原文标题:Windows 竞技场:面向下一代AI Agent的测试集
原文作者:机器之心
冷月清谈:
怜星夜思:
2、WAA测试集中,不同任务板块之间的差异是什么?
3、如何确保AI Agent在实际使用中符合伦理规范和负责任?
原文内容
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]
Copilot 和 ChatGPT 这样的 AI 助手已经成为了百万用户的日常工具, 它们可以帮我们完成各种任务:写代码开发程序、 回答问题、 甚至研究创新食谱。那么,随着大语言模型的发展,未来的 AI 助手应该是什么样的呢?未来的 AI 模型的能力将不仅局限于逻辑推理,它还应该具备自主计划和行动的能力。未来的 AI 助手 – AI Agent(Assistant)可以在 PC 上进行自主操作,进一步提高我们的生产力;它还能帮我们降低使用专业软件的门槛;最重要的是,它可以替我们完成复杂繁琐的任务,例如假期规划、文档编辑、填写报销申请等等。

-
论文标题:Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale
-
论文地址:https://arxiv.org/abs/2409.08264
-
项目地址:https://github.com/microsoft/WindowsAgentArena
什么是 AI Computer Agent?
AI Computer Agent 可以被译为 AI 计算机助理。我们通常认为 Agent 是能感知其环境、并对其进行推理,甚至采取行动的系统。而 Computer Agent 则意味着能理解当前的屏幕上的内容,然后自主点击、输入和操作可以帮助用户完成任务的应用程序。一个 AI Computer Agent 需要能支持多模态输入,并且能使用大语言模型和视觉模型来理解屏幕上的内容并与其进行互动。
Windows Agent Arena 测试集 (WAA)

图 1 Windows Agent Arena 概览
目前许多公司和科研人员都在探索能够代替人类完成任务的 AI Agent。例如,微软最近发布的 UFO 模型是一个能够控制 Windows UI 的代理。另外,目前业界也已经存在一些针对 Agent 的 Benchmark,比如基于网络任务 Visual Web Arena、移动设备 Android World 和计算机 OS World 的 Benchmark。
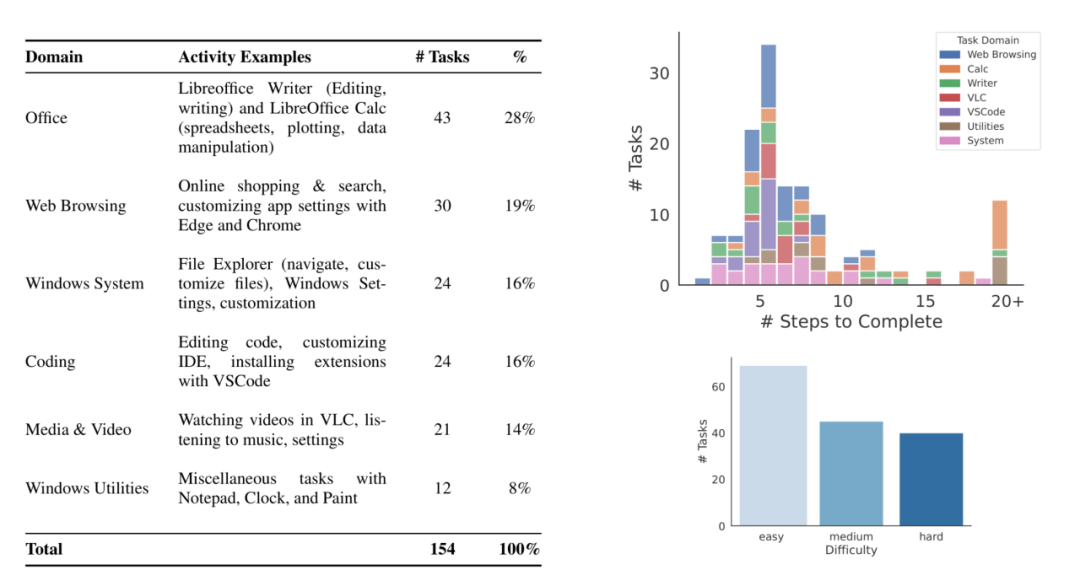
我们提出的 WAA 将进一步扩展 OS World 提出的 Benchmark。由于 OS World 主要包含 Linux 系统的任务,而缺乏 windows 平台上的任务,我们针对 Windows 平台上的任务进行了扩展。我们一共设置了 154 个用户在 Windows 上日常会涉及到的任务,包括浏览器、文档管理器、视频播放、编写代码和常用的应用程序(记事本、画图、文件浏览器、时钟和设置)等。
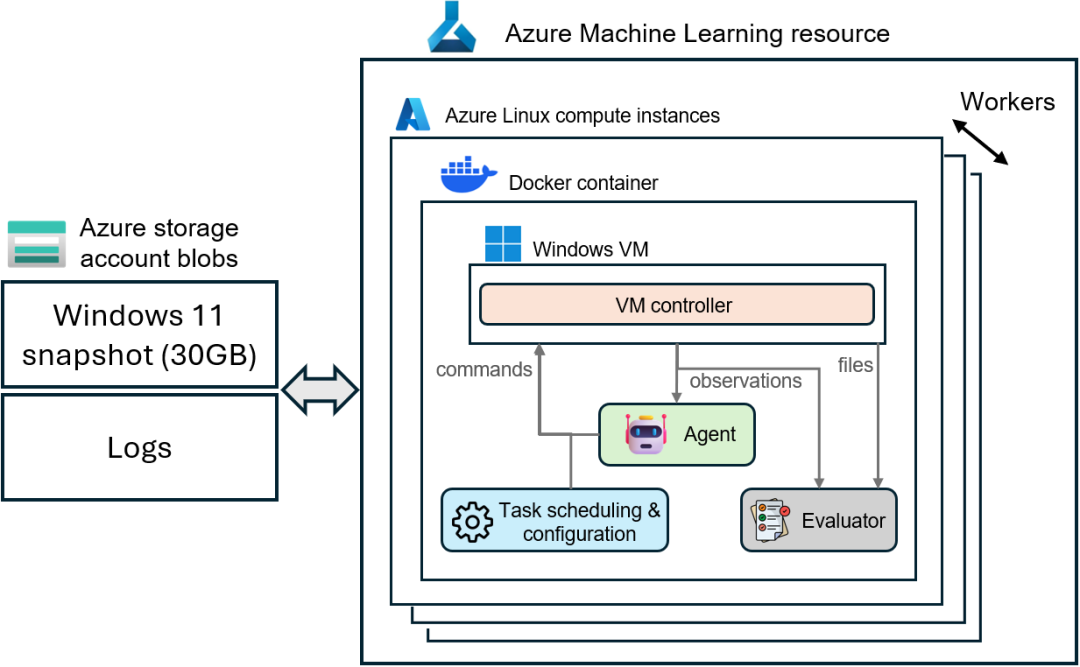
图 3 在 azure 云上部署 WAA
WAA 的另一个特点是支持云上并行测试。这样,测试数百个任务无需花费大量时间在本地串行,而是可以使用 Azure 云来并行部署数百个实验,从而将测试时间从几天缩短至几分钟。
使用 Windows Agent Arena 非常简单:你只需 clone 我们的代码,在本地简单测试,然后直接部署到云上。
目前的 Agent 能做什么?
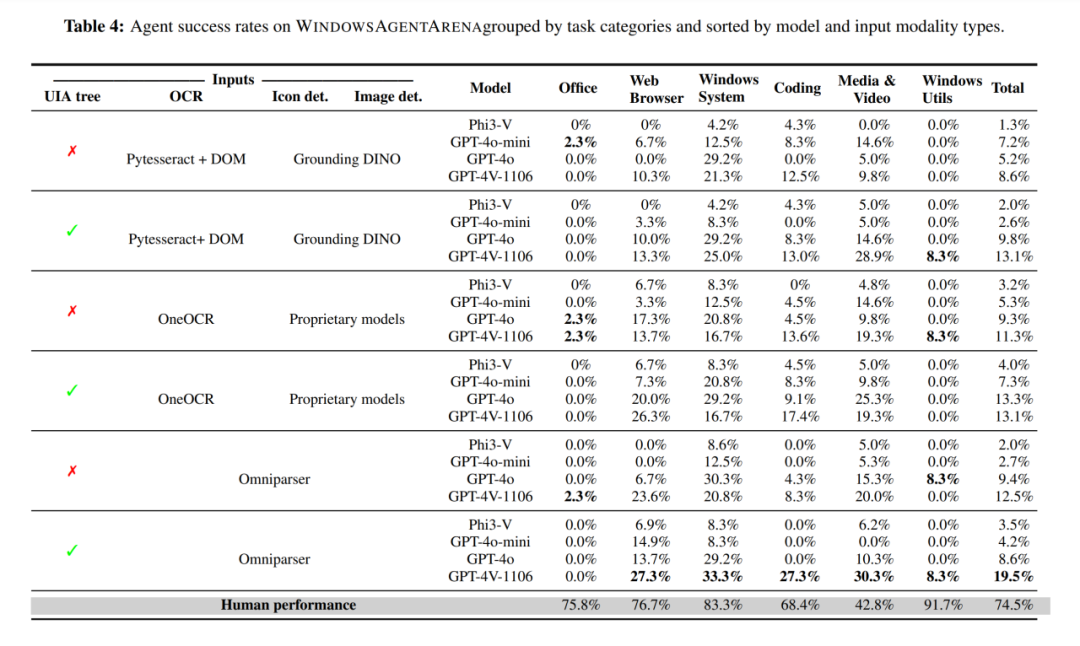
图 4 基于不同模型的 Agent 在 WAA 上表现
我们的技术报告对比了基于不同大模型的 Computer Agent 的能力。除了大模型之外,我们使用了小型的视觉模型,例如微软开发的 Omniparser 模型, OCR 等等来解析屏幕截图、 识别图标和图像区域。然后,我们将预处理的信息发送到 GPT-4V(或者 GPT-4O, Phi-3V),从而得到下一步在计算机上需要执行的命令。在我们测试的模型中,最好的 Agent 解决了 19.5% 的任务(任务部分完成没有得分);而一个人在没有外部帮助的情况下得分为 74.5%。我们发现各个任务类别之间的差异很大:大约三分之一的浏览器、设置和视频任务能被成功完成,而大部分 Office 任务都以失败告终。现阶段,Agents 仍然会有很多缺陷,例如我们也发现了由于在执行低级动作或推理时出错导致的情况。
成功案例
失败案例
当我们设计和改进在计算机上执行复杂任务的 AI Agent 时,符合伦理规范和负责任的 AI 使用至关重要。从一开始,我们的团队就意识到这些技术可能带来的潜在风险和挑战。
隐私和安全是最重要的关注点。当研究开发和测试这些模型时,我们必须确保 AI Agent 不参与任何形式的未经授权的访问或个人信息的信息泄露,从而最大限度地减少潜在的安全风险。我们相信,用户应该能够轻松地理解、指导和在必要时覆盖 AI 的行动。
当我们继续在这个充满机会与挑战的领域开发和探索,我们会始终致力于构建尊重用户隐私、促进公平并对社会产生积极影响的 AI 技术。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]