原文标题:KDD2024最佳学生论文解读,中科大、华为诺亚:序列推荐新范式DR4SR
原文作者:机器之心
冷月清谈:
在中国科学技术大学和华为诺亚方舟实验室的研究人员的共同努力下,一种名为 DR4SR 的新范式横空出世,旨在解决序列推荐系统中数据质量问题。数据重生成,顾名思义,就是利用固定模型从原始数据中生成高质量数据集。
预训练任务,先学模式再生成
如何让模型学会数据重生成?研究团队自创了一个预训练任务:从原始数据中提取转移模式,再让重生成器学习如何把序列映射到模式上。
多样性增强,一个序列对应多个模式
现实中,一个序列往往对应多个模式。为了解决一对多映射问题,研究团队在重生成器中加入了多样性增强模块,让模型在生成模式时还能考虑序列的影响。
模型感知,定制化数据更贴心
不同的目标模型有不同的偏好。DR4SR+ 应运而生,它可以感知目标模型的特性,定制化地生成更适合该模型的数据集。
实验验证,效果杠杠的
研究人员用各种目标模型对 DR4SR 和 DR4SR+ 进行了测试,结果表明:DR4SR 生成的通用数据集表现优异;不同的目标模型确实偏好不同的数据集;数据重生成不仅仅是去噪。
怜星夜思:
2、DR4SR+ 的模型感知特性是如何实现的?它能感知哪些方面?
3、DR4SR 在哪些实际应用场景中具有潜力?
原文内容
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]
8 月 25 日 - 29 日在西班牙巴塞罗那召开的第 30 届 ACM 知识发现与数据挖掘大会 (KDD2024) 上,中国科学技术大学认知智能全国重点实验室陈恩红教授、IEEE Fellow,和华为诺亚联合发表的论文 “Dataset Regeneration for Sequential Recommendation”,获 2024 年大会 Research Track 唯一最佳学生论文奖。论文第一作者为中科大认知智能全国重点实验室陈恩红教授,连德富教授,与王皓特任副研究员共同指导的博士生尹铭佳同学,华为诺亚刘勇、郭威研究员也参与了论文的相关工作。这是自 KDD 于 2004 年设立该奖项以来,陈恩红教授团队的学生第二次荣获该奖项。

-
论文链接: https://arxiv.org/abs/2405.17795
-
代码链接: https://github.com/USTC-StarTeam/DR4SR
 的映射涉及两个隐含的映射:
的映射涉及两个隐含的映射: ,因此这一过程具有挑战性。为此,研究团队探索了开发一个显式表示
,因此这一过程具有挑战性。为此,研究团队探索了开发一个显式表示 相对更容易学习。因此,他们的主要关注点是学习一个有效的
相对更容易学习。因此,他们的主要关注点是学习一个有效的



 投影到 K 个不同的向量空间中,即
投影到 K 个不同的向量空间中,即  。他们将
。他们将 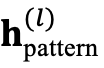 压缩成一个概率向量:
压缩成一个概率向量:





-
DR4SR 能够重生成一个信息丰富且具有普遍适用性的数据集
-
不同的目标模型偏好不同的数据集
-
去噪只是数据重生成问题的一个子集

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]