstack.io/why-llms-within-software-development-may-be-a-dead-end/
声明:本文由 InfoQ 翻译,未经许可禁止转载。
就在 12 月 13 日 -14 日,AICon 将汇聚 70+ 位 AI 及技术领域的专家,深入探讨大模型与推理、AI Agent、多模态、具身智能等前沿话题。此外,还有丰富的圆桌论坛、以及展区活动,满足你对大模型实践的好奇与想象。现在正值 9 折倒计时,名额有限,快扫码咨询了解详情,别错过这次绝佳的学习与交流机会!

