原文标题:一文读懂「腾讯云智算」:AI原生时代,我们需怎样的基础设施?
原文作者:AI前线
冷月清谈:
- 腾讯作为 AI 云底座的领导者,率先推出了面向未来发展的 AI 原生云计算超级底座“腾讯云智算”。
- 腾讯云智算具有同源同构、云原生、场景驱动三大特点,可为 AI 创新提供性能和性价比双重优势,承载海量数据处理和超大规模训练与推理任务。
- 腾讯云智算融合了腾讯云的优势产品方案,涵盖异构计算、智能高性能网络、AIGC 存储、AI 加速套件、向量数据库、私有化智算套件等,能够提供全面的 AI 计算能力。
- 腾讯云智算在模型训练、推理和应用方面取得了显著成果,获得了头部大模型厂商的首选认可,助力企业降低模型门槛和应用成本,加速 AIGC 应用落地。
- 腾讯云还推出了配套的技术解决方案,如 AI 推理加速套件 TACO、全栈自研 AIGC 存储服务、智能高性能网络 IHN 等,为 AI 基础设施建设和应用提供了强有力的支持。
互动讨论:
1. 在 AI 原生时代,企业如何选择适合自己的云计算基础设施?
2. 腾讯云智算在 AI 模型的训练和推理方面有哪些突出的优势?
3. 面对海量数据和不断增长的 AI 模型规模,如何构建高效稳定的 AI 存储系统?
怜星夜思:
2、腾讯云智算在 AI 模型的训练和推理方面有哪些突出的优势?
3、面对海量数据和不断增长的 AI 模型规模,如何构建高效稳定的 AI 存储系统?
原文内容

2024 年 9 月 6 日,腾讯全球数字生态大会落下帷幕。
此次大会主题为“智启新机,云驱增长”,风向非常清晰,即深度聚焦 AI、云计算等前沿技术带来的新机遇与技术融合之道、探索创新技术如何推动商业进化。
首日主论坛上,腾讯推出了三项面向未来的重要产品:性能更强、性价比更高的 MoE 模型腾讯混元 Turbo、集算 / 存 / 网 / 数一体的高性能智算底座(AI Infra)“腾讯云智算”、助力中小企业结合自身语料数据快速打造大模型应用的 RAG 解决方案。
其中最受行业关注的便是:腾讯云率先构建了基于 AI 原生应用驱动的新一代云基础设施“腾讯云智算”。
据介绍,“腾讯云智算”是业内首个“经 90% 大模型用户选择、产业深度实践、公私一体化”的 AI 原生云智算超级底座,在 AI 高性能计算、AI 高性能存储、AI 高性能网络、AI 加速套件、云原生智能调度编排、多模态 RAG 数据检索方面进行了系统性优化与创新,打破了算存网的“木桶”效应,为大模型产业发展提供性能 & 性价比双料领先的高效能智能算力,承载海量数据的处理、超大规模的训练与推理,进而加速 Gen AI 应用创新与落地。
随着大语言模型、语音模型、视频模型等领域的突破性进展不断涌现,Gartner 预测,到 2026 年,超过 80% 的企业将在生产环境中采用生成式 AI 的 API、模型,并部署启用生成式 AI 的应用。这些都预示了 AI 原生应用时代的全面到来。
但是,“我们应该如何看待 AI 原生与云的关系?AI 火了,云计算是否落伍了?”这是一年前腾讯云副总裁李力被媒体问到的一个问题。
“要回答这个问题,我们需要看云和AI的本质是什么。我觉得 AI 如果狭义看,应该是广义云的子集,因为它同样代表 IT 基础设施不可替代的一环,它能够让你的业务变得更好、更智能。我们做云有十几年了,这些云计算的经验都将与 AI 技术互补。”李力在此次生态大会的 AI 基础设施专场上回应道。

据介绍,腾讯云智算具有三个关键点:同源同构、云原生、场景驱动。一方面,腾讯云在多年的发展历程中持续坚持公有云、专有云、分布式云走统一的技术路线,代码一致,这些经验将在腾讯云智算中得到体现,而这也表明腾讯云的 AI 原生与云原生是同源同构的一体化演进;另一方面,腾讯云已经支撑腾讯集团自有业务大规模上云,完成了业界体量最大的云原生实践,腾讯云智算将继承腾讯在云原生上所有的生态体系并与 AI 深度融合,从而打造 AI 原生云;此外,过去十年,腾讯历经了 200 多万客户海量场景的验证,而这些“磨练”也都内化成了腾讯云智算的能力。
从具体能力上来看,腾讯云智算整合了腾讯云异构计算解决方案、智能高性能网络IHN解决方案、AIGC存储解决方案、AI加速套件TACO、向量数据库、私有化智算套件等腾讯云优势产品方案,能够为AI创新输出性能领先、多芯兼容、灵活部署的智算产品能力。
在部署方面,腾讯云智算非常灵活,既支持公有云、也支持私有云以及分布式云的部署。腾讯专有云 TCE 研发负责人王旻表示,不同客户对弹性、灵活性、数据隐私和自主可控的需求各不相同,智算基础设施也需要满足公有云和专有云等多种模式。同时,除了智算能力外,也会给私有化客户带来其他一些收益:全面安全合规、开放兼容,覆盖智算、通算、超算等多种场景的全栈智能解决方案,行业云能力,以及腾讯云完整运营 / 运维的产品与理念等。
在模型训练方面,腾讯云智算的千卡日均故障率降低到了 0.16,是业界水平的三分之一,并且一旦出现物理故障,平台会快速读取 Checkpoint 进行断点续算,写入时间仅需 10 秒,同时通过星脉网络,千卡集群训练的并行加速比可以做到 96%,通信时间缩短到 6%。故障自愈时间也降低到 5 分钟级,计算利用率显著提升。此外,通过软硬件技术能力的整合,腾讯云智算集群从机器上架到开始训练最快只需 1 天。
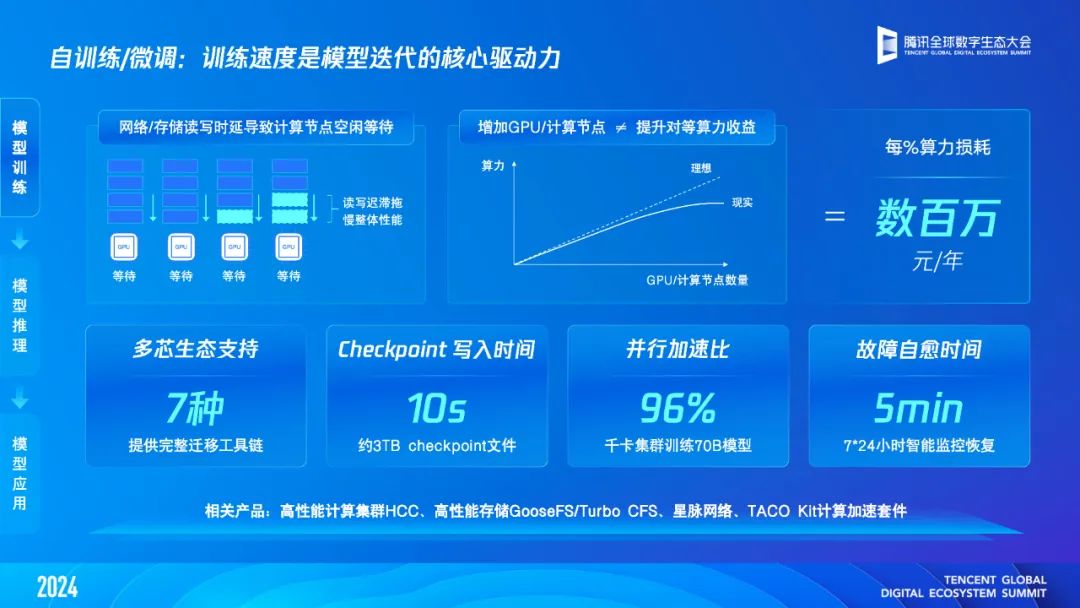
经测算,在 Llama2 7B、13B、34B、70B 多个规格大模型的训练上,腾讯云智算相比友商性能提升 19~30% 左右。
在模型推理方面,腾讯云在现场发布了全新自研推理实例:NPU 计算型 PTX2。据介绍,该实例单卡搭配 48GB 显存规格,能够最大化释放吞吐性能;支持判别式 AI、生成式 AI、广告推荐等多种场景,支持国内主流大模型推理,推理业务性价比提升 20~50%。
“我们在做推理的时候,广告推荐的场景和自然语言训练的模型场景对于单卡上的 CPU 和内存的要求是不一样的,语言模型的推理对 CPU 内存的要求并不高,广告推荐需要大量的 CPU 内存做前置的数据预处理,这个时候需要在单卡上搭配更多的 CPU 和内存,PTX2 这款实例可以一站式解决多场景的诉求。”宋丹丹举例道。
此外,为了帮助更多用户降低模型选型、推理、部署的门槛,腾讯云全新发布“HAI 社区”,该社区汇聚了全球丰富的 AI 资源,首期覆盖 300+ 大模型、CV、NLP 等镜像,提供极速下载、一键部署的功能。

在模型应用方面,据介绍,截至目前,腾讯云已经与猿辅导、小红书、快手、美团等消费级应用,以及元象、博世、Minnimax、智谱等产业级应用展开了深度合作,在智能运维、技术问答、代码生成、售前售后等多个领域取得了显著的进展,成为了“头部大模型厂商的首选”智算底座。
毋庸置疑,腾讯云智算是集合了腾讯云十多年来的内外部技术经验与场景实践的、面向 AI 时代的一体化智算底座,是腾讯云在云计算与 AI 技术等方面多维能力的集合体。
在 AI 基础设施专题论坛上,腾讯云虚拟化产品总经理陈立东分享了腾讯云面向大模型推理推出的加速套件——TACO。

TACO 是腾讯云推出的一套异构计算加速软件服务,旨在通过软硬件协同优化,提升 AI 模型的推理效率并降低成本。TACO 包含多个组件,其中 TACO-LLM 专注于大语言模型的推理加速,而 TACO-DiT 则针对图文生成场景进行优化。
技术实现方面,TACO-LLM 主要通过以下方式加速大模型推理并降低成本:
-
显存和内存管理优化:TACO-LLM 采用动态内存管理和并行推理技术,减少显存占用,提高内存使用效率。
-
流水线并行、张量并行及序列并行:通过流水线并行技术,TACO-LLM 能够将大模型推理过程分为多个阶段,实现高效异步执行,减少 GPU 空闲时间。张量并行技术则将模型变量分散到多个设备上并行计算,进一步提升效率。序列并行则针对长序列场景,将长输入拆分到不同 GPU 上并行计算,帮助大大降低首字延迟。
-
连续批处理:与传统批处理不同,连续批处理允许模型在处理完当前迭代后立即返回结果,而不是等待整个批次完成,从而减少空闲时间,提高资源利用率。
-
Paged Attention 技术:借鉴操作系统中的分页概念,将 KV 缓存划分为块,实现在非连续内存上的逻辑连续,提高显存利用效率。
-
模型量化:将模型权重从 32 位浮点数转换为 8 位整数,减少存储需求和带宽需求,同时提升计算速度。
效能方面,陈立东表示,以常用的 Llama 模型为例,通过 TACO-LLM 的加速,可以做到百万 Token 推理成本低于 0.5 美元,相比于开源的版本,整个运营成本可以降低超过一倍。
TACO-DiT 则运用了并行加速技术来支持混元 DiT 等场景,能够显著减少图片生成的时间。陈立东指出,随着业务需求的演进,从传统的 U-Net 架构过渡到 DiT 架构,对图像生成的精度要求也随之提高,每次推理所需的数据量也变得更大。尤其是在文本生成视频的场景中,序列长度的增加是指数级的。例如,使用 Flux 生成 1K 分辨率的图片仅仅需要 3 秒,而生成 2K 分辨率的图片则需要超过 70 秒,文生视频任务更是会导致计算量剧增,目前业界面临的挑战是如何通过多卡推理来减少业务延迟。为了应对这一挑战,我们开发了 TACO-DiT 并行加速技术。得益于这项技术,混合元素 DiT 生成图像的服务延迟从 45 秒大幅降低至 12 秒,显著提高了服务质量。
此外,TACO 还包括面向传统 AI 的 qGPU 产品,通过 GPU 算力和显存的严格切分,提升 GPU 利用率,降低运营成本等等。
本质上说,TACO 提供的是一项开箱即用的计算加速服务,无需复杂的环境配置,支持多种硬件和 AI 框架,兼容多种芯片,并提供统一的加速入口。通过这些技术,TACO 能够显著提高 AI 模型的推理效率,降低运营成本,从而帮助企业实现降本增效。
除了 AI 推理的算力,网络带宽对于 AI 大模型的训推、落地同样至关重要。
随着越来越多的互联网厂商、工业制造厂商躬身入局,市场对 AI 算力的需求呈现出井喷式的增长,AI 基础设施也在高速发展、迭代。数据显示,从 2020 年至 2024 年,四年间推理算力增加 32 倍,训练算力增加 16 倍,网络带宽增加 4 倍。
“实际上,从增长趋势来看,带宽的增长和算力的增长是不太匹配的。” 腾讯云网络 VPC 产品负责人王营表示。

同时,随着大模型参数的迅速增长,AI 集群的规模也在迅速攀升,集群规模也从百卡、千卡、万卡逐步提升至十万卡,各大芯片厂商持续增加在 GPU 上的投入和布局异构算力组网成为常态。。同时,在 AI 大规模集群场景,网络通信带宽、网络延时、网络丢包和网络故障等均会影响 GPU 算力性能发挥。
“我们可以得出一个结论:AI 集群算力的发挥严重依赖网络的性能,大集群不等于大算力,需要有更好的网络解决方案配合才能发挥出 AI 集群算力的性能。”王营表示。
现场,腾讯云高性能网络IHN——腾讯云【智能】高性能网络IH。据介绍,腾讯云高性能网络 IHN 是基于支撑腾讯万卡集群的星脉网络技术打造具有的卓越性能与创新价值的商业化产品。
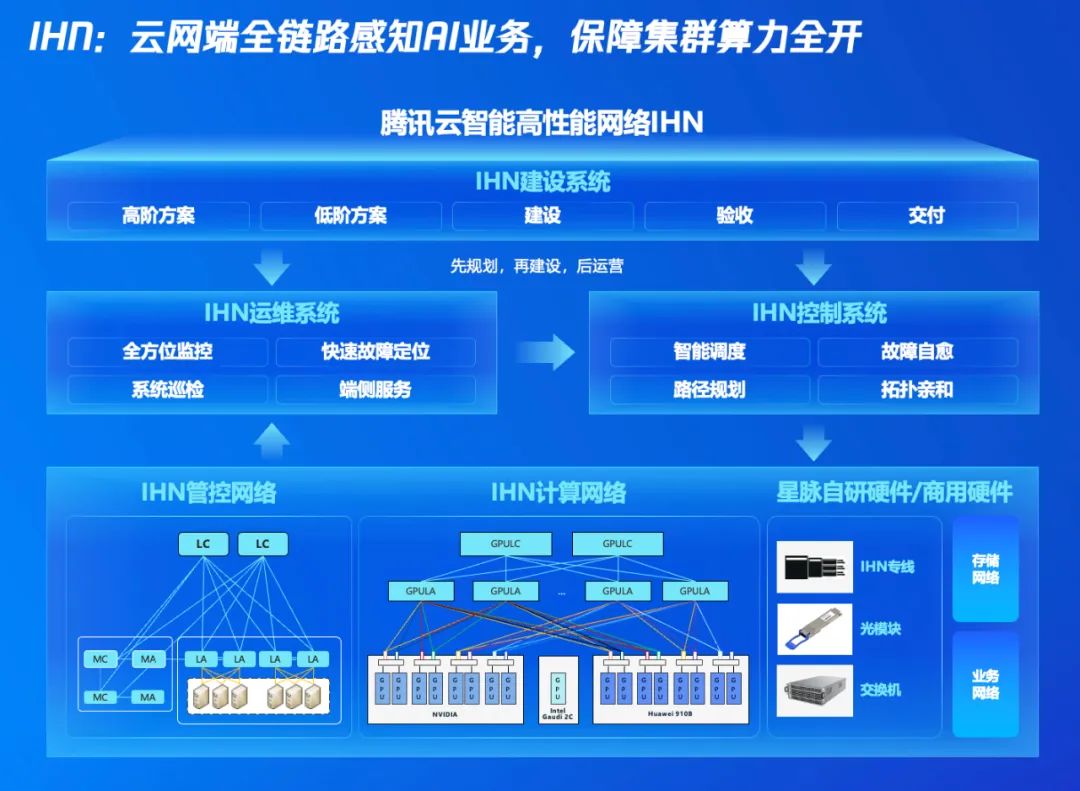
IHN 的主要特点包括:
-
大规模、超高速网络:单集群支持万卡规模,单机支持 3.2T 大带宽,通信占比低至 6%,训练效率提升 20%。
-
全局监控,高效运营:360 度立体监控,毫秒级调度,万卡集群训练无卡顿,慢节点分钟级定位。
-
智算套件解决方案:支持多 GPU 异构接入和云上多产品协同为 AI 用户提供“算存网”一体能力。
-
灵活部署和交付:一站式交付,多产品深度协同,支持公 / 私有云交付形态
通过这些特性,IHN 能够帮助企业大幅提升 AI 模型训练和推理的性能,加速 AI 技术的应用和创新。
面向未来,王营表示,下一代 IHN 产品将推出单网口支持 800G、整机 102.4T 容量的自研交换机,具备单 GPU 直出 3.2T 超节点特性,并支持在网计算能力,为客户提供更高带宽,更强性能的 AI 网络方案,成为企业拥抱智算时代的重要帮手。
OpenAI 此前的研究表明,大模型的训练误差会随着数据量的增加而减少。这使得模型的参数量和所需的数据规模达到了前所未有的高度。
数据模型决定数据的精度,而存储性能则影响算力的效率,大模型在深刻改变存储产业格局的同时,也产生了新的问题。随着数据与格式的日益多样化、数据量的剧增以及模型规模的扩大,存储系统在成本、性能、协议、支持以及安全合规等方面,均面临着严峻的挑战。
基于此,腾讯云将其在存储领域的优势经验(腾讯云存储获沙利文「2023 年中国云存储市场报告」评测创新与增长指数双第一)融入 AI 时代的场景需求,推出了面向 AIGC 的全栈自研的存储服务。
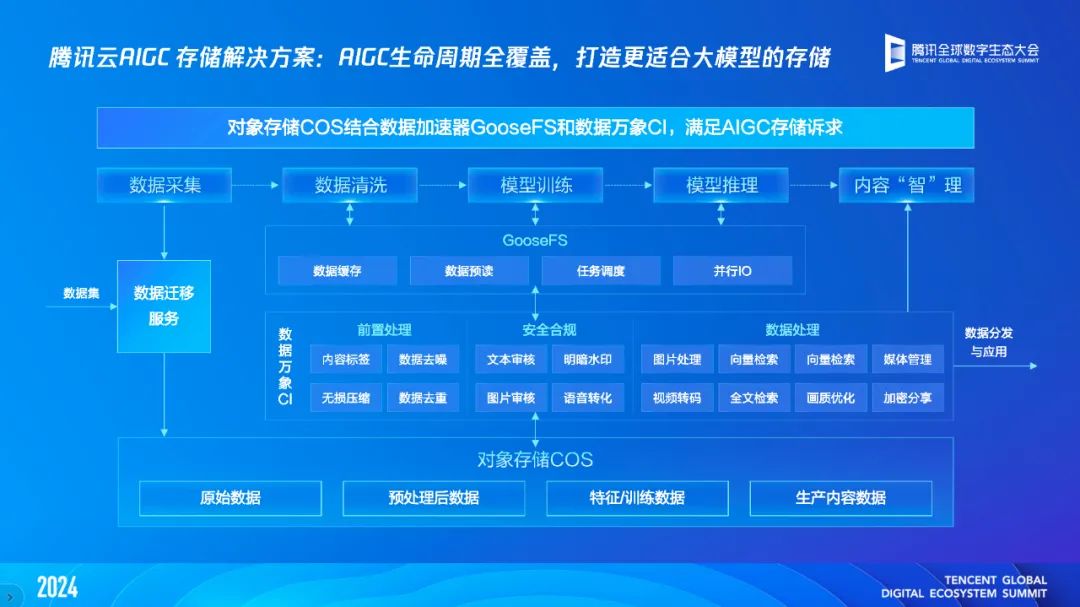
在存储底座方面, 腾讯云 AIGC 存储服务包括对象存储 COS 和高性能并行文件存储 CFS Turbo,组成了国内首个实现存储引擎全面自研的云存储解决方案;存储性能方面, 腾讯云自研的并行文件存储 CFS Turbo 能够提供 TiB/s 级别的总读写吞吐和百万 OPS 的每秒元数据性能,支持快速 CheckPoint 写入,解决了训练文件读写瓶颈等问题;数据湖加速器 GooseFS 支持 Tbps 级别的吞吐、亚毫秒级延迟、和百万级的 IOPS,有效提升存储性能。据介绍,采用腾讯云 AIGC 云存储解决方案,大模型的数据清洗和训练效率可提升一倍,所需时间缩短一半;数据管理方面, 数据万象 CI 提供全方位的数据处理服务,包含图片处理、AIGC 内容审核、智能数据检索 MetaInsight 等功能,让数据管理从治理走向智理。
腾讯云存储产品总经理陈峥介绍称,截至目前,腾讯云 AIGC 云存储解决方案已被 80% 的头部大模型企业采用,包括百川智能、智谱 AI、元象科技等。
另外,会议现场,腾讯专有云 TCE 研发负责人王旻、腾讯云分布式云产品负责人杨志华还围绕面向专有云的腾讯云智算套件、基于分布式云的专属安全 / 弹性便捷本地智能云平台等内容展开了分享。为金融、政府等强合规场景或者分布式场景下的 AIGC 落地提供了完备的场景服务支持。
会议最后,元象大模型产品中心总监张玥、广州尚航信息科技股份有限公司 CIO 曾越明分享了他们在文娱、IDC 领域的实践。在业务场景的 AIGC 探索中,腾讯云智算为他们提供了有力的支持。
透过此次的腾讯全球数字生态大会,不难看出,从混元大模型的能力升级,到腾讯云智算、大模型 RAG 解决方案,一个更加开放、协作、全面的腾讯 AI 生态全景图徐徐展开,将为客户提供包括基础设施、工具、平台在内的全方位支持。
腾讯云智算的发布,标志着腾讯在构建高效、灵活、稳定、安全的 AI 基础设施方面迈出了重要一步。不仅展示了腾讯在 AI 领域的技术实力,也反映了其对市场需求的深刻理解。随着这些技术的逐步落地,预计将为 AI 应用的开发和部署提供更加坚实的基础。当然,我们也期待这些技术在更广泛的应用场景中得到应用、验证并持续进化,从而推动行业技术的发展。

AI 应用开发、大模型基础设施与算力优化、出海合规与大模型安全、云原生工程、演进式架构、线上可靠性、新技术浪潮下的大前端…… 不得不说,QCon 还是太全面了。现在报名可以享受 9 折优惠,详情请联系票务经理 17310043226 咨询。

今日荐文
