大语言模型VS视频理解?清华大学提出VERIFIED,自动化视频,文本细粒度标注新范式!
原文标题:NeurIPS 2024 | 消除多对多问题,清华提出大规模细粒度视频片段标注新范式VERIFIED
原文作者:机器之心
冷月清谈:
- 为了解决 VCMR 多对多问题,清华大学提出 VERIFIED 自动视频-文本细粒度标注系统。
- 该系统利用大模型生成静态和动态细粒度描述,并通过数据评估模块保证标注质量。
- 基于 VERIFIED,构建了 Charades-FIG、DiDeMo-FIG 和 ActivityNet-FIG 数据集,以推动细粒度 VCMR 发展。
- 实验表明,VERIFIED 生成的细粒度标注有效提升了 VCMR 模型在细粒度场景下的性能。
- 该系统利用大模型生成静态和动态细粒度描述,并通过数据评估模块保证标注质量。
- 基于 VERIFIED,构建了 Charades-FIG、DiDeMo-FIG 和 ActivityNet-FIG 数据集,以推动细粒度 VCMR 发展。
- 实验表明,VERIFIED 生成的细粒度标注有效提升了 VCMR 模型在细粒度场景下的性能。
怜星夜思:
1、VERIFIED 系统如何保证细粒度标注的质量?
2、VERIFIED 构建的新数据集相比传统 VCMR 基准数据集有什么优势?
3、VERIFIED 在 VCMR 领域的应用前景如何?
2、VERIFIED 构建的新数据集相比传统 VCMR 基准数据集有什么优势?
3、VERIFIED 在 VCMR 领域的应用前景如何?
原文内容
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
陈厚伦,清华大学计算机系媒体所的二年级博士生,主要研究方向是多模态大模型与视频理解 ,在 NeurIPS 、ACM Multimedia 等顶级会议发表多篇论文,曾获国家奖学金、北京市优秀本科毕业生等。
视频内容的快速增长给视频检索技术,特别是细粒度视频片段检索(VCMR),带来了巨大挑战。VCMR 要求系统根据文本查询从视频库中精准定位视频中的匹配片段,需具备跨模态理解和细粒度视频理解能力。
然而,现有研究多局限于粗粒度理解,难以应对细粒度查询。为此,来自清华大学的研究者提出自动化视频 - 文本细粒度标注系统 VERIFIED,并基于此系统构建新的细粒度 VCMR 基准数据集(Charades-FIG、DiDeMo-FIG 和 ActivityNet-FIG),以推动细粒度视频理解的发展。

-
论文题目:VERIFIED: A Video Corpus Moment Retrieval Benchmark for Fine-Grained Video Understanding (NeurIPS 2024 Track on Datasets and Benchmarks)
-
论文链接:https://arxiv.org/pdf/2410.08593
-
主页链接:https://verified-neurips.github.io/
一、介绍
视频语料库时刻检索(VCMR)旨在根据文本查询从大量视频中精确定位特定片段。传统 VCMR 基准的视频标注多为粗粒度标注,视频与文本间存在多对多问题,无法支持细粒度视频检索的训练与评估(图 1 (a)),因此有必要为细粒度 VCMR 建立一个合适的 benchmark。为解决此问题,该研究提出了细粒度 VCMR 场景,使用更精细的文本查询消除数据集中的多对多现象(图 1 (b))。然而建立此类细粒度的 benchmark 有如下的挑战:
(1)人工标注细粒度信息成本高昂,是否可以利用大模型技术实现这一过程?
(2)研究证明大模型存在幻觉问题,如果利用大模型进行标注,如何设计一种方法保证标注数据的质量?
为此,该研究设计了自动细粒度视频标注系统 VERIFIED(图 1 (c)),通过大模型生成富含静态和动态信息的标注,并且基于微调 video foundation model 设计了一个高效的标注质量评估模块,基于此构建了 Charades-FIG、DiDeMo-FIG 和 ActivityNet-FIG 高质量细粒度 VCMR 基准,以推动细粒度 VCMR 研究发展。

图 1:a) 粗粒度 VCMR 中,因查询文本简单,存在许多潜在正匹配(绿色),但这些时刻未被标注,导致真实标注不合理。b) 该研究提出的具有挑战性的细粒度 VCMR 中,查询更细粒度,方法需要从部分匹配的候选项(粉色)中检索出最匹配的一个(绿色)。c) 该研究的 VERIFIED 生成了可靠细粒度标注,包括丰富静态(绿色)和动态细节(蓝色)。
二、VERIFIED 视频细粒度标注系统
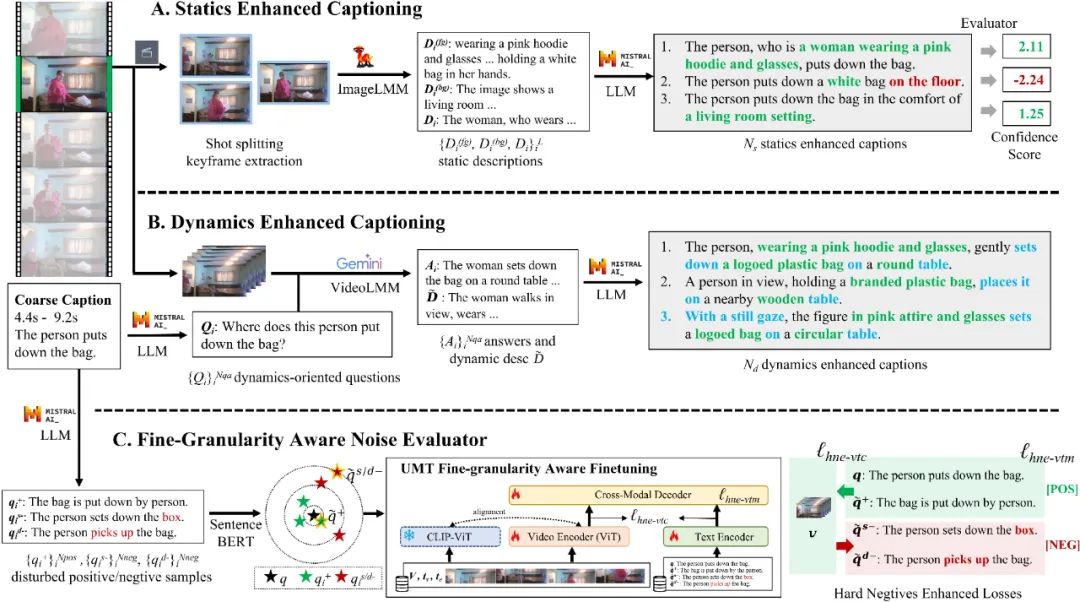
图 2:VERIFIED 流程图。Statics Enhanced Captioning(A)和 Dynamics Enhanced Captioning(B),它们生成带有静态和动态细节的多个细粒度描述候选。此外,该研究设计了一个 Fine-Granularity Aware Noise Evaluator(C),该模块生成并选择被扰动的正负样本,通过难负样本增强的对比损失和匹配损失来微调 UMT。这个评估器对描述进行评分,以识别不准确描述。
图 2 展示了该研究的 VERIFIED 标注流程图。为了让大模型像人类那样对视频中的细粒度信息进行标注,该研究设计了 Statics Enhanced Captioning 和 Dynamics Enhanced Captioning 模块,分别对静态与动态细节进行描述。静态信息增强模块通过提取视频关键帧,分析前景和背景属性,生成多个静态细粒度描述,丰富视频的静态视觉信息。动态信息增强模块则根据视频的一个粗粒度标注,首先由 LLM 生成与视频动态内容相关的问题,使用视频问答系统(VQA)获取动态细节,进而生成多个动态细粒度标注,帮助模型更好地理解视频中的动作和变化。
为了保证数据标注的质量,该研究设计了一个细粒度感知的噪声评估模块,其目的在于从前面模块标注的数据中,筛选出可靠的细粒度标注,主要通过以下步骤进行:
(1)扰动文本生成:评估器首先从原始粗粒度标注中生成正向和负向的扰动文本。这些文本通过引入难例(挑战样本)与原始标注进行对比,以提高模型对细粒度差异的敏感度。
(2)筛选最优扰动:通过使用预训练模型(如 SentenceBERT),评估器从生成的扰动文本中挑选最合适的正向改写和最具挑战性的负向改写,保证生成的文本与原始标注的语义距离合理。
(3)损失函数:引入上述正向和负向的扰动文本,计算文本和视频间的对比损失和匹配损失。引入正向扰动文本是为了防止 LLM 生成文本的潜在的 bias,引入负向扰动文本作为困难负样本增强模型对细粒度信息的感知能力。
最后该研究用这个模块对标注数据进行打分,用来作为数据筛选的标准。该研究将 VERIFIED 系统应用于 Charades-STA、DiDeMo、ActivityNet Captions 数据集,对每个视频片段筛选分数最高的标注,得到新的 Charades-FIG、DiDeMo-FIG、ActivityNet-FIG 数据集,作为细粒度 VCMR 的 benchmark。
图 3 图 4 展示了该研究的标注中具有代表性的可视化样本。
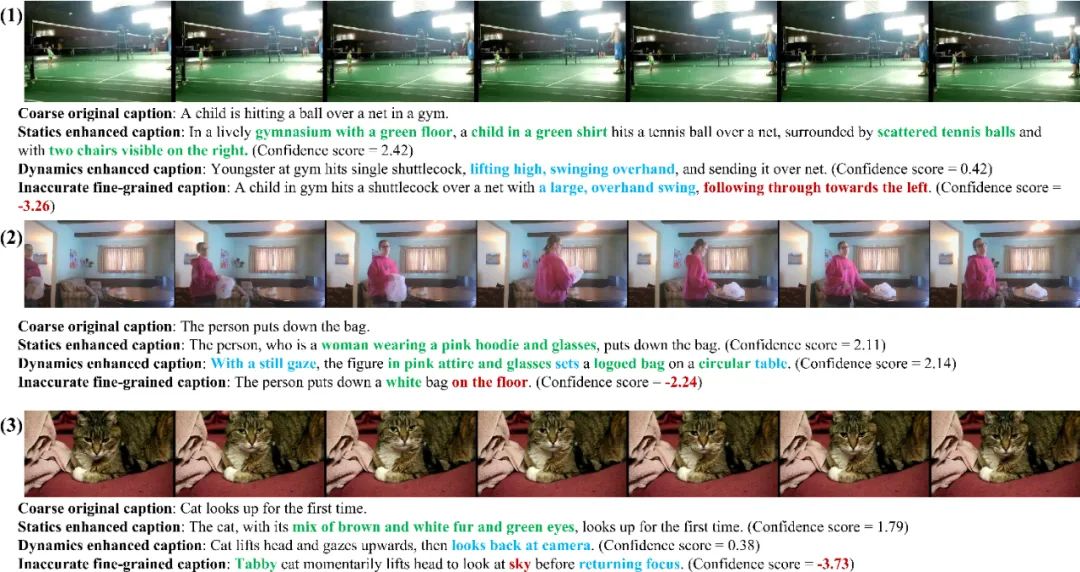
图 3:(1-3)分别节选自 ActivityNet-FIG、Charades-FIG、DiDeMo-FIG 数据集,静态和动态的细粒度内容分别用绿色和蓝色标出,不准确的内容用红色标出。

图 4:(1) 本文构建的标注捕捉到了狗与训犬师之间的互动以及狗的运动轨迹。(2) 捕捉到了人物抛掷物体的细节,并传达了这个人多次抛掷的信息。(3) 读取了视觉内容中的文字信息,并正确表达了使用原料的顺序。
统计数据和用户实验还表明视频片段与标注文本之间的多对多现象得到了显著减少,标注细粒度和质量得到了用户的认可。
三、VCMR 实验
本文评估了 HERO、XML、ReLoCLNet、CONQUER、SQuiDNet 方法,分别在 Charades-FIG、DiDeMo-FIG、ActivityNet-FIG 上,对 VCMR(视频库片段检索)、VR(视频检索)、SVMR(单视频片段检索)任务进行了测评,对于片段检索指标,以 0.5/r10 为例,0.5/r10 表示召回的 top-10 个片段中与 ground truth 的 IoU 大于 0.5 的比例,结果如图 5、6 所示。不同模型在视频检索任务中的表现各异,两阶段方法(如 CONQUER、SQuiDNet)通常优于单阶段的方法,所以训练过程中应当避免将视频级别和片段级别的学习纠缠在一起,因为这可能会干扰模型对精确时刻定位的能力,进而影响整体性能,未来研究应该关注如何有效分离视频级别和片段级别的学习,并合理引入细粒度信息。
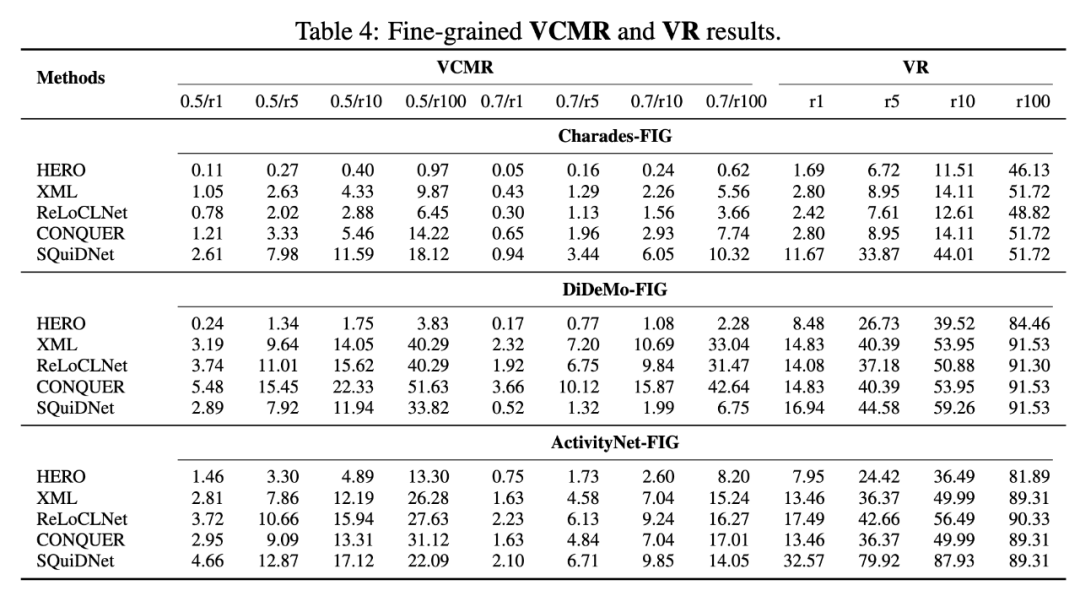
图 5:细粒度 VCMR、VR 实验结果
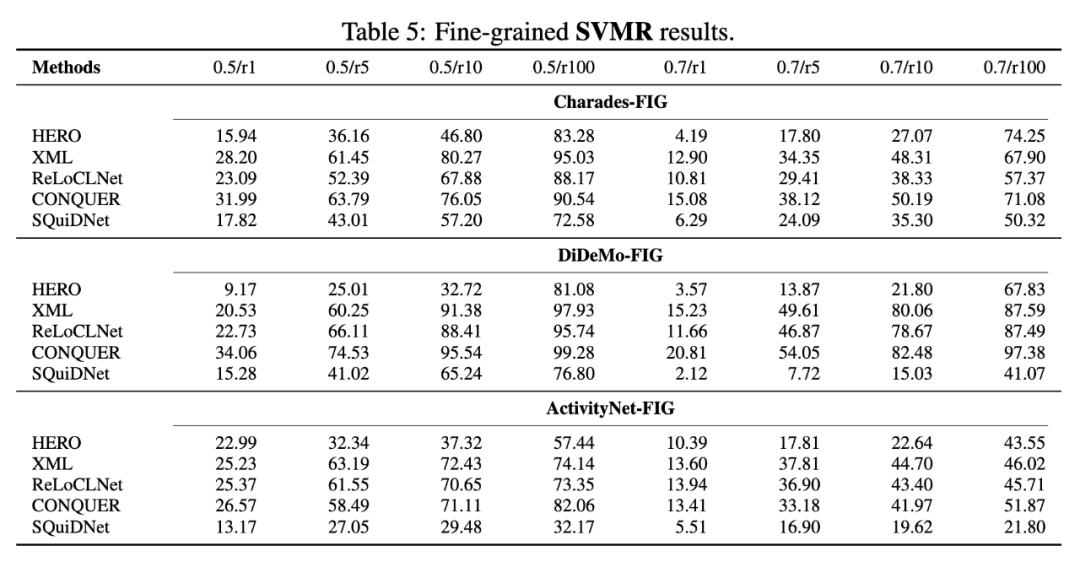
图 6:细粒度 SVMR 实验结果
为了说明该研究的细粒度训练数据对于提升模型的细粒度视频检索能力的意义,图 7 展示了 XML 在 Charades-FIG 上训练时,使用不同细粒度训练数据的预测结果可视化。当使用粗粒度数据进行训练时,真实值视频不在时刻排名列表的前 100 名内。排名靠前的预测主要集中在笔记本电脑上,而忽略了其他细节。使用该研究细粒度数据时,性能大大提升。它在排名第 5 位找到了目标时刻,后面的其他候选也与查询高度相关。这展示了细粒度 VCMR 场景中的挑战以及该研究的 VERIFIED 系统生成的标注数据在训练中的有效性。
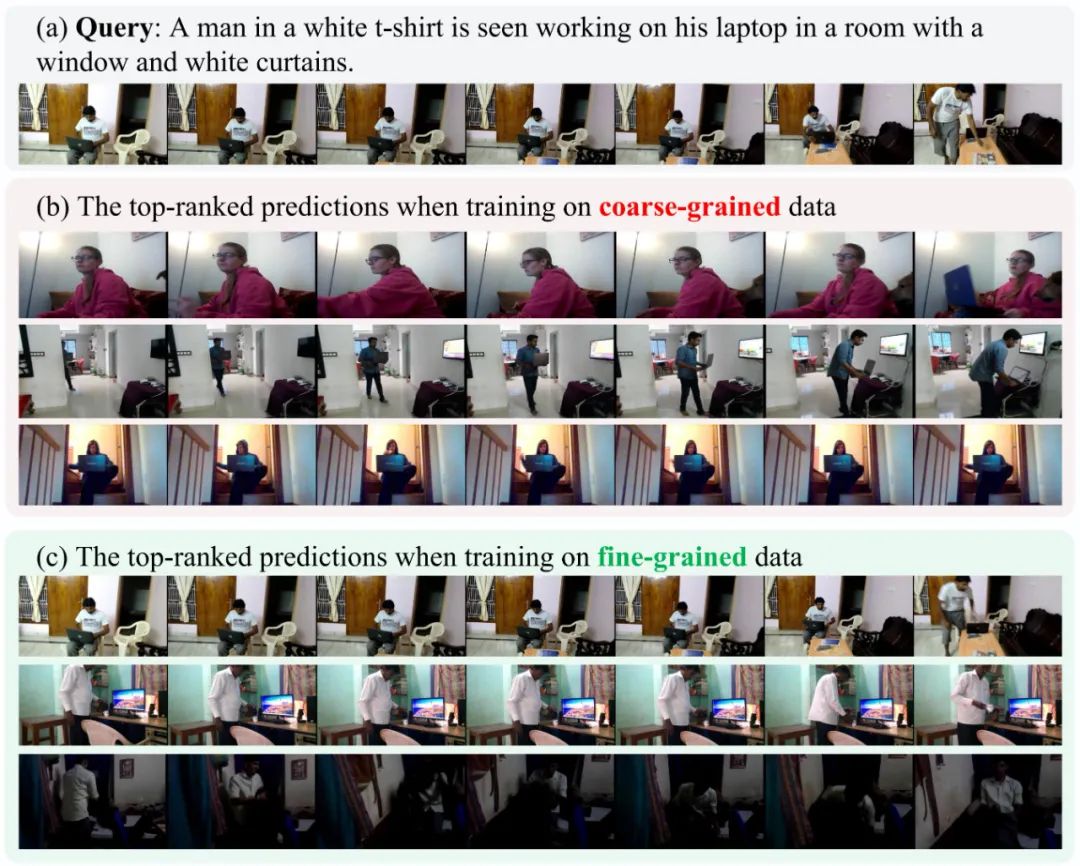
图 7:XML 在 Charades-FIG 上使用不同细粒度训练数据的部分预测结果
四、结论
现有 VCMR 基准数据集以粗粒度为主,限制了模型对细粒度视频特征的学习。为此,该研究提出了 VERIFIED 自动标注系统,结合大语言模型和多模态大模型生成细粒度的静态和动态标注,并通过微调 UMT 作为数据评估模块提高标注可靠性。基于 VERIFIED 系统,该研究构建了新的细粒度 VCMR 数据集(Charades-FIG、DiDeMo-FIG、ActivityNet-FIG),评估了现有 VCMR 模型在细粒度场景上的表现,实验发现现有检索模型在处理细粒度信息时仍与现实需求存在较大差距。
参考工作
[1] Unmasked teacher: Towards training-efficient video foundation models
[2] Tall: Temporal activity localization via language query
[3] Localizing moments in video with natural language
[4] Dense-captioning events in videos

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com