原文标题:珊瑚书出版!从零开始,万行代码自制向量数据库
原文作者:图灵编辑部
冷月清谈:
《从零构建向量数据库》是首本介绍向量数据库的中文原创图书,因封面上的珊瑚图案而得名。作者罗云是中国工程院外籍院士王江舟等多位领域专家推荐。
本书特色
- 实操导向,从写 Hello World! 开始,用 10000 行代码带你真正学会写向量数据库。
- 内容扎根实战,涵盖向量数据库的方方面面,图文并茂,通俗易懂。
- 专业背景,作者为腾讯云向量数据库负责人,带领团队积累了丰富的实战经验。
适合读者
- 对向量数据库感兴趣,想深入了解其源码级别构建过程的初级程序员。
- 对数据库领域感兴趣,想了解分布式向量数据库核心知识的开发者。
- 对 AI 应用开发感兴趣,想了解向量数据管理的 AI 应用开发者。
- AI 应用开发或数据库领域的专家,希望发现改进之处,推动行业发展的专业人士。
怜星夜思:
2、作者在书中提到「从零构建并不是说啥都得自己写」,这句话具体是什么意思?
3、作者在文末提到了本书代码免费提供,请问可以在哪里下载?
原文内容

-
一方面,简单好学——内容务实、扎根实战,从写 Hello World! 开始,用10000 行代码带大家真正学会写向量数据库;
-
另一方面,作者背景非常专业。罗云为腾讯云向量数据库负责人,带领团队积累了丰富的一线经验(国内最早搞向量数据库的团队之一)。
2.【生动】10次版本迭代/10000行代码;27张表/41幅图/22个思维导图轻松学
3.【专业】作者罗云是腾讯云向量数据库负责人,带领团队积累了丰富的一线经验
4.【热门】自制成功立马投入实践,带大家结合RAG实现个人知识库等大模型应用
5.【简单】附赠随书代码,随学随查——原来,构建向量数据库如此简单!

当然,我们反复强调的从零构建并不是说啥都得自己写,毕竟向量数据库涉及的功能太多了,有很多开源项目已经封装好了我们需要的功能,这时候无须自己编写代码,直接引用开源库来实现即可。下表列出了本书引用的开源库及许可协议。
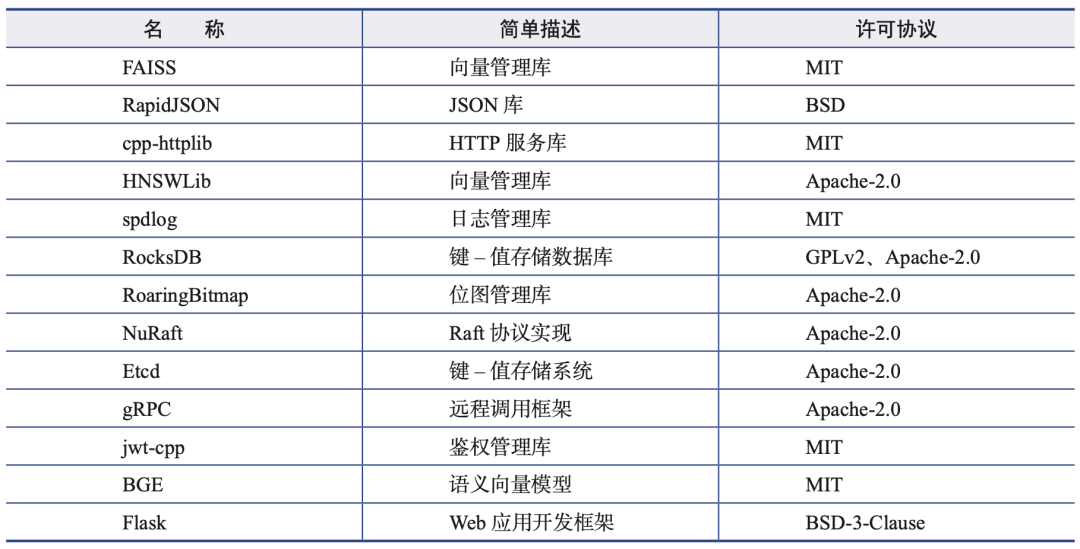
(一句话,该借的借,该造的造)
本书是一本实战类图书,也涉及简单的原理解析,书中的技术点都是初级程序员就可以理解的。如果你完全不了解编程,建议先打好编程基础,毕竟书里有不少需要你动手操作的源码。
-
如果你对向量数据库感兴趣,想深入了解向量数据库源码级别的构建过程,本书将教你从零打造一款分布式向量数据库。内容涉及:如何从单机数据库引擎开始构建索引系统,如何增强系统的故障恢复能力,以及如何实现数据库的分布式和集群运作,包括数据复制、流量调度和元数据管理等核心技术。
-
如果你对数据库领域感兴趣,想深入了解数据库源码级别的构建过程,本书同样适合你阅读——分布式向量数据库的完整构建过程涵盖了这一领域的核心知识。
-
如果你对 AI 应用开发感兴趣,想了解 AI 应用背后的向量数据是如何生成和管理的,本书将介绍向量数据与大模型的关系,并带你学习向量数据库查询的整个流程。这将帮助你更好地结合向量数据库优化 AI 应用,更新知识,更有效地应对 AI 应用落地过程中的挑战。
-
如果你是 AI 应用开发专家或数据库领域的专家,希望帮助本书发现改进之处,推动行业发展,本书也值得一读。阅读本书可能会激发你更多有价值的思考。向量数据库是一个较新的领域,更多的信息共享无疑会促进这一领域的进步。
4. 罗云其人

-
一站式 Serverless开发平台(小程序云开发)
-
TencentDB for Redis/MongoDB/KeeWiDB、Tencent Cloud VectorDB等数据库产品
-
腾讯云数据传输服务(DTS)、数据库智能管家(DBbrain)等多款数据采集和智能化应用平台
刘知远 | 王昊奋 | 盖国强 | 杨成虎
联 袂 推 荐
本书是罗云及其团队在AI领域探索的智慧结晶。它不仅深入揭示了向量数据库的工作原理,更提供了丰富的场景案例和实践启发。无论是AI技术的探索者,还是AI应用的创新者,都能从这本书中获得宝贵的灵感和指导。
——王江舟,中国工程院外籍院士
罗云是云计算行业早期的从业者和资深专家,在数据库、网络和分布式系统方面具有丰富的经验。本书从实践出发,深入浅出地讲解了如何打造高性能向量数据库,推荐大家阅读。
——刘颖,腾讯云副总裁
AI的发展呼唤多模态数据的统一表征和管理,向量数据库应运而生,是数据库大家族的新宠。本书深入浅出地介绍其基本概念,从零开始、逐步深入、重视实战,是学习向量数据库很好的参考书!
——杜小勇,中国人民大学信息学院教授、教育部数据工程与知识工程重点实验室主任
本书汇集了罗云以及腾讯云数据库团队多年服务于腾讯集团及其外部客户的丰富经验。书中内容浅显易懂,非常适合对向量数据库技术感兴趣的技术人员阅读。
——李国良,清华大学教授、IEEE Fellow
在“AI平民化”浪潮中,向量数据库作为新兴技术,正迅速成为AI应用的基石。本书以其深入浅出的讲解和实战导向的内容,填补了市场空白。推荐数据库和AI相关领域的从业者阅读。
——刘知远,清华大学副教授
本书不光理论与实践并重,更是一部揭示未来数据管理方向的重要指南。如果你希望在AI时代站在技术前沿,掌握构建和应用向量数据库的核心技能,那么本书无疑是你不可或缺的良师益友。
——王昊奋,同济大学特聘研究员、OpenKG(中文开放知识图谱联盟)发起人
罗云及其团队在向量检索领域探索多年,积累了诸多先行者的宝贵经验。本书是罗云对向量数据库深刻理解和洞察的系统体现,填补了向量数据库图书的空白。相信所有读者通过动手躬行,一定能够从无到有地构建向量数据库,并真正理解其本质。
——盖国强,云和恩墨创始人、鲲鹏MVP(最有价值专家)
本书既包含向量技术理论,也有分布式数据库的实践经验,同时也阐述了相关的应用场景,不仅适合数据库领域的专业人士阅读,也适合对AI技术感兴趣的朋友参考。
——杨成虎,北京枫清科技联合创始人 & CTO
扫下面这个图的
