人工智能领域传来重磅消息!强化学习大牛朱利安·施里特维泽已加入Anthropic,他将继续在强化学习领域探索,推动人工智能的发展。
原文标题:Anthropic挖走DeepMind强化学习大牛、AlphaGo核心作者Julian Schrittwieser
原文作者:机器之心
冷月清谈:
DeepMind强化学习领域核心作者朱利安·施里特维泽已宣布加入Anthropic。作为Alpha系列成果的核心贡献者,施里特维泽在强化学习领域拥有丰富的经验和成就。
**施里特维泽在DeepMind的贡献**
在DeepMind工作的十年中,施里特维泽参与了众多具有里程碑意义的项目,包括:
- **AlphaGo:**击败世界顶级围棋选手李世石,引发全球轰动。
- **AlphaGo Zero:**通过自我博弈强化学习,在多种游戏中超越人类水平。
- **MuZero:**无需任何底层知识,在国际象棋、围棋和雅达利游戏中展现卓越表现。
- **AlphaCode:**可与人类媲美地编写计算机代码。
- **AlphaTensor:**发现新的矩阵乘法算法,解决数学领域悬而未决的问题。
- **AlphaProof:**在国际数学奥林匹克竞赛中取得突破性进展。
**Anthropic的吸引力**
施里特维泽被Anthropic的Claude人工智能模型和持续的技术进步所吸引。他期待与团队合作,探索人工智能的更多可能性。
**对人工智能发展的影响**
施里特维泽的加入表明了强化学习在人工智能领域的关键作用。随着计算能力的提升,强化学习有望进一步突破大模型性能上限,推动人工智能的发展向前迈进。
怜星夜思:
2、施里特维泽在Anthropic将从事哪些领域的研究?
3、未来人工智能发展的趋势是什么?
原文内容
机器之心报道
编辑:蛋酱
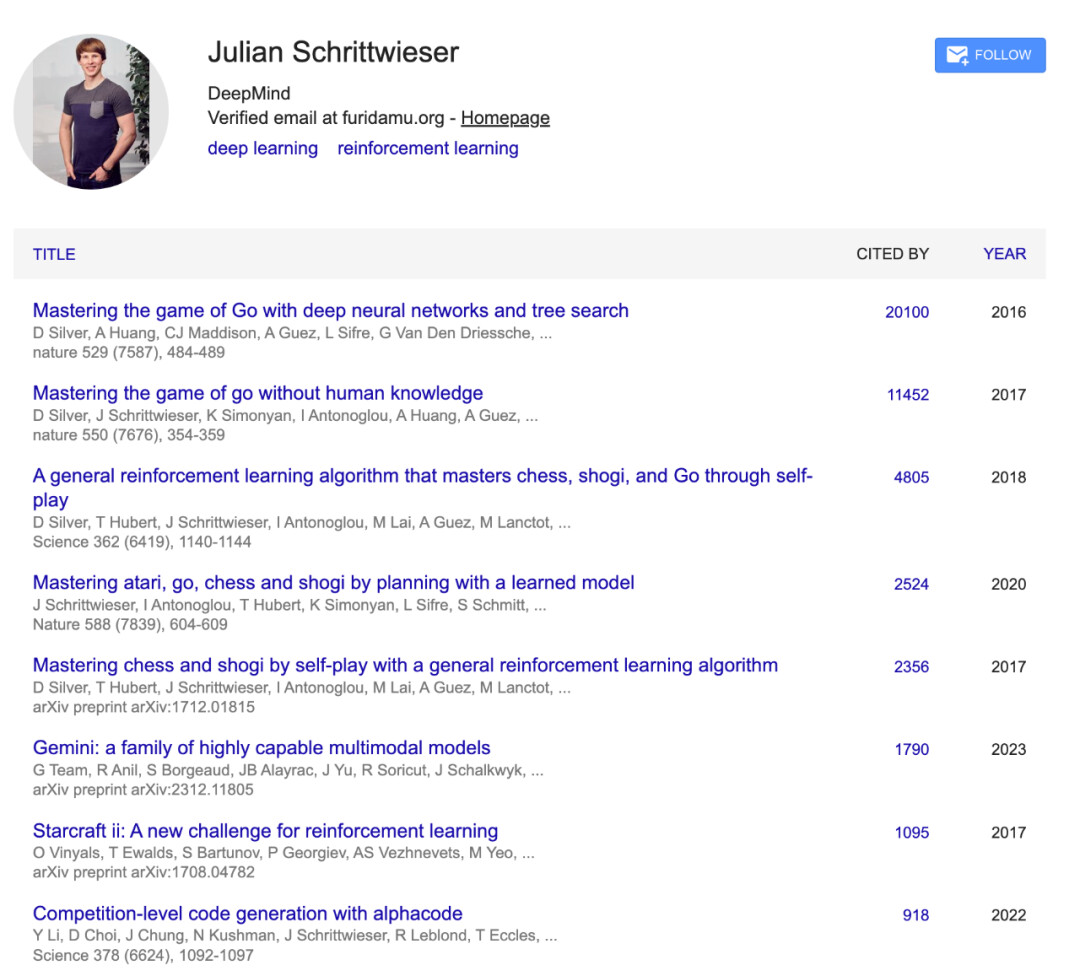
从 AlphaGo、AlphaZero 、MuZero 到 AlphaCode、AlphaTensor,再到最近的 Gemini 和 AlphaProof,Julian Schrittwieser 的工作成果似乎比他的名字更广为人知。
今天的 AI 社区,再次被一则大佬转会消息吸引了目光。
在谷歌工作十年后,大名鼎鼎的谷歌 DeepMind Alpha 系列核心作者 Julian Schrittwieser,宣布加入 Anthropic。
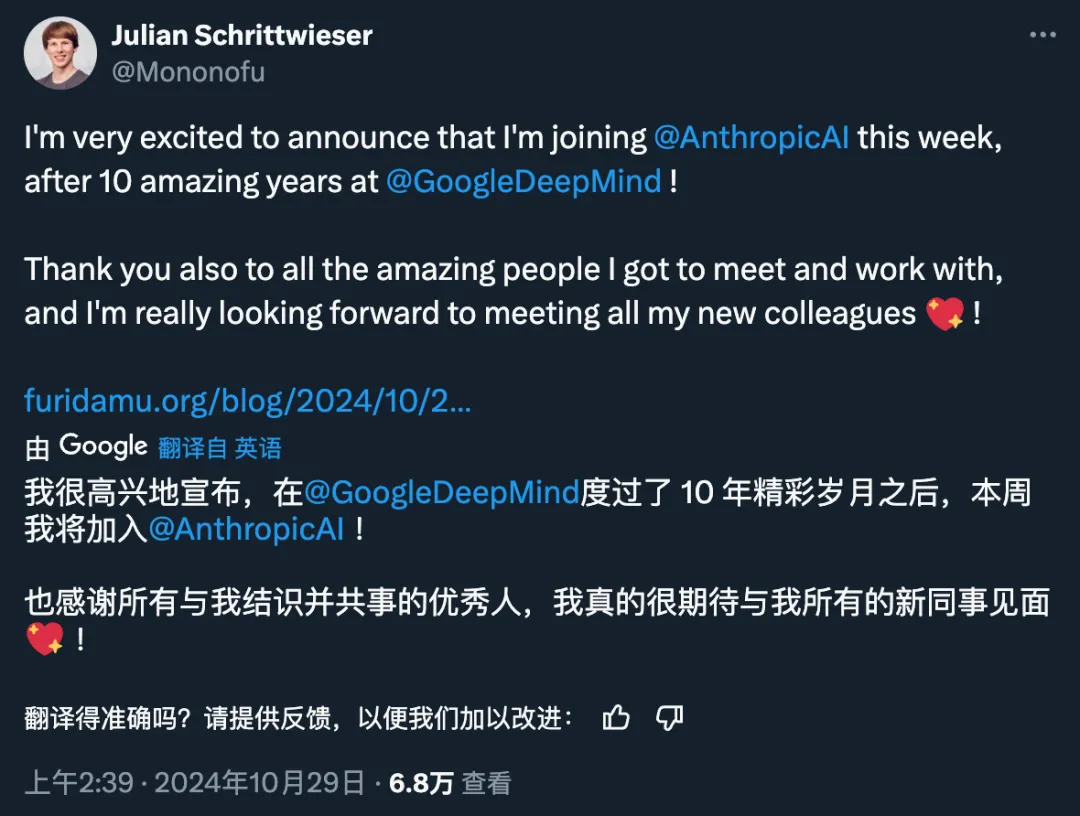
我很高兴地宣布,将从本周起加入 Anthropic!Claude 是我发现自己一直在使用的第一个 LLM。最近,我被《Artifacts》和《Computer Use》以及 Claude 不断提高的技能深深震撼了。
我非常幸运地参与了谷歌 DeepMind 过去 10 年的奇妙旅程,在那里我参与了很多令人兴奋的项目,这是我做梦都想不到的:从 AlphaGo 到 AlphaZero 和 MuZero 的传奇;还有很多的应用研究,如 AlphaCode 和 AlphaTensor,以及最近的 Gemini 和 AlphaProof。我相信,那里的团队也将继续创造惊人的成就,我迫不及待地想一探究竟!
Julian Schrittwieser 的跳槽,可以说是近期领域内最为惊人的一则消息,因为 Julian Schrittwieser 在 DeepMind 内部的地位非同寻常。更令人好奇的是,Anthropic 是如何招揽到这样一位顶尖人才:
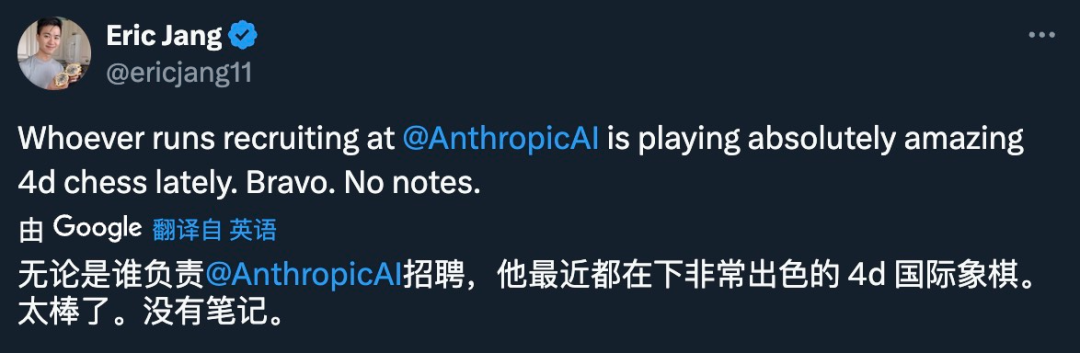
不管过程如何,这一定是 Anthropic 最「超值」的一次招聘:

在 DeepMind 诞生以来的数年中,「Alpha 系列成果」一直是该团队最闪耀的前沿成果。而 Julian Schrittwieser 是这些伟大成就中不可忽视的贡献者。
2016 年,DeepMind 开发的 AlphaGo 以 4:1 击败世界顶级围棋棋手李世石(Lee Se-dol),成为轰动全球的人工智能里程碑事件。Julian Schrittwieser 参与撰写了第一篇关于 AlphaGo 的里程碑式论文。
-
《》
2017 年,在 AlphaGo 与柯洁的比赛之后,DeepMind 宣布退役 AlphaGo,自学成才的 AlphaGo Zero 以 100:0 击败了早期的竞技版 AlphaGo,Julian Schrittwieser 是 AlphaGo Zero 论文的第二作者,也负责了从主搜索算法、训练框架到对新硬件的支持等工作。
-
《》
-
《》
而 AlphaGo Zero 随后被拓展为一个名为 AlphaZero 的程序。2017 年底,DeepMind 正式发表了 AlphaZero,这是一种可以从零开始通过 Self-Play 强化学习在多种任务上达到超越人类水平的算法。该算法经过不到 24 小时的训练后,即可在国际象棋和日本将棋上击败此前业内顶尖的计算机程序(这些程序早已超越人类世界冠军水平),也轻松击败了训练 3 天时间的 AlphaGo Zero。
-
《》
2020 年,DeepMind 发表了 MuZero。在不具备任何底层动态知识的情况下,该算法通过结合基于树的搜索和学得模型,不仅在国际象棋、日本将棋和围棋的精确规划任务中匹敌 AlphaZero,还在 30 多款雅达利游戏中展示出了超越人类的表现。Julian Schrittwieser 是 MuZero 论文《Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model》的核心作者之一。
-
《》
2022 年 2 月,DeepMind 发布了基于 Transformer 模型的 AlphaCode,可以编写与人类相媲美的计算机程序。包括 Julian Schrittwieser 在内的多位作者后续又在《Science》上发表了论文。
-
《》
-
《》
2022 年 10 月,DeepMind 提出了 AlphaTensor,第一个可用于为矩阵乘法等基本任务发现新颖、高效且可证明正确的算法的人工智能系统,并揭示了 50 年来在数学领域一个悬而未决的问题,即找到两个矩阵相乘最快方法。AlphaTensor 建立在 AlphaZero 的基础上,展示了 AlphaZero 从用于游戏到首次用于解决未解决的数学问题的一次转变。
-
《》
2023 年 6 月,谷歌 DeepMind 发布了 AlphaDev,这种全新的强化学习系统发现了一种比以往更快的哈希算法。Julian Schrittwieser 也是 AlphaDev 项目的核心参与者之一。
-
《》
2024 年 7 月,谷歌 DeepMind 团队研发的 AlphaProof 和 AlphaGeometry 2 在 IMO 竞赛上共同实现了里程碑式的突破。AlphaProof 是一种用于形式化数学推理的强化学习系统,而 AlphaGeometry 2 是 DeepMind 几何求解系统 AlphaGeometry 的改进版本。正式比赛中,AlphaProof+AlphaGeometry 2 组合成的 AI 系统在几分钟内就解决了人类参赛选手需要几个小时才能解决的问题。
-
《》
8 年前,基于强化学习的 AlphaGo 声名大噪;8 年后,强化学习在 AlphaProof 中再次大放异彩。2016 年 AlphaGo 论文的核心成员 Julian Schrittwieser、Aja Huang、Yannick Schroecker,如今也是 AlphaProof 的核心贡献者。有人在朋友圈感叹说:RL is so back!
业内普遍认为,OpenAI o1 运用的技术关键也在于强化学习的搜索与学习机制,这标志着 RL 下 Post-Training Scaling Law 的时代正式到来。正如《The Bitter Lesson》所说,只有搜索和学习这两种学习范式能够随着计算能力的增长无限扩展。强化学习作为这两种学习范式的载体,如何能够在实现可扩展的 RL 学习(Scalable RL Learning)和强化学习扩展法则(RL Scaling Law),将成为进一步突破大模型性能上限的关键途径。
这或许就是 Calude 团队招揽 Julian Schrittwieser 的出发点。o1 研发团队在采访中也谈到过,OpenAI 很早就受到 AlphaGo 的启发,意识到了深度强化学习的巨大潜力,并在相关方向投入了大量研究力量。
作为 RL 领域的深耕者,Julian Schrittwieser 又会带领 Claude 团队做出怎样的成果呢?让我们拭目以待。
参考链接:https://www.furidamu.org/blog/2024/10/28/joining-anthropic/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com