原文标题:时序=图像?无需微调,视觉MAE跨界比肩最强时序预测大模型
原文作者:机器之心
冷月清谈:
近期,来自浙江大学、道富科技和Salesforce的研究人员提出了一种名为VisionTS的时序预测框架,该框架基于视觉Masked Autoencoders(MAE)模型,无需时间序列数据微调,直接跨界比肩甚至超越了一众强大的时序预测基础模型,如Moirai和TimesFM等,证明了计算机视觉和时间序列这两个看似风马牛不相及的领域可能具有密切联系。
研究背景
近年来,预训练基础模型已经促进了自然语言处理(NLP)和计算机视觉(CV)领域的变革。这种趋势正在推动时间序列预测发生重大变化,从传统的“单数据集训练单模型”转向“通用预测”,即采用一个预训练模型来处理不同领域的预测任务。目前,训练能够通用预测的时序预测基础模型有两条主要研究路径。第一条路径是尝试把已经在文本数据上训练好的 LLM 应用于时间序列预测任务。然而,由于这两种数据模式之间存在显著差异,这一路径存在局限性。第二条路径是从零开始收集大量来自不同领域的时间序列大数据集,直接训练一个基础模型。然而,不同领域的时间序列数据之间在长度、频率、维度和语义上有很大差异,这限制了它们之间的迁移效果。
方法
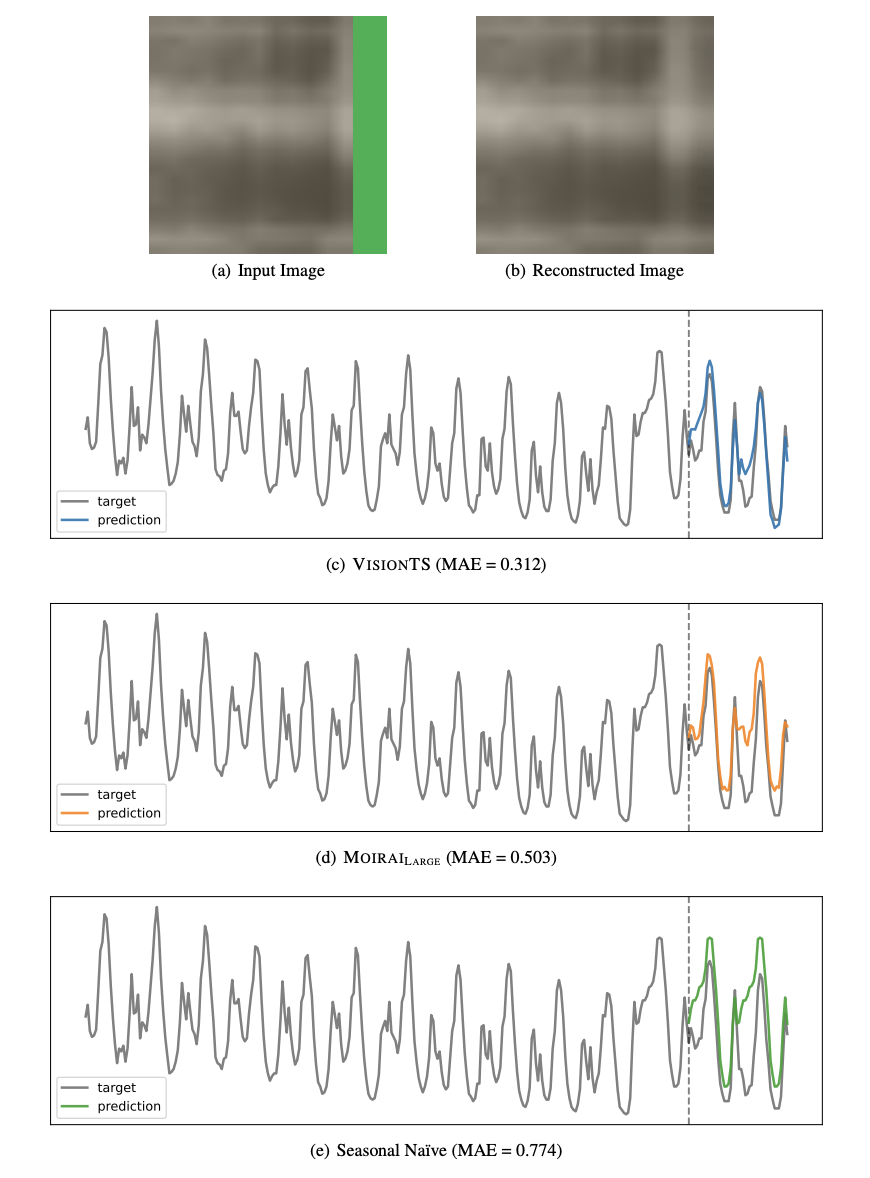
VisionTS基于提示学习的思想,将时间序列预测任务重构为MAE预训练使用的块级图像补全任务。具体来说,将时间序列的历史窗口转换为可见的图像块,预测窗口转换为被遮挡的图像块。通过一系列转换步骤,将时间序列数据渲染为适合MAE输入的灰度图像。然后利用MAE模型重建图像并提取预测窗口。
实验结果
测试结果显示,VisionTS在涵盖多个领域的35个基准数据集上表现出色,涉及时序预测的各种场景。在零样本情况下,能够比肩甚至超越 Moirai(一个在 27B 通用时序数据上训练的时序大模型),甚至超越了少样本训练的 LLM(TimeLLM 和 GPT4TS)以及其他常用的时序预测模型。这些结果显示,图像→时间序列的迁移能力要强于文本→时间序列,甚至与不同时序数据领域之间的相互迁移能力相当。
怜星夜思:
2、VisionTS 的优势和劣势是什么?
3、你觉得 VisionTS 在未来有哪些潜在应用场景?
原文内容
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]

-
论文题目:VisionTS: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters
-
论文地址:https://arxiv.org/abs/2408.17253
-
代码仓库:https://github.com/Keytoyze/VisionTS



测试结果显示,VisionTS 在涵盖多个领域的35个基准数据集上表现出色,涉及时序预测的各种场景。


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]